
今更聞けないLLM解説まとめ③事前学習

始めに
どうも、それなニキです。
今回から本格的にLLMの仕組みを掘り下げていきます。
相も変わらず私の思考メモなので読みづらいですが悪しからず。
1.ニューラル言語モデル
まずは、LLMを解説するうえで基礎となる言語モデル(LM)の構造から扱っていきます。
第一回でちらっと触れたと思いますが、言語モデルというもの自体はそれほど新しいものではなく、過去に様々なタイプが開発されてきています(n-gram言語モデル等)。
しかし、今日話題となっているLLMにおいては、ニューラル言語モデルという、以前とは異なるタイプの言語モデルが利用されています。
ニューラル言語モデルの構造は、エンコーダとデコーダという二つのニューラルネットから成立しています。
これらは、以下のような役割分担になっています。
エンコーダ…入力専用
デコーダ…出力・再帰的入力(自分の出力結果を次の出力に使うために再度自分に入力する)
デコーダの説明が少し難しいのですが、例えば
「吾輩は」という文章をエンコーダに入力
「猫」という文字をデコーダが出力
「猫」をデコーダが再帰的入力することで、入力文が「吾輩は猫」になる。
「吾輩は猫」をデコーダが参照し「である」という文章を出力する。
といった感じで動作します。
ニューラル言語モデルの代表的な種類を解説します。
①RNN型言語モデル

冒頭の単語から一単語ずつニューラルネットワークに入力して、ニューロンを逐一更新するタイプです。
…と資料では説明されていますが、正直なんのこっちゃだと思います。
実は現在は後述するTransformerが主流になっているのであまり見かけません。
自分としては先述したエンコーダ・デコーダのシステムを、決まった長さで動かして文章を次々作っていく、ファスナーのスライダーみたいなシステムだと理解していますが、多分こんなものもあるんだなぁくらいの認識でいいと思います。
一応メリット・デメリットをまとめておくと、
メリット
・原理的にいくつでも入出力が可能
デメリット
・ニューロンが固定長で、長文の情報をすべて覚えきれない。
・ネットワークが単語方向に深くなる(単語同士の関係ばかり学習してしまう?)ので、学習が不安定で遅い
という感じです。
②Transformer(概略)
ついに来ました。
これまで何度か名称だけ出ていたTransformerがここで登場します。
ということはこれはニューラル言語モデルの一種なわけですね。
「Attention is All you Need」という論文によって発表され、文字通り言語モデルの世界を変えてしまった、ニューラル言語モデルの超大作です。
かなり複雑なことになっているので、原文から図を引用して説明します。

これは、Transformerを構成する最小単位「ブロック」です。
かなり複雑そうに見えますが、灰色で囲まれている部分の左がエンコーダで、右がデコーダに使用されます。
そう考えると、何とか理解できそうな気がしてきませんか?
ここからちょっと説明が複雑化してくるので、松尾研の資料の画像を多用していきます。

Transformerの全体像のイメージを引用しています。
左半分がエンコーダ、右半分がデコーダです。
先ほど紹介したブロックが大量に積み上げられているのが分かります。
RNNと違うのは、スライド中にも記述がありますが、トークンの数だけブロックが横に増えていくということです。
固定長で移動していくというより、丸ごと処理しちゃえという精神なわけですね。
最初にAttention Is All you Needで発表されたのは上記の形式ですが、実は現在GPT系に使われている形式は少し違って、上記の図からエンコーダが丸ごと無くなったものを使用しています。
察しのいい方はエンコーダ・デコーダの話をした際に気づいたかもしれませんが、実はデコーダは出力と再帰入力ができるために、デコーダだけでもテキスト生成が可能なんです。
2. Transformerの具体的な説明
ここからは、現在特に利用されているTransformerの各パーツについて詳しく解説していきます。
①Embedding
まずは図の下の方にあったピンク色の「Embedding」から。
ここは、テキストをTransformerに取り込む部分になります。
取り込むといっても、プログラムに文字を「理解可能な形」で提供する必要があります。
この「理解可能な形」とは何が理解できて、どんな形だと良いかというと
単語同士の関係が理解できて
数値、特に計算がしやすいベクトルという形
です。
具体的には
テキストをトークン(処理単位)に切り分ける。
トークンをトークンID(数値)に変換。
One-hotベクトルに変換。
One-hotベクトル…[トークンID]番目だけ1で、残りがすべて0であるベクトル
Word Embeddingベクトルに変換
という順序で行われます。
特にテキストをトークンIDまで変換する作業はトークナイザーと呼ばれるものが担当します。
このトークナイザーも後々重要になります。
また、One-hotベクトルをWord-Embeddingベクトルに変換する部分はMLP(線形変換)が担当しますが、このMLPのパラメータは学習対象(機械学習によって更新される)です。
で、ようやく単語をベクトルに変換できたわけですが、こうしてできたWord-Embeddingベクトルを見てみると、意味的に関係の強い単語が座標的に近い位置に来るようになっているなど、きちんと「単語同士の関係が理解できる」形になっていることが確認できます。
①'Positional Encoding(PE)
さて、これをTransformerブロックに取り込む前に、Word Embeddingベクトルに位置情報を追加する必要があります。
この処理は、Attention Is All you Needの図ではWord Embeddingのすぐ上にくっついている丸の部分に当たります。
PEをしないといけない理由は簡単で、Transformerブロック自身に、自分の位置情報を把握する能力がないため、その情報をWord Embeddingベクトルに入れておく必要があるためです。
「後の祭り」と「祭りの後」を混同するようではシャレになりませんからね。
具体的にどうするのかというと、先ほどのWord EmbeddingベクトルにPositional Encodingベクトルを直接足し算します。
なんて雑なやり方なんだ()
このPEベクトルは、以下のような値になります。

②Attention機構
これまた何度も名前を取り上げてきた「Attention機構」がついに満を持して登場です!
Attention Is All you Needの図の中でいうと、エンコーダ・デコーダのブロックの中にあるオレンジ色の部分ですね。
最初にざっくりまとめた松尾研の資料の言葉を借りると
「全トークン間の類似度を測ることによって、⻑距離のトー クン間の依存関係を把握することを可能にした機構」(第三回P31より)
です。
これから具体的に解説していきますが、めちゃんこ難しいので、松尾研の資料と、授業で引用されたTowardsDataScienceの解説資料をガンガン引用して実際の動きを紙芝居していきます。

まず、先ほどのEmbeddingとPEを通したベクトルを用意します。

そこから線形変換(Embedding中のものと同じく、こちらも学習対象)でKeyベクトルとValueベクトルを生成します。
Keyベクトルは主に文中の他の単語との関係を計算するのに使います。
Valueベクトルはトークン自身の情報保持が役割だった気がする…

続いてここが肝なんですが、第一トークンと他のトークンの関係を計算するために、線形変換(無論学習対象)でQueryベクトルを生成します。

そして、先ほど作ったQueryベクトルとKeyベクトルの内積をとっていきます。
これが各トークン同士の類似度に相当します。
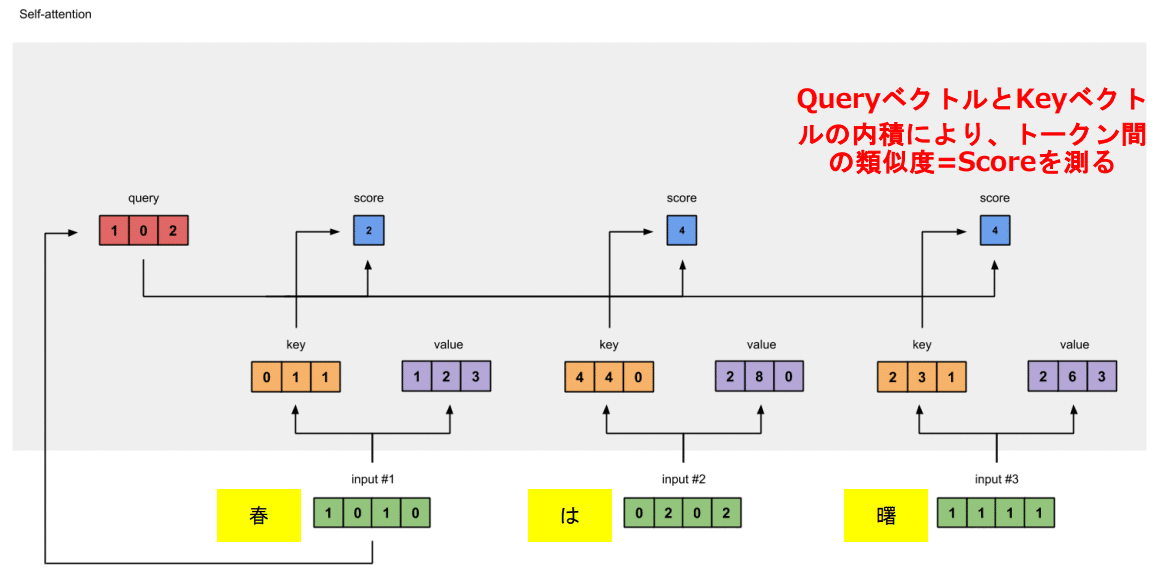
この作業を最後まで行っていきます。

類似度を使いやすくするために、ここで一旦正規化(合計で一になるように調整)します。
ここで使用しているsoftmax関数については本題からそれるので割愛しますが、気になったら調べてみてください。

そして、先ほど計算した類似度にValueベクトルを掛け算します。
これで第一トークンとそれぞれのトークンの関係性が含意された値が出てきます。

もちろん最後までやります。

最後に、先ほど求めたベクトルの総和をとって、これを第一トークンにおける出力値とします。

この作業を、Queryベクトル作成の際に使うトークンを変えながら、すべてのトークンについて行います。

これで、Attention機構の出力が出そろいました。
お疲れさまでした。
というか私が疲れました。
多分授業資料を作った松尾研の方々や、元となったTowardsDataScienceの方はもっともっと疲れていると思います。
さて、この面倒くさい機構は、1ステップで全単語とつながることができるので、
単語間の長距離依存関係を把握できるようになる。
すべてのトークンの情報から、必要なものだけ取捨選択できるため。
誤差逆伝播が安定かつ高速になる。
学習させているときに、なぜ間違ったかを安定かつ高速に学習できるということ…だと思う。
というメリットを持っています。
結果的に、前述のRNNのデメリットをほぼ克服できています!
松尾研資料の言葉を借りると、
「アテンション機構にて, 各トークンのベクトルが (全トークンとの関係性を 取り込んで)より良い表現に Transform=変換された!」
と言うことができます。
②'Attention機構の補足
このAttention機構ですが、もちろんそのまま使っても十分すごいですが、用途に合わせて少しカスタマイズされて利用されます。
エンコーダ側では、入力テキスト内でAttention機構を回します(Self-Attention)が、
デコーダ側では、入力テキストと出力テキストに跨ったAttention(Cross-Attention)や、出力テキスト内でのAttention(Self-Attention)、自身より未来のトークンについてアテンションを張れないようにマスク(Causal Attention Mask)をかけたAttentionなどがあります。
マスクをかけるのは、未来のテキストを予測する機構で未来のテキストを参照してしまうと、カンニングになってしまうのでそれを防ぐためです。
また、Attention Is All you Needの図では、Attention部分の名前が「Multi-Head Attention」となっていましたが、これはAttention処理を複数個並列で行い、それらの出力を一つに統合する形式のものです。
これは、一つのトークンが様々なトークンに、異なる形式のAttentionをあてることを可能にします。
…と松尾研の資料に書いてありますが、詳しくは分かっていません()
分かり次第追記します。

③Feed Forward
さて、Transformerの説明に関してはほとんど終わったようなものです。
あと一息!
次はFeed Forwardです。
Attention Is All you Needの図で見ると水色の部分。
ここは一言で言ってしまうと巨大な二階建てのMLP(線形変換)になっており、知識の収容を担っています。
もちろんそのパラメータは学習対象です。
一応その計算式を以下に引用します。
まあ専門にしない方は覚えなくてもいいかも。

Feed Forwardの特徴は、その膨大な量のパラメータです。
入力されたベクトル(Attention機構の出力)を処理するために、その4倍の次元を持つ中間層が必要となり、結果としてLLM全体の約66%を占める圧倒的なパラメータ数を誇ります()
少し余談になりますが、FeedForwardに対応する日本語の用語は前方向伝播であり、入力データがニューラルネットを通じて処理されて出力を形成するプロセスを指します。
すなわち、このFeed ForwardこそがLLMの本体であり、これまで散々重要性を指摘したAttention機構などはその前準備のための処理であると考えることもできます。
詳しく見ると、Embedding+PEで文章を分解・位置関係を付与したベクトルに変換し、Attention機構でその単語同士の関係性を詳しく確認(より良い表現に変換)、それらを踏まえてFeed Forwardで文章を解釈して出力を作成する、といった流れになっていると考えることができるでしょう。

④その他
さて、Attention Is All you Needの最初の図について、残すところわずかとなりました。
残りは細かい話なので1つにまとめてしまいます。
まずはAdd&Norm。
Addはその名の通り、何かを「足す」訳ですが、何を足すのかというと、直前の処理の入力データです。これは、Attention機構やFeed Forward機構によってデータが過剰に変化しても、元々の入力値の情報が喪失されるのを防ぎ、学習効率の改善・学習の安定化に役立ちます。
Normもその名の通り正規化(Normalization)…と言いたいんですが、公式を確認した限りどうも標準化の方だと思います。統計学をかじったことのある方なら、標準化に平均と標準偏差が必要なのが分かると思いますが、ここでは直前の処理における入力データの総和を活性化関数(ニューラルネット界隈にそういう関数があるらしい)にかけた値が用いられるそうです。
続いて最後の出力層(Linear → Softmax)ですが、これはもう簡単で、Feed Forwardから出てきた(加えてAdd&Normの処理を経た)結果を、実際に次の単語の生起確率になるように線形変換したうえで、正規化し、確率分布として出力します。
ようやく回答と言える、次の単語の生起確率が出てきました。
お疲れさまでした…
(実はまだ「特定の単語」が出力された訳ではありません。この点は後々出てきます。)
3.事前学習について
まだ終わらネェ…
というわけでここから、この投稿のタイトルにもなっている「事前学習」について掘り下げることができます。
前々回に確か触れたような気がしますが、LLMはそれまでの言語モデルとは違い、一つのモデルが複数のタスクを処理できるようになっています。
そのためには、まず基盤となるモデルを作成し、その後タスクに合わせてカスタマイズできる必要があります。
そのための良い基礎、すなわち良い初期パラメータを得るための学習を事前学習といいます。
松尾研の説明では確か「読み書きそろばんを教える段階」みたいな説明がされていたような気がします。
事前学習は、大きく分けて
データ収集
データ前処理
訓練
評価
の4段階に分けることができます。
①データ収集
学習に用いるデータをまずは集めてこないと始まりませんが、事前学習用のデータとなると、他の学習段階と比較しても非常に大きなデータセットが必要となります。
そのため、一般的にはWEBからの大規模クロールデータが使用されます。
例えば、一般的なサイトとしてCommonCrawlやC4、プログラム言語のデータとしてGithub、小説はBooks、論文はArXiv、その他をWikipediaなどから取集します。
一例として松尾研の資料ではGPT-3(今ChatGPTの無料版で利用できるGPT-3.5の前身)が挙げられており、GPT-3の場合は約5000億トークンのテキストを利用して学習が行われたようです。
また、Llama2など、最近のモデルはパラメータ数を少なく抑えつつ、事前学習に用いるトークン数を増やしてパフォーマンスを改善する例も多いようで、Llama2は約2兆トークン使って学習しているそうです。
②データ前処理
無論、このままだと玉石混交だし形式も統一されていないので、学習前にデータの前処理が必要です。
具体的には
Quality Filtering
分類器やヒューリスティックにより質の低いデータを取り除く。
De-dup
重複を排除する。近い場所に重複があると学習への悪影響が大きいために必要となる。
Privacy Reduction
個人を特定できる情報を取り除く。
Tokenization
トークン化。Embeddingでも触れたが、トークン化の手法はいくつかある。
という感じです。
特にTokenizationについては、効率的にトークン化したいという需要から、一般に、語彙の出現頻度と関係したアルゴリズムで実現されます。
Byte Pair Encoding(BPE)や、SentencePieceなどがあります。
(そういえばsentencepieceはStableDiffusionにも出てきますね)
③訓練(事前学習)
さて、ここまで来てようやくモデルを訓練(事前学習)できます。
事前学習で行われる学習は、いわゆる自己教師あり学習の一種であるNext Token Predictionです。
その名の通り、次のトークンの生成確率をひたすらに予測し、予測と正解の誤差をより小さくなるように学習します。
この「誤差」の評価に用いられる関数は「交差エントロピー」と呼ばれ、

と表されます。
この関数が小さくなるようにパラメータを更新するわけですね。
また、New Token Predictionは基本的に一つのデータに対して1~3回しか行われません(1~3epochという言い方もします)。
それ以上学習させると、過学習を引き起こして性能が低下するか、性能がほとんど上がらないことが知られています。

より引用。左が過学習状態のイメージ。
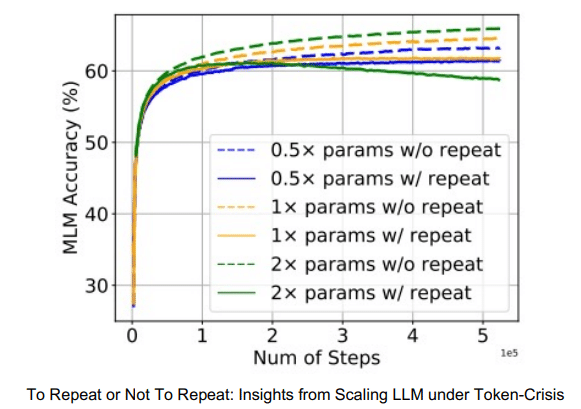
3ステップ(3epoch)以上で性能の増加がほとんど見られなず、
むしろ低下しているものもある
この作業は、聞いている分には簡単そうですが、実際に大規模なモデルで実行してみると、
交差エントロピーが発散する(Lossのスパイク)。
困難なエラーに直面する。
などの問題が発生するため、一筋縄ではいかないそうです。
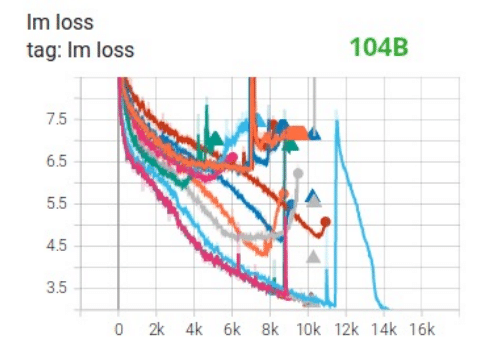
より引用
とがっている部分でロス(交差エントロピー)が急激に増大している。
そこで、学習によって得られるパラメータとは別のパラメータ(ハイパーパラメータ)を手動で設定しておくことで対策します。
具体例としては
Optimizer
Scheduler
浮動小数点精度
Batch Size
などがあります。
(そういえばSchedulerはStableDiffusionでもよく見かける。)
具体的な説明は余力があれば…(これを書いている時点で2日目に突入していて心に余裕がない)
④評価
最後に、出来上がったモデルの評価をしなければなりません。
評価の方法には大きく分けて以下の種類があります。
定量評価
Upstream
Downstream
定性評価
サンプル評価
Upstreamは交差エントロピー(Loss)がどれだけ小さいかで評価する方法です。
データサイエンスの分野に片足を突っ込んでいる方は気付くかと思いますが、このLossというのも何種類かあって、
Training Loss
学習に使ったデータセットにおける交差エントロピー
一番用意が簡単(というかもはや何もしなくていい)
過学習しているとあてにならない
場合によっては使われる
Validation Loss
学習に使うデータセットのうち、一部を利用せずに切り離した上で、それを完成したモデルに当てはめた際の交差エントロピー
過学習に多少強い
大体コレが使われる
Test Loss
学習に使うデータセットとはもう完全に別のデータセットを用意して、完成したモデルに当てはめた際の交差エントロピー
過学習にめっちゃ強い
論文上では使われることはほとんど見られない
また、補足として、式変形したら交差エントロピーと実質同じになる指標として
Perplexity(PPL)
Bits-Per-Character(BPC)
Bits-Per-Word(BPW)
があります。
Downstreamは、実際にIn-Context Lerningを交えながら、下流タスク(最終的に解きたいタスク)を用いて評価する方法です。
以上が定量評価となりますが、もう一つ上げている定性評価では、実際にテキストとして出力してみる方法があります(そりゃそうか)。
ここで、先ほどTransformerの出力層の説明で、求まったのが「確率分布」という話をしたことを振り返ってもらうと、実際に文章を生成するには、その確率分布に従って単語を選んでいく必要があることが分かると思います。
この作業をデコードと言います。
名前の通り、脱(De)コード(Code)化するわけですね。
④'デコード方式
この方式にも3種類ほど代表的なものがあります。
Greedy Decoding
次に来る単語だけを見て、一番確率が高いものを選んでいく
分類問題などで主に用いられる
Beam Search
ある一定長さにおいて、もっとも確率の高い単語の連なり(トークン系列)を選択していく
機械翻訳タスクで主に用いられる
Random Sampling
次のトークンの生起確率分布に従い、ランダムに選択する
Top_p,Top_k,Temperatureといったハイパーパラメータを利用する
長文生成で主に用いられる(ChatGPTも確かコレだった気がする)
デコード方式に完璧な正解はなく、場合によって使い分けられています。
終わりに
お疲れさまでした…
いやもう本当に疲れました。
ただ実際、この文章を読んでくださった方は、LLMというもののイメージは少なくともつかめたんじゃないかと思います。
ChatGPTなどのLLMがすっかり普及した現在でも、ここまでしっかりその原理について学んでいるのはかなり少数ですので、この時点ですごいと思います。
それと、めっちゃ駄文になってしまいすみませんでした。
一回の投稿でLLMのアルゴリズムと事前学習を一気に解説しきるというのにそもそも無理があった気がしてなりません。
これを一回の授業で学んだ昨年夏の私は一体どんな頭の回転をしていたのでしょうか…
余談
文章書きすぎてストレスで頭がおかしくなっているので、今回も気分転換に雑談をします。
ギター趣味を今でも続けているものの、長いことスランプ気味で技術力の向上が実感できていません。
飽き性の自分が2年弱もの間同じ趣味に没頭しているだけでも十分快挙ではあるんですが…
最近は、使えもしないくせにエフェクターボードを組みたくなる衝動を抑えながら、故 神田沙也加さんの歌う「Break Beat Bark!」を練習し始めました。
メイン機が不調なので弟からもらったHistoryのストラトを使っていますが、パワー不足感が否めません。
リアだけシンハムに変えたい気持ち也…