SansanのHR ops xデータドリブンが衝撃的だった

【T-2】元マーケターが挑む、データドリブンな採用戦略への転換
登壇者:Sansan株式会社 人事本部 CHRO室 戦略人事グループ 石橋 政幸 氏
概要
本セッションでは、マーケティング領域でのキャリアを経てSansan株式会社に入社し、その後人事本部へ異動した石橋氏による、データドリブンな採用戦略構築の取り組みが紹介された。

石橋氏は、自身がデータエンジニアではないという状況ながら、社内に専門的なエンジニアリソースが乏しい中で外部リソースやツール、知見を活用することで、採用活動に必要なデータ基盤を自ら整え、採用プロセスを定量的な指標に基づいて改善していく事例を提示した。
加えて、採用データを起点として人事全体の生産性向上や中長期的なタレントプール戦略への展望も示され、バックオフィス部門がデータによって収益貢献する可能性を提示する興味深い内容となった。
背景および課題
Sansan社はここ数年で約700名以上の大幅な人員拡大を行い、急速な事業成長に伴い採用戦略の高度化が求められていた。同社では営業や契約などの事業データが豊富に活用されている。

一方、採用領域では「気合と人海戦術」「属人的な判断」「コストをかけたエージェント依存」など、データに基づかない非効率な手法が目立っていた。既存の採用プロセスでは、各ステップの応募数、面談数、通過率など基本的な指標さえ容易に取得できず、採用組織全体でPDCAを回すことが困難だった。
また、SansanはSaaS業界特有の指標である「Rule of 40(前年度売上成長率+利益率が40%以上)」の達成を目指し、戦略的な人材配置や配置スピードが経営的な課題となっていた。こうした動きに追随するためには、採用計画をより精緻に、そして定量的なデータに基づいて立案・実行することが急務であった。
しかし、当時の採用組織では、応募者管理システム(ATS)などの基幹データが整備不足で、データの欠損や表記ゆれ、メタデータ(データ定義)の不在、複数ダッシュボードの乱立といった課題が山積みであった。
どこにどのデータがあるのか
何が基準か
応募者をカウントするのか
といった基本的な問題をクリアしない限り、データドリブンな採用活動を目指すことは難しい状況だった。
初手はgoogle spread sheetから
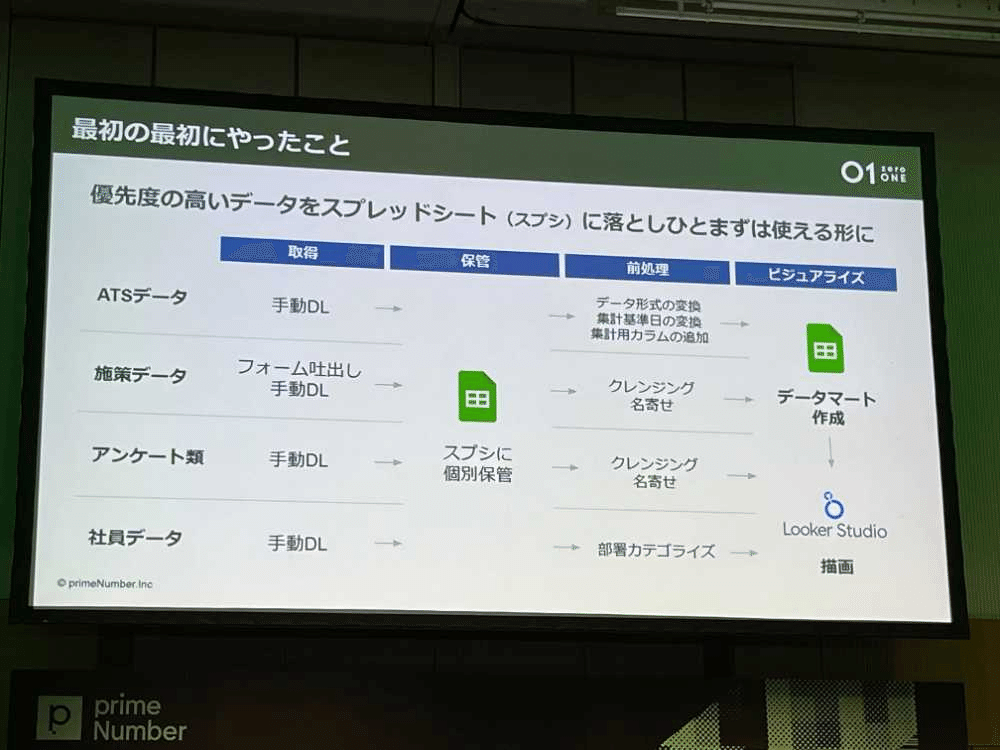
初手は手動で各システムのデータを中央集権スプシに集中させ、データを関数で整形し、データマートの形成を行った。

しかし、スプシが重かったり、1000万セル上限にあたり利用不可、looker studioとの連携が不安定、子シートの管理が煩雑など様々な運用上の課題にあたった。
データドリブン化に向けた具体的な取り組み
1. 専門エンジニア不在環境でのデータ基盤構築
石橋氏自身はマーケティング畑出身であり、データエンジニアとしての知見はなかったため、社内エンジニアへの依頼も検討した。しかし、個人情報や給与など人事特有のセンシティブデータへのアクセス制約があったため、権限整備を待つよりは自力でやるほうが早いと判断。

外部の技術ブログや知見を参考にし、自らがTROCCO、BigQuery、スプレッドシート、Google Looker Studioといったツール群を組み合わせることで軽量なデータ基盤を独力で構築。
TROCCOを用いてATSデータをBigQueryへ日次で同期し、SQLでデータマートを作成したうえでLooker Studioによる可視化ダッシュボードを用意するなど、段階的な整備を行った。
当初はExcel関数やスプレッドシートによる手作業のデータ整形からスタートし、非効率や処理遅延、Looker Studioとの連携不安定性、データ行数上限など多くの制約に直面したが、試行錯誤を通じて徐々に自動化・安定化を実現していった。
2. データの起点となるATS(Applicant Tracking System)の整備
採用活動において最も中核となるデータはATS上に存在する。求人ごとの応募者数、面談実施数、通過率など、まずはATSに入力された基本情報を整え、これらを正しく抽出・集計できる環境を整備した。

データドリブンにするためにATSを入れ替えた。talentioとの連携もtroccoを利用して一日差分でBQにデータ同期するように。

採用オペレーションにおいては、30名以上いる採用アシスタントが正しくATSにデータを入力することが肝要であり、オペレーション設計の見直しも並行して行われた。
3. データ品質・メタデータ管理と指標定義の明確化

データ基盤を整える過程で最も重要だったのは、「応募」「面談」と言った言葉の定義を共有・合意することだった。例えば、候補者がATS上に記録される時点で「応募完了」とみなすのか、あるいは特定のステータスになった時点なのか。こうした定義のブレは、分析結果を歪めてしまう。

また要件としては以下のような要件を掲げデータクレンジングを含めたデータ整備を行った。
使えるデータを扱いたい
労務などのデータとも組み合わせて分析したい
非エンジニアでも管理できる状況にしたい

Notionを用いて指標定義やメタデータ管理を行い、採用チーム全体で共通理解を確保。
必要なデータは何か
今後取りたいデータは何か
どのような切り口で分析するか
といった設計を明文化することで、継続的なPDCAが可能な状態を作り上げた。
4. 非エンジニアが扱える運用環境の確立
石橋氏はデータエンジニアではないからこそ、「非エンジニアでも扱える」ことを重要視した。権限設定に時間を要したり、高度なスキルが必要なインフラ構築に踏み込むのではなく、低コード・ノーコードツールやSaaSを活用することで、スモールスタートを実現。採用担当者が自発的にダッシュボードを参照し、必要なデータを取得して戦略検討できる環境を作り出した。
得られた効果と活用事例
1.データに基づくPDCAサイクルの定着

整えられたデータ基盤によって、採用コストや通過率を指標として、スカウト媒体別の効果を明確化できるようになった。これにより
どの媒体で、どの職種向けにスカウトを打てばよいか
応募数と内定承諾率を改善するには、どのステップで工夫が必要か
を客観的かつ継続的に検証可能となった。PDCAが回り始めることで、採用計画の見直しや採用コストの最適化、要件定義の改善がデータに基づいて行えるようになった。
2.農耕型アプローチへの転換:タレントプール戦略
従来は欲しい人材が必要な時にエージェントへ依頼し、コストをかけて人材を「刈り取る」狩猟採集的な採用スタイルが主流だった。
データ整備によって「応募以前」に接点を持ち続けられる「農耕型」のアプローチが可能になった。説明会やイベント参加者でまだ応募していない優秀な候補者の情報を継続的にプールし、コンテンツ配信や情報発信を通じて数年単位で関係性を醸成しておくことで、将来的な採用成功確度と内定承諾率を向上させられる見込みが出てきた。
今後の展望
採用部門での成功事例は、人事全体へのデータ活用展開の呼び水となりつつある。
給与、評価、労務など、人事部門が扱う他のデータとも結合し、中長期的には「マスターID構想」によるデータ一元管理を目指すことで、さらに精緻な人事戦略立案が可能となる。

例えば、給与水準を定量データと外部環境データで見直し、オファー内容の最適化や承諾率向上を図るといったアクションが増える見込みである。これによって、バックオフィスが単なるサポート部門でなく、データに基づいて直接的に事業成長や収益性向上に寄与できるパートナーへと変容していく。
今後は、現状整備した基盤をもとに、より広範な人事データ活用に取り組む予定である。まだまだ存在するデータサイロを解消し、マスターID構想を進めることで、採用データのみならず給与や評価などのデータも一元的に管理・分析できる理想像を実現したい考えだ。これにより、採用計画や要件定義がより迅速かつ精確になり、会社の成長ステージに合わせた人材投資の戦略的最適化が可能となる。
また、データドリブン化の過程で石橋氏が強調したのは、「気合・経験・度胸」も依然として重要であるという点である。ツール選定やナレッジ参照などのHow(手段)に加えて、未知の領域に踏み込んでいく行動力や粘り強い試行錯誤、チーム全体を巻き込んでオペレーションを改善する力といったソフトな要素も不可欠である。技術的なDXと人的なDXを並行して進めることで、真にデータドリブンな組織変革を実現することが可能になる。
まとめ
本セッションは、採用組織でのデータドリブン化がエンジニア不在でも実現できることを示す好例であった。データドリブン化は単に可視化や分析で終わるのではなく、組織の考え方や行動パターンを変え、バックオフィス領域からでも事業成長に直接的なインパクトを生み出せることを示した点で、本セッションは非常に示唆に富むものであった。
所感
SanSanのHR opsの実例を聞いてお腹いっぱいになってしまって、2つしかセッション聞かずに会社に戻ってこれを書いている。正直にいって「2024年でこのレベルでHR ops回せる企業体が日本にあるんだ」と衝撃を受けた。
人事データは部門ごとに権限が切れやすい構造である。これは単にサイロ化と指摘することが難しい。なぜなら人事データというセンシティブな情報を扱うため権限設計などの根底にある事情がある。一方でDevOps, DataOps, RevOpsに代表されるようなXopsはどんどんと時代の潮流とともにデータドリブンな意思決定をサポートするデータ基盤を求めるようになりつつある。
個人的には、HRでも、エンジニアでも、マーケターでもない中性的な属性の自分が「HR Opsプラットフォーム」のたたき台を作り上げて、より強靭なHR組織の基礎を作ってみたいなと素直に思った。
これまでエンジニアとしてコードを書いていたり、サポーターズで業務システムの整理・改善したり、広報で人事業務に関わっていたり。もしかすると強みと経歴がsyncする領域なのかもなと感じた。
そのために会社に信用してもらってより幅広い領域にタッチすることができれば面白い仕事が出来そうだな、とも直感した。なんだか「将来像としてのあり方」の1つのモデルケースを得た感覚があった。以上。