
正規化(Normalization)

正規化(Normalization)とは、数学、統計学、機械学習において、データのスケールを一定の範囲や分布に調整する処理を指します。これにより、異なるスケールのデータを比較しやすくしたり、機械学習アルゴリズムの性能を向上させたりすることができます。主に以下の2つの方法が広く用いられています。
1. Min-Max Normalization
この方法は、データを0から1の範囲にスケーリングします。具体的には、各データ点から最小値を引き、その結果を最大値と最小値の差で割ることで行われます。式で表すと、正規化された値 x′ は以下のように計算されます。
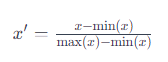
ここで、x は元のデータ点、min(x) はデータセットの最小値、max(x) はデータセットの最大値です。この処理により、データセットの最小値は0に、最大値は1に変換されます。
2. Z-score Normalization (Standardization)
Z-score normalization(または標準化)は、データの平均を0、分散(標準偏差)を1に調整する方法です。各データ点からデータセットの平均を引き、その結果をデータセットの標準偏差で割ることで行われます。式で表すと、正規化された値 z は以下のように計算されます。

ここで、x は元のデータ点、μ はデータセットの平均値、σ はデータセットの標準偏差です。この方法により、データセットは標準正規分布に従うように変換されます。
Batch Normalization
Batch Normalizationは、ネットワークの各レイヤーにおいて、ミニバッチごとにインプットの正規化を行う手法です。これは、インプットだけでなく、各レイヤーのアクティベーションに対しても適用されます。ミニバッチの平均と分散を使用して正規化を行い、学習プロセスを安定させ、高速化します。Batch Normalizationは、学習が安定し、初期値やパラメータのスケールに依存する度合いが低減し、より高い学習率を設定できるため、効率的な学習が可能になります。また、過学習を防ぐためのドロップアウトなどの正則化技術の必要性を減らすことができます。
ミニバッチとは?
想像してみてください、あなたが教室で先生から一度に全員に教える代わりに、少人数のグループに分けてそれぞれに指導するとします。このとき、各グループが「ミニバッチ」に相当します。機械学習では、大量のデータを一度に処理するのではなく、小さなグループ(ミニバッチ)に分けて順番に処理していきます。これにより、学習が効率的になり、計算資源を節約できます。
レイヤーとは?
機械学習のモデルを、学校の各クラスや段階と考えてみてください。生徒(データ)が学校(モデル)を通過するとき、彼らはクラス(レイヤー)からクラスへと移動します。各クラスでは、生徒は新しいことを学び(データが変換され)、最終的に卒業(予測を出力)します。機械学習モデルの「レイヤー」は、データが通過し変換される各段階を指します。
Batch Normalizationとは?
バッチ正規化は、学校で生徒たちが各クラスを移動する際に、彼らが最適な状態であることを確保するようなものです。具体的には、生徒たち(データ)が次のクラス(レイヤー)に移動する前に、彼ら全員が同じ水準にいるように調整します。これは、生徒たちの成績があまりにもバラバラだと、教師が効果的に教えるのが難しくなるのと同じ原理です。
バッチ正規化は、各ミニバッチ内のデータが、平均が0、分散が1になるように調整します。つまり、データが一定の範囲内に収まるように「正規化」されます。これにより、モデルの各レイヤーを通過するデータが安定し、学習がスムーズに進みやすくなります。
効果としては、
学習が安定し、速くなる。
モデルがより高い学習率を使えるようになる。
ドロップアウトなどの他の技術をあまり使わなくても良い状態を作り出すことができる。
簡単に言えば、バッチ正規化は学習プロセスをより効率的で安定したものにするためのテクニックです。
Layer Normalization
Layer Normalization レイヤー正規化とは?
レイヤー正規化は、機械学習で使用される一種の技術で、データのスケールを一定の範囲内に調整する方法です。特に、長いリストや文章など、長さが変わるデータ(可変長の系列データ)を扱うモデルで役立ちます。この技術は、各データ点(サンプル)内でデータの平均と分散を調整し、データ全体を均一なスケールに正規化します。
なぜレイヤー正規化が必要か?
想像してみてください、あなたが一つのバスケットから別のバスケットにりんごを移動させるとします。りんごのサイズがバラバラだと、どれが重くて、どれが軽いのか予測が難しくなります。でも、もしりんごのサイズをある程度統一できれば、移動作業がスムーズになります。レイヤー正規化も同じで、機械学習モデルがデータを「扱いやすい」形にするために使います。
レイヤー正規化の特徴
サンプル単位での正規化:各データポイント(サンプル)内で正規化を行い、データ間での正規化は行いません。これにより、各サンプルがモデルにとって均一に扱いやすくなります。
可変長データに適している:文章や音声など、長さが異なるデータを扱う場合に特に有効です。
オンライン学習に適している:データを次々とモデルに供給するような学習方法(オンライン学習)にも適しています。
レイヤー正規化の応用
レイヤー正規化は、自然言語処理(NLP)でよく使用されます。例えば、文章を理解するモデルや、画像を認識するモデルなど、さまざまな場面で役立てられています。特に、Transformerモデル(大規模言語モデルのGPTやBERT、画像認識のViTなど)で広く使用されています。
レイヤー正規化のまとめ
レイヤー正規化は、機械学習モデルがデータを均一なスケールで扱えるようにするための技術です。これにより、モデルの学習がスムーズになり、さまざまなタイプのデータをより効率的に処理できるようになります。特に、長さが異なる文章や音声データを扱う場合や、リアルタイムでデータを学習する必要がある場合に有効です。
レイヤー(層)について
ディープニューラルネットワーク(DNN)の基本的な構成要素である「層(layers)」について、もっと詳しく説明します。DNNは、異なる種類の層を組み合わせることで構築されます。これらの層は、ネットワーク内でデータが処理される方法を決定します。
層の役割と種類
入力層
DNNの最初の層で、入力データを受け取ります。
例えば、画像データの場合はピクセル値、テキストデータの場合は単語のベクトル表現などが入力されます。
中間層(隠れ層)
入力層と出力層の間にある層で、データの特徴を抽出します。
主に全結合層(Dense Layer)や畳み込み層(Convolutional Layer)、再帰層(Recurrent Layer)などがあります。
「全結合層」は、前の層のすべてのニューロンからの入力を受け取り、それぞれのニューロンが独自の重みを持ちます。
「畳み込み層」は、主に画像処理で使用され、画像から特徴を抽出するのに適しています。
「再帰層」は、時系列データや文章などの連続したデータを処理するのに適しています。
出力層
ネットワークの最終層で、タスクの目的に応じた形式でデータを出力します。
分類問題では、softmax関数を用いて、各クラスに属する確率を出力します。
活性化関数
各層の出力に適用される関数で、ニューラルネットワークに非線形性をもたらします。
例えば、ReLU(Rectified Linear Unit)、Sigmoid、Tanhなどがあります。
活性化関数は、層の一種として扱うこともでき、データの変換やフィルタリングに役立ちます。
層の組み合わせ
DNNを構築する際には、これらの層を組み合わせて任意のグラフ構造を作ります。ネットワークの設計では、どのように層を積み重ねるかが重要で、タスクの性質や入力データの種類に応じて最適な構造を選択します。例えば、画像認識タスクでは畳み込み層が主に使用され、自然言語処理では再帰層や最近ではTransformer層が用いられます。
層を通じてデータがどのように変換され、最終的な予測や分類が行われるかを理解することが、ディープラーニングの基礎を学ぶ上で重要です。
レイヤー正規化(Layer Normalization)は1サンプルごとに独立して行われます。これはレイヤー正規化の特徴的な点であり、バッチ正規化との大きな違いの一つです。
バッチ正規化では、ミニバッチ内のすべてのサンプルにわたって平均と分散を計算し、それを使って各サンプルを正規化します。これに対して、レイヤー正規化は各サンプル内でのみ平均と分散を計算し、そのサンプルのみを正規化します。つまり、レイヤー正規化はバッチサイズに依存せず、各サンプルが独立して処理されるため、可変長の系列データや小さなバッチサイズでの学習に適しています。
この性質により、レイヤー正規化は系列モデルやオンライン学習において特に有効であり、バッチサイズの変動がモデルの性能に影響を与えることなく、一定の正規化効果を期待できます。また、レイヤーごとに独立して正規化を行うことで、深いネットワークにおける内部共変量シフトを軽減し、学習の安定化と加速化に貢献します。
もう少し具体的に バッチ正規化とレイヤー正規化の違い説明
バッチ正規化とレイヤー正規化の違いを理解するために、これらがどのようにデータを正規化するかに注目することが重要です。確かに、どちらの手法も各層の入力を正規化するという点では共通していますが、正規化を行う「範囲」や「単位」に大きな違いがあります。
バッチ正規化の基本概念
バッチ正規化では、一度に処理されるデータのグループ(バッチ)全体にわたって平均と分散を計算し、その統計を使用して各サンプルを正規化します。つまり、バッチ内のすべてのサンプルは、バッチ全体の平均と分散に基づいて正規化されます。これは、大きなバッチサイズでは効果的ですが、バッチサイズが小さい場合やオンライン学習のように一度に1サンプルずつ処理する場合には、バッチ正規化の利点が得られにくくなります。これは、小さいバッチサイズではバッチ全体の統計が不安定になりがちで、それによって正規化の効果が落ちるためです。
レイヤー正規化の基本概念
レイヤー正規化は、バッチ正規化と異なり、バッチサイズに依存しません。レイヤー正規化では「サンプルごと」に正規化を行います。ここでいう「サンプルごと」とは、各データポイントまたは入力例を個別に、その内部の統計(その1サンプル内での平均と分散)に基づいて正規化することを意味します。つまり、各入力サンプルが独立して自身の平均と分散に基づいて正規化されます。これにより、バッチサイズに関わらず一貫した正規化が可能となり、特にバッチサイズが1の場合や、可変長のデータを扱う際にも安定した学習が期待できます。
なぜレイヤー正規化が小さいバッチサイズでも効果的か
レイヤー正規化が小さいバッチサイズで効果的な理由は、それがバッチサイズに依存しないからです。各サンプルが独立して正規化されるため、バッチサイズが小さくても、大きくても、正規化の質が変わりません。これに対して、バッチ正規化はバッチサイズによって正規化の質が左右される可能性があります。したがって、バッチサイズが1でも、各サンプルはその独自の統計に基づいて適切に正規化されるため、レイヤー正規化は小さいバッチサイズやオンライン学習に適していると言えます。
内部共変量シフト
深いネットワークにおける「内部共変量シフト(Internal Covariate Shift)」とは、ネットワークの学習過程で、各層の入力分布が変化する現象を指します。具体的には、ネットワークを構成する層が多くなるほど、上層に向かうにつれて、下層の重みの微小な変更が層を通じて伝播し、結果として上層の入力分布に大きな変化をもたらします。この変化は、学習を不安定にし、収束を遅らせる原因となり得ます。
内部共変量シフトが問題となる理由
学習率の制限: 各層の入力分布が絶えず変化すると、学習率を高く設定すると学習が不安定になりがちです。そのため、学習率を低く設定して慎重に学習を進める必要があり、これが学習プロセスを遅くします。
勾配消失・爆発: 層間でのデータの分布変化が大きいと、勾配消失や勾配爆発が発生しやすくなります。これは、バックプロパゲーション時に勾配が非常に小さくなったり、非常に大きくなったりすることで、重みの更新が適切に行われなくなる現象です。
収束時間の増加: 学習プロセスの不安定さと学習率の低下は、モデルが最適なパラメータに収束するまでの時間を大幅に延長します。
内部共変量シフトへの対策
内部共変量シフトを軽減するために、いくつかのテクニックが提案されています。
バッチ正規化(Batch Normalization): 各層の入力を正規化することで、層間の入力分布の変化を小さく保ち、学習を安定化させます。
レイヤー正規化(Layer Normalization): バッチ正規化と同様に、各層の入力を正規化しますが、こちらはサンプルごとに独立して行われ、特に系列データや小さいバッチサイズで効果的です。
勾配クリッピング(Gradient Clipping): 勾配の大きさが閾値を超えた場合にスケーリングすることで、勾配爆発を防ぎます。
これらのテクニックにより、深いネットワークの学習過程が安定し、より速く収束するようになります。内部共変量シフトへの対策は、深層学習モデルの性能向上に不可欠であり、現代のディープラーニングアーキテクチャ設計の重要な要素となっています。
オンライン学習について
オンライン学習とは、データを一度に1つずつ(または少しずつ)モデルに供給し、その都度、モデルを更新する学習方法です。このアプローチでは、全データセットを前もって用意する必要がなく、新たに得られるデータに基づいてモデルを連続的に学習させることができます。オンライン学習は、リアルタイムでデータが生成される環境や、データセットが非常に大きくて一度に全てを処理できない場合に特に有用です。
オンライン学習の特徴
連続的な学習: データが利用可能になるとすぐに学習を行うため、モデルは常に最新のデータに基づいて更新されます。
メモリ効率が良い: 一度に大量のデータをメモリに保持する必要がないため、リソースの消費が少ないです。
適応性: 新しいパターンや傾向がデータに現れた場合、オンライン学習を通じてモデルがこれらの変化に迅速に適応できます。
バッチ正規化とレイヤー正規化の組み合わせ
バッチ正規化とレイヤー正規化は、基本的には異なる目的と状況で使用されるテクニックですが、実際にはモデル内でこれらが組み合わされて使用されることもあります。その組み合わせ方は、モデルのアーキテクチャや解決しようとする問題の種類、そしてデータの特性によって異なります。
異なる層での使用: モデルの特定の層ではバッチ正規化が効果的である一方で、他の層ではレイヤー正規化の方が適している場合があります。例えば、深いネットワークの初期層でバッチ正規化を使用し、出力に近い層でレイヤー正規化を適用する、というように使い分けることがあります。
オンライン学習とバッチ学習の併用: ある状況では、オンライン学習を主に使用しながらも、定期的に大きなバッチでモデルを再調整することがあります。このような場合、レイヤー正規化を主に使用しつつ、再調整の際にはバッチ正規化を活用することができます。
それぞれの正規化手法は、モデルの学習プロセスを安定させ、加速するために設計されていますが、どの手法を使用するか、またそれらをどのように組み合わせるかは、具体的な学習環境やモデルの設計に依存します。したがって、実際のアプリケーションでは、異なる正規化手法の影響を実験的に評価し、最適な組み合わせを見つけることが重要です。
バッチ正規化 (Batch Normalization)
バッチ正規化は、ネットワークが一度に処理する小さなデータ集合(ミニバッチ)に対して行います。たとえば、写真の集合を考えてみましょう。それぞれの写真は「チャンネル」(色の情報)、写真の「高さ」と「幅」(空間情報)を持っています。バッチ正規化では、同じ色の情報を持つ全てのピクセル点(例えば、全ての赤い点)の平均値と、どれだけ点がばらついているか(分散)を計算し、これを使って各ピクセル点を調整します。これを同じミニバッチ内の全ての写真に対して行います。
レイヤー正規化 (Layer Normalization)
レイヤー正規化では、一つの写真に注目します。この写真の全ての色の情報と、全てのピクセル点に対して、平均値と分散を計算します。つまり、一枚の写真全体のピクセル点を見て、それをもとにその写真を調整します。これをミニバッチ内の各写真に対して独立に行います。
インスタンス正規化 (Instance Normalization)
インスタンス正規化も一枚の写真に注目しますが、ここでは色ごとに注目します。たとえば、赤い情報だけを取り出して、その赤い点すべての平均値と分散を計算します。そして、その赤い点を調整します。これをその写真の全ての色(チャンネル)に対して行います。
これらの正規化手法は、データを均一に扱うことで、学習過程をより滑らかにし、エラーを減らす効果があります。バッチ正規化はデータ全体の統計を使い、レイヤー正規化とインスタンス正規化はより個別のデータに焦点を当てた方法です。これによって、それぞれの写真や色の特徴が適切に認識されやすくなります。