
誤ったデータで意思決定してしまうリスクを排除

BigQueryのスケジュールクエリがお手軽すぎて利用するシーンが増えています。例えばデータレイクから集計した結果をデータマートに吐き出すといったことが簡易的にできます。
しかし、個人的な利用にとどまらずビジネスの意思決定に利用されるような全社的なKPIや分析に利用する数値を集計するとなると、1点注意が必要です。
それは、BigQueryのエラーに気づかないまま、誤った集計結果で意思決定してしまうリスクです。
BigQueryのSLAをみてみると…
BigQueryってそんなにエラー発生するの?と思うかもしれませんが、BigQueryのSLAをみると「99.9%以上」です。これは実際に運用してみると遭遇する場面が割とあります。

実際に私が遭遇したエラー。

意思決定に利用されるような重要な指標をBigQueryのスケジュールクエリだけで運用していくのは、個人的には厳しいと考えています。
理想はマネージドなデータ基盤を構築することを望みますが、一方でスタートアップやベンチャー企業にとっては予算的にも人材的にもリソースに余裕がないケースがあるのではないかと思われます。
そのような状況下でも、BigQueryだけでデータマートを運用していく上でリスクを回避する仕組みをいれておくことをおすすめしたいです。
ではどうすればいいか。その一例をご紹介します。
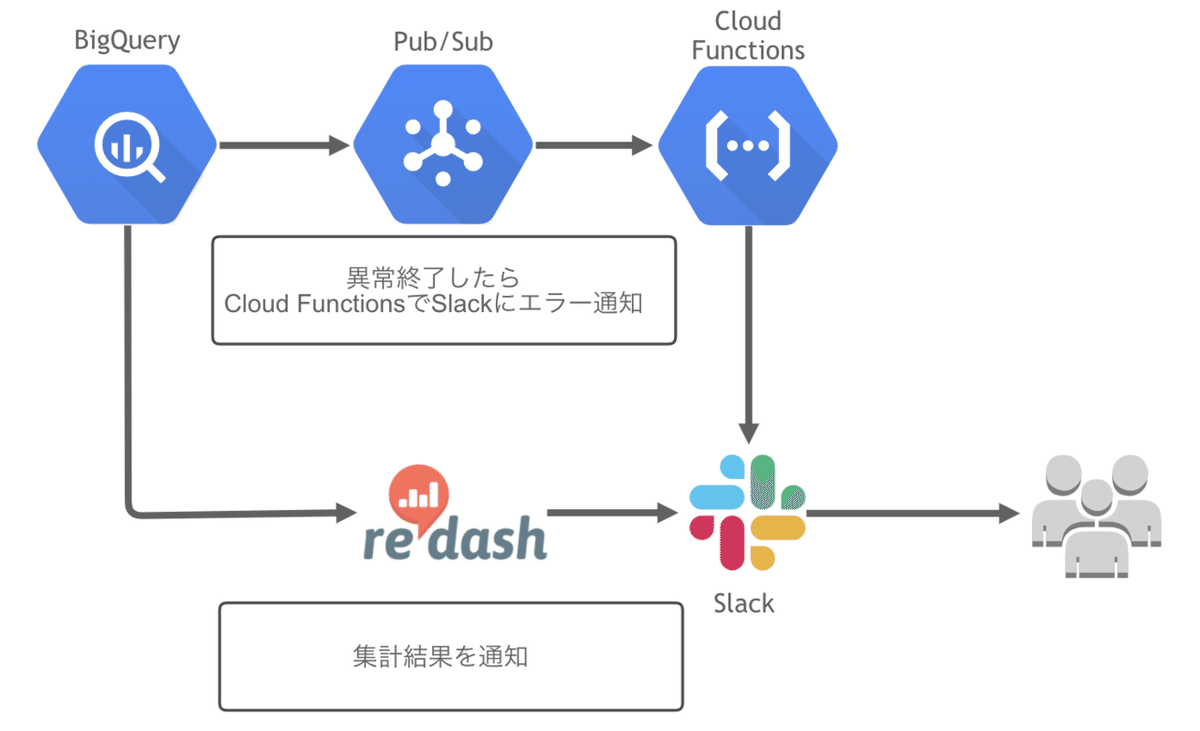
完成イメージ
最終的なアウトプットは全てSlackに通知します。集計グラフだけではなくアラートも同じチャンネルに通知することを意識しました。
目的は、非エンジニアにも異常を知らせることで集計に失敗していることを伝え、意思決定ミスのリスクを回避することです。
アラートなんてエンジニアだけのチャンネルでいいじゃん?と思いがちですが非エンジニアにもキチンと伝わることを期待しています。
以下、Slackにアラートと集計グラフが流れているイメージ。

構成
集計結果を通知
re:dashの集計結果をSlackのリマインダーで日次投稿しています。
以下通知ののイメージ。

この設定についてはググると情報はたくさんあるので、説明は省かせていただきます。「slack redash」と検索してみてください。
アラートをSlackに通知
スケジュールクエリがエラーになると、Pub/Sub→Cloud Functionsを経由してこれまたSlackにリアルタイム通知されます。
以下アラートのイメージ。

Cloud FunctionsにPythonで実装しました。参考までにコードも載せておきます。
通知したいSlackチャンネルのwebhook-urlを環境変数[WEB_HOOK_URL]に設定していただければ動作すると思います。
import requests
import json
import base64
import os
def notify(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
pubsub_message = json.loads(base64.b64decode(event['data']).decode('utf-8'))
message = pubsub_message['errorStatus']['message']
state = pubsub_message['state']
run_time = pubsub_message['runTime']
destination_dataset_id = pubsub_message['destinationDatasetId']
destination_table_name = pubsub_message['params']['destination_table_name_template']
payload = {
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "BigQueryスケジュールクエリでエラーが発生しました。"
}
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": message
}
},
{
"type": "section",
"fields": [
{
"type": "mrkdwn",
"text": "*state:*\n{0}".format(state)
},
{
"type": "mrkdwn",
"text": "*run_time:*\n{0}(UTC)".format(run_time)
},
{
"type": "mrkdwn",
"text": "*destination_dataset_id:*\n{0}".format(destination_dataset_id)
},
{
"type": "mrkdwn",
"text": "*destination_table_name:*\n{0}".format(destination_table_name)
}
]
}
]
}
# WEB_HOOK_URLは環境変数から
requests.post(os.environ['WEB_HOOK_URL'], data = json.dumps(payload))ここまで大体2時間くらいでできました。
最後に
意思決定に必要なデータを簡易的に構築する場合のリスク回避方法について紹介しました。
理想的にはデータ基盤を構築することが望まれますが、一方でスタートアップやベンチャー企業にとっては予算的にも人材的にもリソースに余裕がないケースがあるのではと思われます。
そのような場合にも活用できる仕組みかと思います。是非ご参考になれば幸いです。
いいなと思ったら応援しよう!
