
小規模から成長させるアプリケーションアーキテクチャ

MVPや、ユースケースの少ないweb app、CLIツールなど、小規模なアプリケーションを開発・運用していく場合、よく公開されているアプリケーションアーキテクチャから崩したほうが、開発コストとメンテナンス性のバランスが取れることがあります。支援先で説明する機会が多いので、私がよく採用するアプリケーションアーキテクチャを紹介します。
言葉の定義
この記事では、レイヤードアーキテクチャなどの、レイヤー分割とそれらの関わり方をアプリケーションアーキテクチャと呼びます。Web/AP/DBなどのティア分割ではありません。
まずは採用しているアプリケーションアーキテクチャの全体像です。

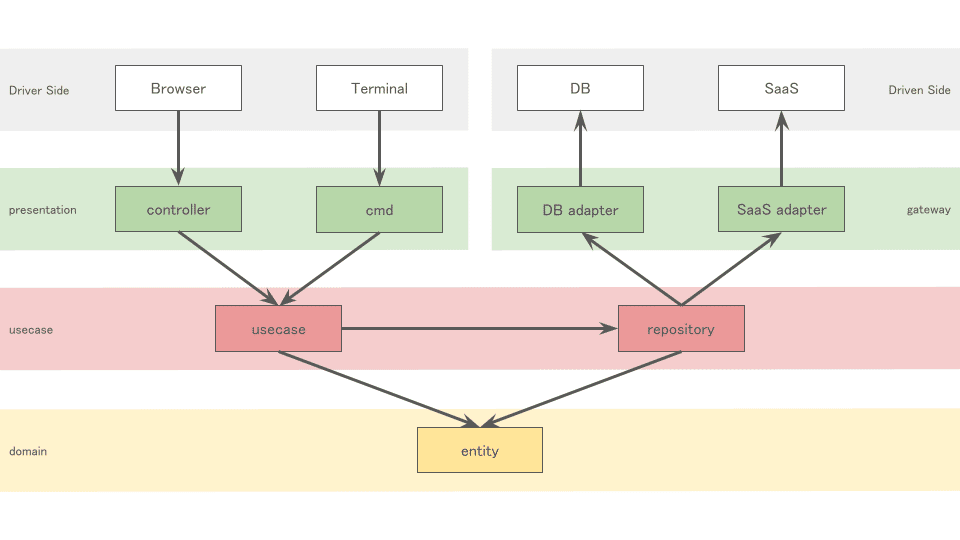
■参考にしているアプリケーションアーキテクチャ
詳細は他の方におまかせするとして、ここでは、私が捉えているイメージを紹介していきます。
●レイヤードアーキテクチャ
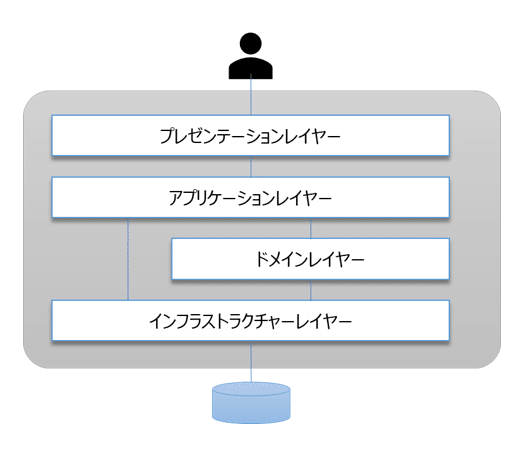
レイヤーごとの役割
presentation layer: UIの入出力
application layer: ユースケースを実現するステップ
domain layer: ドメインロジック(計算・判定ロジック)
infrastructure layer: データの入出力
参考
・レイヤードアーキテクチャーとは何ですか?
・ドメイン駆動設計の基礎知識
ドメインロジックと入出力を分離できる
アプリケーションの複雑度は、どれだけ複雑なドメインを扱っているかに依存します。入出力と分離することで、ドメインロジックに集中できるようになります。
入出力で考慮することを定型化できる
UIの入出力、データの入出力を分けることで、それぞれの処理で考慮することを定型化できます。
・HTTP requestをparseして、ユースケースの実行結果を、responseに変換
・検索条件からSQLを組み立て、射影をオブジェクトに変換
など、レイヤー内の処理を横並びで見ると、定型の処理に整理できるようになります。
ドメインロジックとデータアクセスを組み合わせて、ユースケースを組み立てられる
ドメインロジックとデータ入出力が切り出されていることで、ユースケースの実装は、それらの呼び出しで完結します。ユースケースを読むだけで、機能を大まかに捉えられるようになります。
●凹型レイヤー

レイヤーごとの役割
presentation layer: UIの入出力
business-logic layer:
- ユースケースのIF
- ユースケースの実装
- ドメインロジック
- データ入出力のIF
data-access layer: データ入出力の実装
参考
・springの概要 p8
依存の方向を逆転することができる
レイヤードアーキテクチャのレイヤーにそのまま処理を載せていくと、すべての処理がデータアクセスに依存することになります。DBで変更をかけると、すべてのレイヤーで変更が必要になることがあります。IFと実装を置くレイヤーをやりくりして、この依存関係を逆転しています。
実装を差し替えることができる
レイヤー間の依存が、IFとドメインロジックに限定されるので、IFの実装を差し替えることで動きを変更することができます。テスト時にmockを利用したり、DB変更前後の実装を設定で切り替えたりできます。
開発チームをレイヤーで分割できる
IFを介した依存になることで、IFが決まっていれば、実装のタイミングをずらすことができます。大規模な開発になると、ドメインに詳しい人は貴重な人材です。ドメイン/UI/データに詳しい人でチームを分け、IFを決めてから実装を進めるルールにすれば、レイヤーごとに並行して開発を進めることもできます。
●ヘキサゴナルアーキテクチャ

レイヤーごとの役割
driver side: UIの入出力
application layer:
- ユースケースのIF
- ユースケースの実装
- データ入出力のIF
domain layer:
- ドメインロジック
driven side: データ入出力の実装
参考
・Javaでクリーンアーキテクチャする方法
・Hexagonal Architecture(ヘキサゴナルアーキテクチャ) とは
分離する入出力にはdriver sideとdriven sideがあることがわかりやすい
UIなど「アプリケーションを利用する側」との入出力と、データストアなど「アプリケーションから利用される側」との入出力で、定型化する処理の流れを2種類に分類できます。
portとadapterのメタファーでつけ外しできることがわかりやすい
IFはport。portに接続するためのadapter。portの規格に合っていれば、adapterは付け替えられることがわかりやすくなりました。

●オニオンアーキテクチャ
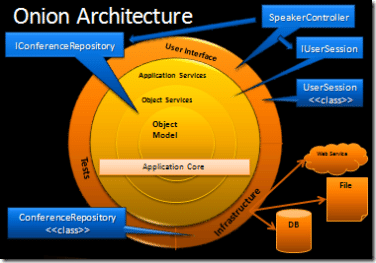
レイヤーごとの役割
Application Core:
Application Services: ユースケースを実現するステップ
Domain Services: 複数ドメインロジックを連携させるステップ
Domain Model: ドメインロジック
外側:
User Interface: UIの入出力
Infrastructure: データ入出力
Tests: テストドライバ
参考
・ドメイン駆動 + オニオンアーキテクチャ概略[DDD]
・新卒にも伝わるドメイン駆動設計のアーキテクチャ説明(オニオンアーキテクチャ)[DDD]
・Goと50%くらいの理解ではじめるクリーンというかオニオンなアーキテクチャ
変えたくない内側にApplication Coreという名前がついた
「application layerとdomain layer」をうまく呼ぶ名前がついていませんでしたが、みごとに体を表したシンプルな名前がつきました。
同心円、玉ねぎのメタファーで、外側を変えても内側が変わらないことがわかりやすい
Application Coreが、domain layerを包むapplication layerで構成されていること、その外側がつけ外し可能なことが、わかりやすくなりました。
●クリーンアーキテクチャ


レイヤーの役割
Frameworks & Drivers:
Web, UI, External Interfaces, DB, Devices
Interface Adapters:
Controllers: UIからの入力
Presenters: UIへの出力
Gateways: データ入出力
Application Business Rules:
Use Cases: ユースケースの実装
Enterprise Business Rules:
Entities: ドメインロジック
凹型にすれば、どこでも依存関係を内側に向けられることがわかりやすい
どのプロダクトのどのフェーズでも適用できる完璧なアプリケーションアーキテクチャは存在しないこと。必要な時に、必要なレイヤを追加し、必要があれば依存関係を逆転させれば良いことがわかりやすくなりました。
わかりやすい名前が増えた
サンプルとして明示してくれている構成で、ユースケースを実現するUse Cases、外部と通信する窓口にGatewayなど、役割を連想しやすい名前が増えました。
●ここまでの整理
レイヤード以降、いろいろなアプリケーションアーキテクチャが提唱されてきましたが、やりたいことは一貫しています。
・ドメインロジックと、それを利用したユースケースの実現に集中したい
・ドメインロジックに集中するために、入出力は定型化したい
・外部連携先や技術要素ではなく、ドメインロジックに依存させたい
ドメインロジックと、それを利用したユースケースの実現に集中したい
放っておくと、UIとDBをつなぐ中にドメインロジックが散在してしまう
ドメインロジックと入出力を分離すれば、分けて考えることができる
ドメインロジックに集中するために、入出力は定型化したい
アプリケーションを利用する側(Driver Side)と、アプリケーションから利用される側(Driven Side)がある
利用する側、利用される側でそれぞれ考慮するポイントは同じ
外部連携先や技術要素ではなく、ドメインロジックに依存させたい
アプリケーション外の変更で受ける影響範囲を小さくしたい
どのレイヤ間でも、凹型にすれば、同心円の内側に依存させることができる
■新規開発時のアプリケーションアーキテクチャ
参考にしているアプリケーションアーキテクチャからの学びを手段に落とすと以下の3つです。
あらかじめドメインロジックと入出力は分離しておく
あらかじめ入出力の相手ごとに分離して定型化しておく
外部連携先や技術要素の変更があったときに、凹型で依存を内側に向ける
そこで、レイヤーの構造はとりつつ、IFは利用せずに新規開発を進めています。

●前提にしていること
IFを利用しないことで、Driven Sideの変更はusecase layerやpresentation layerまで影響します。が、あらかじめ依存を逆転させて開発スピードを落とすより、リスクを取りつつ、リスクが発生しにくくなるように動いています。
usecaseのAPIは、頻繁に増減するけど、変更はそうそうしない
利用する外部サービスやデータストア製品は、そうそう乗り換えない
利用する外部サービスのAPI変更は稀にあるけど、それはがんばりどころ
データモデルは、頻繁に増加するけど、変更は起きにくく設計しておく
●システムアーキテクチャごとの例
システムアーキテクチャが異なる場合でも、アプリケーションアーキテクチャの考え方は基本的に変更なしで適用できます。つくるものの特性に合わせて役割の解釈を少し変えることはありますが、ベースになる型を用意しておくと、認識齟齬を減らし、可読性と開発スピードを維持しやすくなります。
webapp backendの場合

presentation layerは、HTTPアクセスのライブラリに合わせて実装します。gateway layerでは、ORMやOpen API Specificationから自動生成されたソースを管理しています。
PubSub / subscriberの場合

presentation layerがsubscriberのライブラリに変わっただけで、他はwebapp backendと同じ構成です。
cliの場合

presentation layerは、command line interfaceのライブラリに依存します。fileアクセスなどSDKで十分なAPIが提供されている場合は、gateway layerを介さずに直接利用しています。
k8s custom controllerの場合
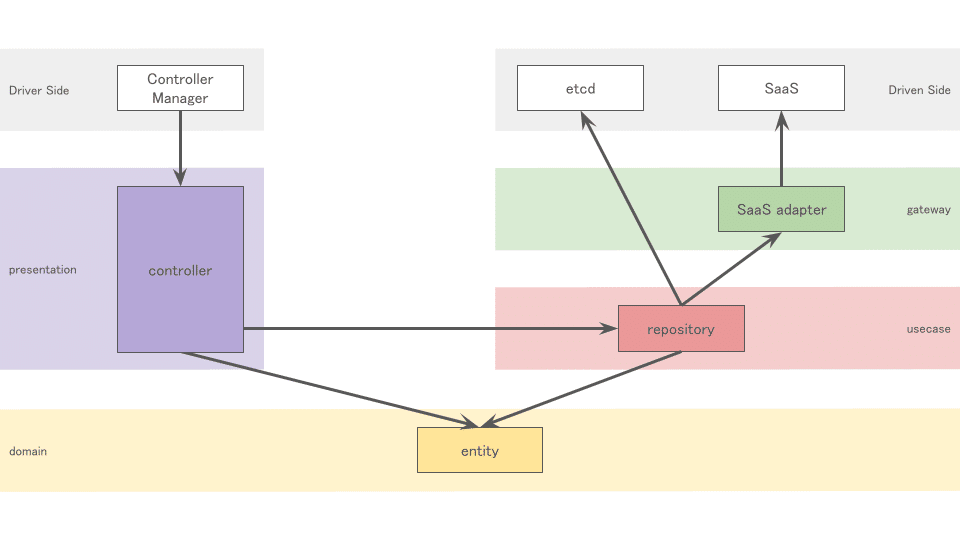
reconciliation loopの処理からusecaseを切り離そうとすると、usecaseが細切れになってしまうので、reconcile関数がusecaseを含んでいるものとして扱っています。
■テストを成長させる戦略
アプリケーションアーキテクチャが決まると、テスト戦略を考えられるようになります。2つのつながりは、こちらのスライドで紹介しました。
チームの状況や環境によりますが、基本的にこの方針で進めています。
開発チームの品質への自信を4つに分けて、ステージごとにどこを目指すのかを整理してみます。

●0→1
最短でローンチしたい期間です。 Application Core内は自動化で固め、外側は動作確認までと割り切っています。デプロイしてテストするものは、後で自動化するためのデータ収集だと捉えて、手動で進めています。

1.domainは、きっちり自動化

2.presentationとgatewayは、動作確認程度
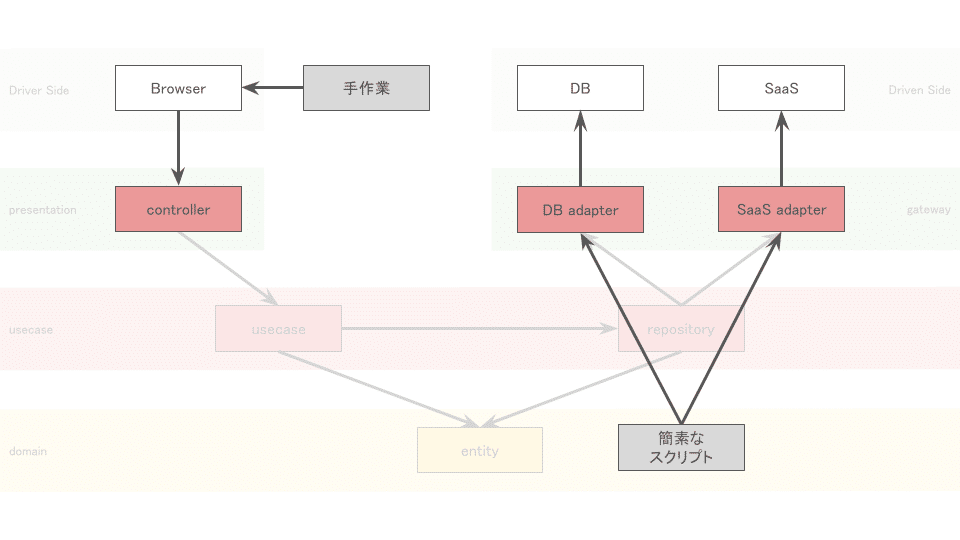
3.usecase単位で、ユースケースシナリオを網羅する自動化
※Driven Sideは、dev/stg環境などに接続

4.手動で、ハッピーパスのシナリオテストと探索的テスト

●1→10
ローンチ後、グロースに舵を切るまでの、頻繁に機能を追加・変更したい期間です。本番にデプロイするまでに必要な確認を自動化していきます。デプロイ後の動作確認も自動化すると、デプロイ頻度を上げやすくなります。本番障害に備えて、障害を再現しやすい環境を整えていきます。

1.Driven Sideをmockにして、usecase単位で自動回帰テスト

2.ハッピーパスのE2Eを自動化して、スモークテスト

3.ローカルにfakeサービスをデプロイして、本番障害の再現をしやすく

■まとめ
私が関わっているのは、少人数で、不慣れなライブラリ / runtime / platform / サービスへのスパイク打ちを多く抱えている状況がほとんどなので、偏りはあると思います。どんな状況だとしても、アプリケーションアーキテクチャの型を持っておくと、可読性と開発スピードを維持しやすいのは確かです。
あらかじめドメインロジックと入出力は分離しておく
あらかじめ入出力の相手ごとに分離して定型化しておく
外部連携先や技術要素の変更があったときに、凹型で依存を内側に向ける
ポイントを押さえて、アプリケーションアーキテクチャの型を整理してみてはいかがでしょうか?
いいなと思ったら応援しよう!
