
AI2nd day6 時系列予測と因果推定

day5 Q&A
・deepseekに入れたくない個人情報があるとき
→大まかな方針や使うモデルをdeepseekに聞いておいて、それ以降の実際のデータも入力したプロンプトはchatgpt、Azure、Copilotなどに入力するという使い分けが良い。最も安全なのはCopilot(Microsoft)かもしれない。
・エラーコードとひたすら戦うことに再現性はあるのか?
(毎回エラーを解決することに再現性はあるか?)
→ある。なぜなら、問題解決はルーチンワークだから。
目の前にある現実の問題と頭に描く理想、そしてその乖離をそれぞれ言語化してAIに投げて解決方法を探し、うまくいかないならば人間が知識を新たにつけることで前に進んでいく。これは再現性がある。
ただ、堂々巡りになってしまう時もある。
AIは入力された問いに対して妥当性の高い答えを出力するというもの。
そこで堂々巡りをしているということは、入力している問いが悪い、つまり人間側が入力すべきものが不十分/不適切、すなわち知識が足りないということになる。
試行錯誤の流れを忘れないように。

本編
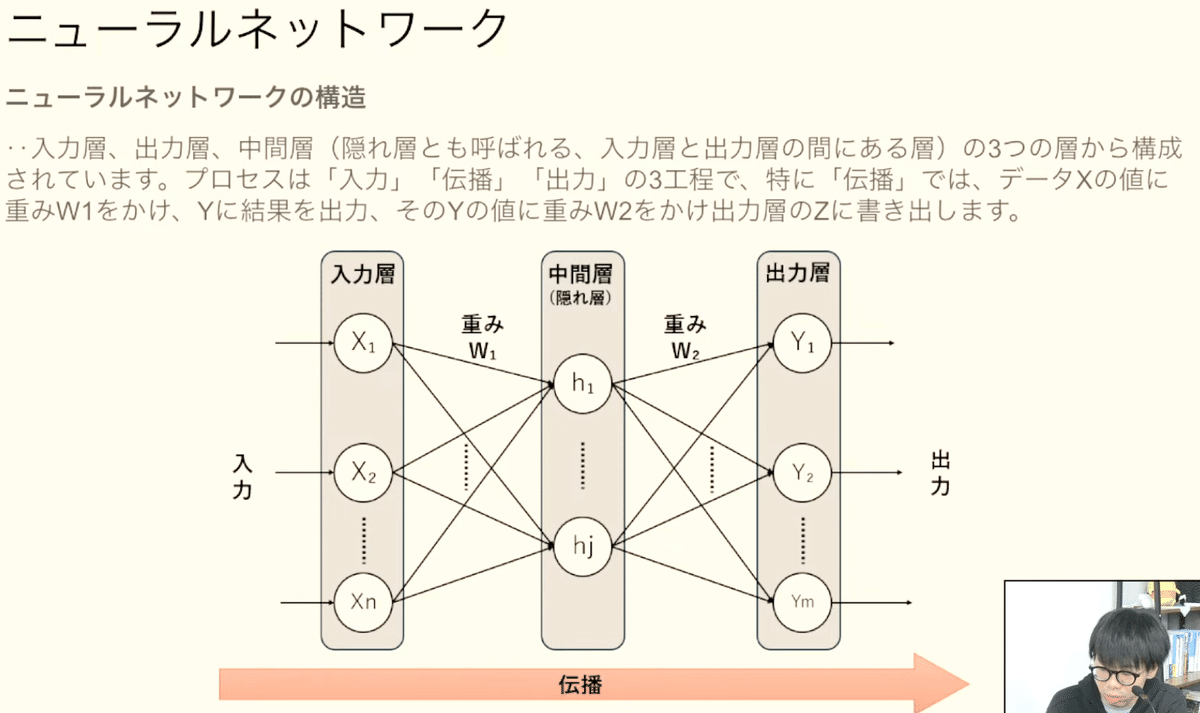
ニューラルネットワーク
脳神経細胞のシナプスをトレースして、人間の脳の神経回路を数式で表現したもの。ディープラーニングはニューラルネットワークをベースにした機械学習モデル。
今回やりたいこと:今あるデータから、未来を予測する
「1,2,3,1,2,3,1,2,3,1,◯」
と数字が並んでいて、◯に当てはまるのは何か?と聞かれたら、多くの人は「2」と答えるだろう。
このように、人間は周期性に気づいてある程度未来を予測することができる。
そして専門家はその分野についてより多くの法則を理解しているからこそ、一般人よりも確度高く将来を推計できる。

そして、AIが人間に勝るものは何か?
→判断材料が複雑系に入るとき、AIが生きる。
どういうことかというと、人間が一度に処理する情報量には限界があるが、AIはそうではないということ。
例えば、下図の左側のデータを見たときにどう考えるか?波のような時系列のデータであるが、ここに周期性はあるか?
ありそうには思うが、具体的な判断は難しい。
しかしコンピュータは、一瞬でこのデータを右図のように複数の波に分解して、いろいろな法則性を判断し、その上で未来のデータを予測してくれる。

余談:セル結合はするな!!
セル結合をすると、機械用の情報集合体から、ただの人間向けの「表」
に成り下がってしまい、機械がそのデータを読めなくなってしまう。
アウトドア用品店の過去販売データから、未来の販売数を予測したい
過去データを時系列でグラフにしてみると、大まかに周期性があるように見える。(下図)
時系列分析では、このようにしてまずグラフで見てみて、トレンドや周期性を大まかに掴むことが大事。

ARモデル
ARモデルは、自己回帰モデルとも言われ、現在の値を過去データを用いて回帰する時系列モデルである。
これを用いて予測をしてみる。
deepseekにプロンプトを投げ、ARモデル実行のためのコードを出力してもらう。そしてggogle colabで実行。以下が得られたモデル予想。

青(train):モデルの学習に使った「過去の実際の売上データ」
オレンジ(test):モデルの予測精度を評価するための「未来の実際の売上データ」
緑(prediction):ARモデルが「テスト期間」に対して予測した売上値
青色は過去データのうち、モデルの推測に用いた部分。
オレンジはの直近データで、モデルの推測には用いていない部分。
緑色はモデルが予測した売上を示す。オレンジ色に対して緑色が重なっていれば、このモデルは精度が高いと言える。
さらに以下は95%信頼区間を追加したグラフ。

95%信頼区間の幅が広すぎて、これでは実用的ではないという印象である。
今度はSARIMAX modelというモデルを用いて、同様手順で予測を行ってみる。同じ手順でコードを実際に実行してみると、まず以下のようにデータが要素ごとに分解された。

そしてSARIMAX modelによる解析モデルは以下。

オレンジ(test):モデルの予測精度を評価するための「未来の実際の売上データ」
緑(prediction):ARモデルが「テスト期間」に対して予測した売上値
灰色部分:95%信頼区間
Grenger(グレンジャー)因果性検定
次に、Grenger(グレンジャー)因果性検定について考えていく。
検定の目的: 「変数Xの過去の値」が「変数Yの未来の値」を予測するのに役立つかを判定する。
注意点:因果関係の証明ではない(あくまで「予測に役立つか」を判定)ということ。「XがYの原因」とは限らず、逆方向や共通の原因が存在する可能性がある。
実際の手順:
2つの時系列データ(例: XとY)を用意。データが定常性(トレンドや季節性がない)を持つことを確認。
モデルA: Yの未来を「Yの過去のみ」で予測。
モデルB: Yの未来を「Yの過去 + Xの過去」で予測。
検定:モデルBがモデルAよりも統計的に有意に予測精度が高いかを判定
帰無仮説: 「XはYのグレンジャー因果性を持たない」(モデルBの精度 = モデルAの精度)。
p値 < 0.05 → 帰無仮説を棄否し、「XはYのグレンジャー因果性を持つ」と結論。
ということで、アウトドア用品の販売数に関係するデータをグレンジャー因果性検定を行って検証を行い、SARIMAX modelを用いて予測をしてみる。
以下はグレンジャー因果性検定の結果。通行人、来店数、webアクセス数がp値<0.05で有位差ありなので、因果性ありの判定。
=== グレンジャー因果性検定結果 ===
❌ 気温: 因果性なし
❌ 湿度: 因果性なし
✅ 通行人: 因果性あり (最小p値: 0.000)
✅ 来店数: 因果性あり (最小p値: 0.000)
✅ webアクセス数: 因果性あり (最小p値: 0.000)
そして以下がSARIMAX model。最初の2つの予測結果よりは、マシになった気がする。まだまだ95%信頼区間は範囲が広いけど。

赤:予測データ
薄赤色部分:95%信頼区間
まとめ
いろいろなモデル(ARモデル、SARIMAXモデル、etc)それぞれについて詳しく知っている必要はない。
まずデータの特性を人間がグラフで大まかに把握して、
どの機械学習を用いればいいかを判断して、
AIと会話しながら良い予測を都度修正しながら考えていくことが重要。
それを最終的に意思決定に活かせること。