
入力チェックは奥深い

人が入力する
ファイルから読み込む
他システムや機器から受信する
etc.…
システム化した際、プログラムに渡されるデータには色々あるのでしょうが、どんなデータ、どんな目的であっても、プログラムの中に入ってくるもの(=インプット)であればそれは必ずチェックしなければなりません。
仮に規格等が統一されていて絶対に「誤った値が入ってこない」とわかっていたとしても、プログラム外から受け渡されるデータであればチェックは必要です。
なぜなら、自分たちで作ったプログラムの中での値の受け渡しについてはテスト工程で散々確認しているため問題は基本的に残っていないかもしれませんが、プログラム外の場合は「そういうルールだから」というだけの口約束でしかなく、悪気はなかったとしてもいつ誤った形で送られてくるか不明であるからです。
今現在だけ切り取ってみれば、各社間、各担当間で意識合わせができていて信頼・信用しあえるかもしれませんが、5年・10年使うシステムにおいて、
ずっと同じエンジニアだけで連携しているか?
連携するシステムが追加されることはないのか?
仕様が追加や変更されることはないのか?
その時、同じように信頼や信用ができるのか?
と言われると、所詮未来のことなので答えは「その時になってみないとわからない」わけです。そういった先を見据えて、誤ったデータ等が混入されていてもその中で動くべきプログラムが異常とならないよう、水際で止めようとする仕組みが入力チェックになります。
ご存知のように、プログラム内でのデータの受け渡しはすべて"変数"に代入されることになります。変数には原則として『型』があり、その型で指定された形式以外の値を無理やり代入しようとすると、値そのものが変化するかあるいはシステムエラーとなって停止してしまいます。
int型と言われたら、整数値でなければなりません(小数値を代入しても、丸められてしまいます)。
float型と言われたら、小数値でなければなりません(整数値を代入しても、少数化されてしまいます)。
String型と言われたら、文字または文字列でなければなりません(数字ももちろん文字ですが、値ではなく文字なので計算はできません)。
画面から利用者の手を介して値を入力する場合、当然ながら入力項目1つ1つには『意味』が定義されています。
項目名:"社員番号"
と言われれば社員番号を入力し、管理するための項目でなければならないはずです。
そこに"氏名"を入力されても困るのです。
たとえば、Webシステムのログインにおいて社員番号をIDとして入力する画面があったとしましょう。みなさんならばこの"社員番号"欄に対して、具体的にどのような入力値チェックをすべきだと思いますか?あるいは一切のチェックが必要ないと思いますか?
「ADやOneLoginなど、シングルサインオンサービス使えば不要じゃん」とか、そう言うのはちょっと置いておいてください。ここでは、入力値チェックの重要性について説明していますので。
シンプルに"作り"のことだけ考えるなら、
「すでに登録されているDBへ問い合わせて、存在しなければエラー」
チェックだけで十分じゃないか?と言う意見も出てくることでしょう。
観点が"作り"だけであれば、実のところそれだけで十分かもしれません。
・必須チェック
・文字種チェック
・サイズチェック etc.…
色々ありますが、そういうチェックをあらかじめしておかなくてもDBに問い合わせて存在しない社員番号であればNGと返すだけでも十分です(nullも同様)。
しかし、それでは利用者にとって「何が悪かったのか?」が不明で不親切とみられる可能性があります。左記のとおり、DBに存在しているか確認する場合、仮にエラーとなっても
「お問い合わせいただいた社員番号が登録されていません。
正しい社員番号を入力してください。」
といったメッセージしか出せません。仮に半角数字10桁の値しか受け付けないような仕様であった場合、DB上にもその条件を満たした値しか存在しないわけですから、たとえば
"AAAA"
という社員番号を入力してログインしようとすれば、そりゃ存在していないに決まっています。ですが実は存在しないことが問題なのではなく、そもそものルール『半角数字10桁』を守れていないから存在するわけがなかった…というのが真の問題なはずです。
DBに存在していなかったのは結果論でしかありません。
この時
「社員番号は半角数字10桁でご入力ください。」
とした方がよいのか、さきほどの
「お問い合わせいただいた社員番号が登録されていません。
正しい社員番号を入力してください。」
とした方がよいのか、みなさんならどちらを選ぶでしょうか。
また、選んだ際にそうしたほうが良いと思う根拠を明確にできますでしょうか。
さらにいえば、そもそも入力欄は『半角数字10桁』という前提条件があるにもかかわらず、なんでも入力できるようにしたほうがいいのでしょうか。
こういった観点を "ユーザビリティ(usability:使いやすさ、使い勝手)" と言います。
利用者の年齢層やシステムに対する理解度など、利用者の予備知識の有無を考慮に入れたうえで、「入力操作のどこに問題があったのか?」を特定する目的で細やかなチェックを必要とする場合もあります。
これはただ単にプログラミングするだけの観点ではなかなか生まれない発想で、"利用時"・"利用者"・"利用目的"の観点から検討しないとなかなか身につけることができません。
また、"システム特性"などに精通していれば、さらに
禁則文字(ルール外入力値)
に対するチェックも視野に入ることでしょう。
たとえば、Webシステムの場合ですと"<"や">"などが混入していると、後で画面表示の際にHTMLタグが崩れてしまって、画面表示がおかしくなってしまうケースがあります(もちろんそうさせない技術は存在しますけども)。
たとえば、"*"や"?"はワイルドカードとして認識されてしまうかもしれませんし、"\"を混入させるとエスケープシーケンスとして認識してしまうかもしれません。
たとえば、SQL操作などでは"SQLインジェクション"に代表されるように、不正操作を可能とする文字列を組むことだってできてしまいます。また、プログラムの予約語や構文編成などは必ず注意して設計およびテストすべき観点だったりします。
こう言った課題に対し、
「社員番号を入力しろって言っているのに、他の文字を入力するやつが悪い」
と他責な考え方しかできないようではエンジニアとして三流です。
エンジニアであれば、プロでもアマでも大前提として知っているはずです。
「コンピュータは与えられた命令しか実行できない」
「利用者は必ずしもITリテラシーが高いわけではない」
そういうものです。
「人」という限りなくアナログでアバウトな存在に依存して、プログラムの走査上で起きうる危険性が予測できないアルゴリズムしか作れないようでは、社会インフラに根ざしたシステムを構築することは難しいでしょう。
社会インフラに大きな影響を与えかねないITシステムの構築、開発に携わる私たちにとってよほどの天変地異でもない限り、「想定外」なんて言葉を軽々しく使ってはならないのです。
たとえばセキュリティなどは限りなくドス黒い人間の悪意を前提に対策を想定しなければならなかったりもするほどとことんリスクを予測しなければなりません。そのようななかで軽々しく「想定外」などと言い訳をしているうちはまだまだエンジニアリングとしてはヒヨッコなのかもしれません。
一般に「入力チェック」は、コアなサービスやビジネスロジックという位置づけにはなく、プレゼンテーション層におけるただのサポート機能(利用者にとっての利便性向上程度)のように見られることが多くあります。
しかし、ただの入力チェックでさえも軽視していると痛い目に遭います。
この入力チェックは利用者の「使用性」「利便性」にも大きく寄与する上に、実はセキュリティの観点にも多々かかわってくることが多い品質特性であったりもします。
たとえばエラーメッセージ1つとっても、その内容があまりにも詳しすぎたりすると悪意ある攻撃者が見ればシステム構成などまで読み解いてしまう可能性もあります。
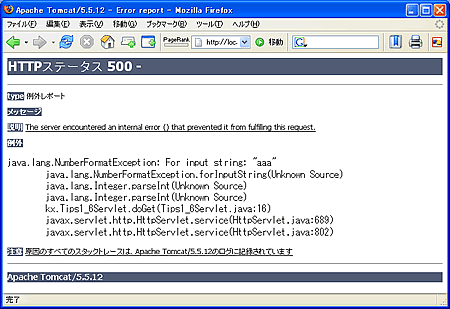
あるいはIDやパスワード、カード情報や個人情報などをメッセージに加えるのもよろしくありません。ふと後ろを通りがかった人が目にしてしまう危険性もあるのです。
また、そうしたエラーメッセージを乱用しないよう、入力チェックの機会を減らそうと入力抑制やプレースホルダーなどを多用しすぎると、そのルールを把握するだけで入力項目にどんな値を設定すればいいか教えてしまっているようなものだったりします。
利用者にとってより楽に入力させられて、より詳細に理解できて、より分かりやすいメッセージを…とそれだけに集中して盲目的になってしまうと、場合によってはセキュリティがザルだらけ…ということにもなりかねなかったりするため、システムの本質的な目的や利用のされ方、その環境などをしっかりと理解したうえで、バランスをとることが重要になります。
メイン機能でもなんでもないただの入力チェックですが、されど入力チェック。
ナメてかかると痛い目にあうこともよくあったりしますので、注意しましょう。
いいなと思ったら応援しよう!
