
建築は「意思決定」の物語である

1章.はじめに
あいさつ
代表の押山でございます。
久しぶりに記事を投稿いたします。おかげさまで株式会社 白矩(しらく)は10月を迎え、無事7年目に突入いたしました。「よくもまあ、こんなに続いたものだ」と自分でも驚いておりますが(笑)、ひとえに皆様からのご依頼あってこその継続でございます。心より感謝申し上げます。
今後とも変わらぬご愛顧をお願いしたく存じますが、いつもご依頼ばかり頂戴するのも少々気が引けますので、この度、会社設立からこれまでの試行錯誤と、その折々の考察、そして到達した結論について、記事にまとめて皆様にご共有させていただくことといたしました。我ながら「これは、少しは役に立つかも」と思っております。
皆様の抱えるお悩みの一助となれば幸い、という思いで筆を進めておりますが、ここから先、およそ2万字の旅が続きます。かなりの長文ではございますが、ぜひお付き合いいただければと存じます。「最後まで読むと、きっと何かが見えてくる」と信じつつ、お読みいただければ幸いです。
自社紹介
さて、弊社を知らない方もいらっしゃるかと思いますので、簡単にご説明いたします。弊社は、建築設計の検討支援を専門とする会社です。主に基本設計から生産設計の段階でご依頼をいただき、設計内容を多角的に考察し、意思決定に必要なデータをご提供しております。

これまでいくつかの建築プロジェクトに関わってきましたが、その中で多くのトラブルに見舞われてきました。先ほどご紹介した業務内容についても、基本的にはプロジェクトの進行中に何かしらの問題が発生し、その解決の一助となるべく、弊社にお声がけいただく──というのが、ある意味でお約束の展開となっております(本当にありがたいことです)。
記事の概要
第2章では、これまで携わってきた建築プロジェクトから、課題として浮かび上がった具体的な事例をご紹介いたします。
第3章では、それらの課題に対し、社内でどのような解決策を検討してきたかをお伝えします。ただし、あくまで内部での対策案であり、それによってご依頼いただいたプロジェクトが劇的に改善されたというわけではございません。
第4章では、第2章と第3章の内容を踏まえ、「諸悪の根源がどこにあったのか」を掘り下げていきます。そして第5章では、今後の建築業界が進むべき方向性についての提案をお届けします。加えて、近年多くの方が注目されているBIM(ビルディング・インフォメーション・モデリング)についても、その導入から10年以上経っても、わかりやすい成果を出せずにいる理由を考察しています。
こうした内容にご興味を持ってお読みくださる皆様なら、きっとご理解いただけると思いますが、これはあくまで私の個人的な仮説であることを念頭に置いていただければ幸いです。
対象とする建築物
今回お話しする内容は、大規模・小規模を問わず、あらゆるプロジェクトに通じるものではありますが、混乱を避けるため、ここでは以下のような建築物を元に考察していることを前提にお読みいただければと思います。
一定規模以上の建築物(おおよそ2000㎡以上を想定)
住宅、倉庫、またはモジュールで対応可能なタイプの建築物以外
このような条件を持つ建築物を対象として、話を進めてまいります。
2章.諸悪の根源は何かを探す旅
始点
私は建築学科を卒業後、3DCADソフト「Rhinoceros」の総代理店であるアプリクラフト社に在籍しておりました。社会人としてのスタートは、主に「モデラー」として、3Dモデルデータの作成に特化したものでした。
その当時、私はRhinocerosの機能であるGrasshopperを活用し、プロダクトから建築に至るまで、大小さまざまな3Dデータを作成していました。Grasshopperは、形状の構成を事前にプログラミングすることで、パラメーターの変更に応じてリアルタイムに形状が変化するという画期的なツールです。日本の建築設計業界でも、おそらく2015年頃から使われ始め、従来の手作業による検討プロセスに革命をもたらすほどの影響力を持っていました。
その頃から、(記憶が定かではありませんが)「コンピュテーショナルデザイン」という考え方が流行し始めており、Grasshopperを使って一体どんな検討が可能なのかを模索していました。また、同時期に建築業界では大手各社がBIM(Building Information Modeling)を導入し始め、BIM推進のための専門部署を設立して、自社のフローにBIMソフトをどのように適用していくかを試行錯誤していました。
そんなあるとき、建築プロジェクトの検討依頼を受けました。しかし、そのプロジェクトは他のプロジェクトに比べて検討フローが明らかに不明瞭で、手戻りや非効率な部分が多く見受けられました。このようなプロジェクトに関わるたびに、「なぜ建築プロジェクトはここまでトラブルが頻発し、なぜ事前にそれを回避することができないのか?その諸悪の根源はどこにあるのか?」と問い続けていました。こうした課題に向き合い、試行錯誤の場として会社を設立したことが、株式会社 白矩(しらく)の始まりです。
Case1:炎上プロジェクトとの出会い
会社設立後、あるアリーナのプロジェクトに関わる機会がありました。この経験が、建築プロジェクトのフローに対して問題意識を持つきっかけとなりました。私が参加したのは生産設計フェーズで、この段階は実施設計と施工の間に位置し、実際に建てられる状態まで実施設計の情報を整理する重要なフェーズです。
依頼内容は、とにかく大量の3Dデータを作成し、検討を重ね、何とか工期までに全体の整理を終えたいというものでした。少し状況を補足すると、このアリーナプロジェクトはスケジュール上では生産設計フェーズにあるものの、実際の設計状況では意匠・構造・設備がまったく成立しておらず、実質的に実施設計をやり直す必要がありました。そのため、まず構造データから3Dデータを作り直し、意匠・構造・設備の整理を一から進める必要があったのです。
本来であれば、実施設計で完了しているはずの内容を、生産設計フェーズで取り戻さなければならず、そのために急ピッチで3Dデータを作成し、検討を進める必要があったのです。結果として、こうした依頼内容となりました。

私は生産設計のオフィスにお邪魔し、担当の方々と「この図面の通りに進めると、ここが成立しないのですが、どう対応しましょうか?」といったやり取りを繰り返しながら、意匠から構造、構造から意匠へと追いかける作業を行い、建築を幾何学的に実現可能な構成として整理していました。この経験は現在の仕事にも大きく影響しており、当時お世話になった生産設計者の皆様には、今でも深く感謝しています。また、その中で「建築を建てるためにはどう考えるべきか」についても多くを学ばせていただきました。
こうした、本来生産設計で行わないはずの検討を改めて求められるような状況のプロジェクトを、私は「炎上しているプロジェクト」と呼んでいます。
意匠、構造、設備のギャップ
なぜこのような問題が発生するのでしょうか。ある規模以上の建築やユニークなデザインを提案する際、ある意味で避けられない宿命ともいえます。主な原因は、意匠、構造、設備の各検討の速度に差があり、それによって不整合が生じてしまうことにあります。
建築設計は、意匠・構造・設備がそれぞれ情報を伝達し、何度もサイクルを繰り返しながら進行していきます。
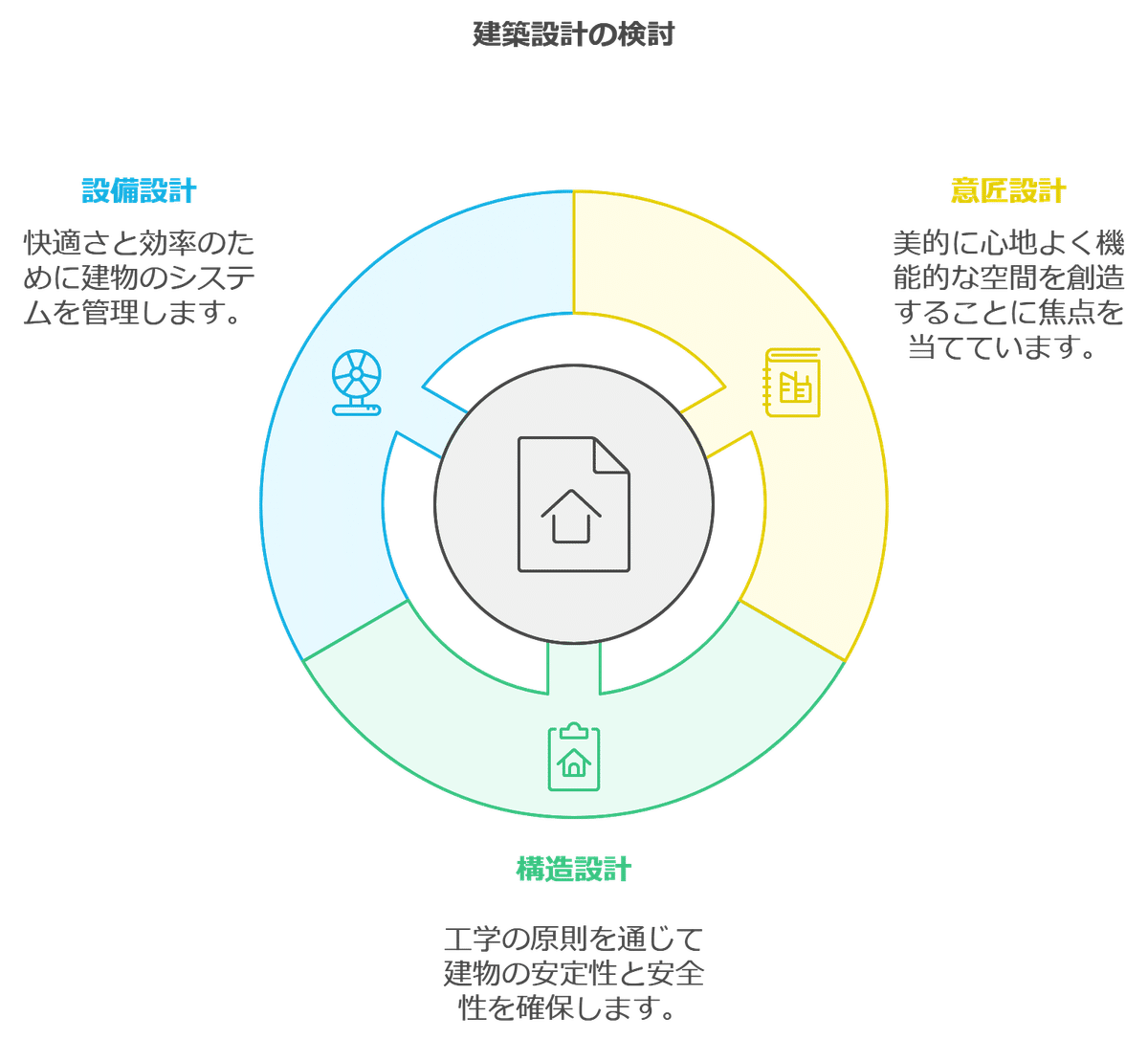
しかし、実際にはそのサイクルをうまく回せていないのが現状です。
具体的には、まず意匠設計がクライアントとの協議を経て検討され、その後、実現に必要な構造設計が構造設計者に渡されます。そして、意匠と構造をもとに設備設計が行われます。。
設備の検討が一巡する頃には、1ヶ月以上が経過していることも多く、その間に意匠設計者とクライアントは再び協議を重ね、新たな案が構造設計者へ渡されます。ここで多くの設計者が見落としがちなのは、構造計算ソフトの特性です。CADソフトのように部分的な修正が容易ではなく、操作も直感的ではないため、意外に修正には手間がかかります。そのため、「少しの修正で済んだ」と意匠設計者が考えていても、構造設計では一部を変更するだけで全体を再検討しなければならないことが多いのです。また、設備設計にデータが渡る前にさらに意匠が変更されるケースも少なくありません。
このような繰り返しの結果、意匠・構造・設備の不整合がどんどん拡大していきます。各分野の検討は、1つ前、あるいは2つ、3つ前の案に基づいて進められ、意匠設計者はそうした状況を理解しつつ修正案を提案していくことになります。このような問題は、大規模なプロジェクトや意匠設計者が挑戦的なデザインを提案する場合に特に発生しやすいです。
主な原因は前述のサイクルの問題ですが、技術的な観点から言えば、2Dでの検討では確実に整合性が取れなくなるという点があります。簡単に言えば、ある面が2軸以上の回転を必要とするような場合、2Dでの検討をあきらめて3Dのみで検討するくらいの割り切りが必要だと思います。
例:曲面上に並べたルーバーの下地を鉄骨までつなげる場合
ファスナーの設置面、ファスナーベースの設置面、接続するアームの面が全ての箇所で異なるため、2D図面で確認することが実質的に困難

他にも検討スピードに起因する問題はいくつかあります。
スケジュールがタイトすぎる要求/詰め込み過ぎな要求:これにより、様々な部分で手が回らなくなるケースがあります。
ソフトウェアの特性:意匠設計者が使うソフトは基本的に直感的に操作できるものが多いですが、構造用や設備用のソフトではそのような検討がしづらいという点があります。
各分野間の理解不足:各分野がどのように検討を進めているかをお互いに十分理解していないことがサイクルを妨げているケースがあります。
課題1
建築設計はその性質上、意匠、構造、設備の検討速度に違いがあるため、その差分が建築の整合性を担保できなくなる。
Case2:不透明な検討経緯とデータの関係性
次に関わったのは、規模の大きな再開発プロジェクトでした。このプロジェクトも生産設計フェーズからの参加となり、すでに炎上状態にあったものです。ここでの課題は、ステークホルダーの増加によるコミュニケーションの複雑化でした。規模が大きく、条件や形状が複雑な建築を建てようとすると関わる人が増えますが、ここではコミュニケーションの整理が不十分なまま進行した結果、各所で齟齬が生じてしまいました。必要なデータが何か、誰がいつどのような経緯で作成したものかが不透明なまま、検討が進められてしまったのです。

データの時系列や作成意図が曖昧であるため、不要な検討や目的不明の作業が発生し、「とりあえず一度作ってみる」という前提で進めざるを得ませんでした。その結果、膨大なデータが生成される一方で、マンパワーで補う状況に陥り、検討の速度に対してデータ生成が追いつかない事態となりました。
確認事項の整理ができていないため、分科会や事前協議といった場は常に長時間化し、関係者間での情報整理も滞りがちでした。そのため、データを作成する側・確認する側ともにミスが発生しやすくなり、エラーが次々と連鎖するスパイラルに陥ってしまったのです。
この問題の主因は、検討経緯やデータ作成者の履歴が管理されておらず、追跡ができないことにありました。その結果、ミスが積み重なり、検討経緯が不明確なままデータが増えるばかりで、混乱が拡大していく感覚がありました。
課題2
・検討の経緯が不透明になる
・検討の速度にデータ生成が追い付かない
・検討の経緯と検討データの関係性に齟齬が生じる
Case3:記憶の限界と分岐する選択肢
続いて関わったのも再開発プロジェクトでしたが、今回は前回と異なり、基本設計フェーズからの参加でした。
ここでの課題は、検討内容が分岐して増加し、長期間にわたることで意思決定の経緯が忘れられてしまうことでした。これは人間であれば避けがたいもので、ある程度仕方のない部分でもあります。
私たちは、これまでの経験からモデル生成の高速化が可能となり、発注者側もより良い建築を目指してさまざまなパターンを検討するようになりました。発注者自身が建築を理解する上でも多角的な検討は有益です。
しかし、建築には多様な検討箇所があるため、各バージョンや分岐が増えると、それぞれの関係性や整合性が曖昧になるリスクが生じます。さらに、今回もステークホルダーが多く、生産設計フェーズに移行する際には、新しいメンバーが改めてこのプロジェクトを理解する必要があります。
その際、「なぜこの箇所はこうする必要があったのか?」という意思決定の経緯が追えないことが問題です。それらを安易に変更してしまうと、後々トラブルになる可能性があります。一見無駄に見える部分でも、実は法規を守るためや他の箇所との兼ね合い、製造上の条件によるものであったりするからです。
要するに、正確かどうかわからない記憶に基づいて新たな意思決定を行う危うさがここにはあります。そのため、設計段階でも、参加メンバーの記憶に頼ってすり合わせを行い、記憶が曖昧な場合は推測で補完して次の意思決定をしていました。もし前提が間違っていた場合、その問題は放置され、後になって顕在化したときには手遅れになる可能性があるのです。
課題3
・検討パターンの管理
・検討の経緯の忘却
3章.対応策を考える
2章で挙げた課題を踏まえ、この章ではそれぞれの課題に対する対応策についてご紹介します。
課題1:意匠と構造のストーリーを理解するための取り組み
課題1
建築設計はその性質上、意匠、構造、設備の検討速度に違いがあるため、その差分が建築の整合性を担保できなくなる。
これらの問題を理解するために、夏目さんにご協力いただき、「意匠と構造のストーリーを理解する シリーズ」シリーズの記事で、このような状況がなぜ生じるのかを考察しました。この取り組みにより、意匠と構造の整合性が不安定だと、設備設計にも大きな影響が及ぶこと、また構造設計側でどのような苦労があるかを理解することができました。

特に重要なのは、設計初期段階で構造の大きな方向性(ストーリー)を決めることです。これが後になって破綻すると、プロジェクトが炎上するリスクが高まります。また、構造のソフトウェアでは、検討の性質上データ修正の自動化が難しいため、構造にデータを渡す際は「清書を書くつもりで」渡した方が良いという結論に至りました。

そのため、できるだけ意匠側のソフトで簡易的な解析を行うことが望ましいと考えています。これにより、意匠と構造の検討回数(エスキス回数)を増やしてギャップを抑えつつ設計を進めることが可能になります。結果として、ズレが減ることで設備設計へのデータの受け渡しもスムーズになります。
構造計算ソフトでの検討は非常に負担が大きいため、できる限りその負荷を軽減しながら進めることが重要です。意匠の更新に構造が追いつかず、その影響で設備設計も遅れるという悪循環がありましたが、この解決策として、意匠側で構造の芯線のみを生成しておくことが有効であることがわかりました。技術的には、意匠ソフトと構造ソフトの連携は進展しており、今後もこの改善が期待されます。
対応策
・意匠の方で構造の芯線だけ用意しておく
モデリング計画と半自動化
課題2
・データ同士の関係性が不透明になる
・検討の速度にデータ生成が追い付かない
・検討の経緯と検討データの関係性に齟齬が生じる
1つ目の課題である【データ同士の関係性が不透明になる】ことへの対応策として、これまでのデータ作成方法を見直しました。従来は、打ち合わせの際に議題となった内容を1つのファイル内で修正し、さまざまな検討内容を1つのファイルに集約していました。この方法では、「どのデータを元に何が作られたのか」が不明瞭になりやすかったのです。

データの関係性を整理するため、モデリング計画を行うことにしました。あまり聞きなれない言葉かもしれませんが、要はデータ同士の依存関係を整理した上でモデルを作成していきましょう、というデータの作成手順です。

データの関係性を要素別に見ると、A、B、C、Dというファイルに分かれています。Aが生成されるとBが作成でき、AとBが揃うとCが作成できる、といった依存関係を明確にすることで、建築の幾何学的な優先順位が見えやすくなり、意思決定の優先順位にもつながる考察が可能になりました。
また、A、B、C、Dごとにデータを分けて保存する際、単にフォルダごとに保存するだけでは依存関係が分かりづらくなるため、モデリング計画図にファイルのリンクを貼ることで、データ同士の関係性が直感的にわかるようにしました。こうすることで、どのデータが何を元に生成されているのかが一目で理解できるようになります。
しかし、これだけでは2つ目の課題【検討の速度にデータ生成が追い付かない】には対応できません。そのため、モデリング計画を活用し、これらを半自動化することで、データを順に生成できるようにしました。以下の画像が、実際のモデリング計画の記述です。データは上から下へと作成されます。ファイルを修正した際にはコメントを入れて修正するようにしています。

一定規模以上の建築プロジェクトでは、扱う要素も多いため、2D・3Dデータを迅速に作成する手法を検討する必要があります。また、建築の検討には、建築的な観点とデジタルデータを作成する観点の両方から考えるアプローチが求められます。ここで重要なのは、モデリング計画に基づいてデータを要素ごとに分解したプログラムを作成しておくことと、半自動化という余白を持たせておくことです。
建築の検討箇所は非常に多く、仕様や形状のルールも頻繁に変わります。そのため、以前の検討形状をまとめて一括で生成する大規模なプログラムを作成してしまうと、かえって時間がかかり、非効率になります。この方法のメリットは、プログラムがデータごとに分かれているため、エラーが見つけやすく、修正がしやすい点にあります。
人海戦術でモデルを繰り返し作成すると、同じようなモデルであっても作成者ごとに癖やヒューマンエラーが生じるため、完全に整理したりエラーに気付くことは難しくなります。そうした点でも、人が直接データを作成する作業を極力減らすことで、検討効率が大幅に向上したと実感しています。
下記の動画は、モデリング計画をそのまま実行した単純な例です。「柱の芯線⇒梁の厚み⇒柱の厚み⇒屋根の厚み⇒壁の厚み」というような順序で生成しています。これは生成する箇所ごとにファイルを分けているので、もし生成の順番が変わる場合は、それに応じて組み替えて使用します。


チェックリスト
3つ目の課題、【検討の経緯と検討データの関係性に齟齬が生じる】については、前述の課題解決策の延長にあたります。モデリング計画や半自動化したものの、「このデータは誰が、いつ、どのような経緯で検討したものか」という履歴が共有されていないという問題が残っていました。実際には各社が自社に必要な分だけの履歴を持っているかもしれませんが、全体を俯瞰して経緯を把握することが難しいのです。
プロジェクトが長期化すると、当然ながら人は記憶が曖昧になります。その度に集まって「これは何のために誰が作成したデータか?」と確認し合うことが必要になりますが、これが非常に困難です。そこで、対応策として「チェックリスト」を作成しました。

チェックリストでは、打ち合わせでの検討内容やメール、チャットなどのやり取りを「1問1答」の質疑応答形式でまとめています。こうすることで、「この数値はなぜこうなっているのか?」や「この設計はどうしてこうなったのか?」といった質問に対して、誰が質問し、誰が回答したのかを含めて履歴を追えるようになりました。
さらに、1問1答のチェックリストには先ほどのモデリング計画で生成されたファイルのリンクを紐づけておくことで、その時やり取りしたデータも見ることができます。これにより、誰がどのような経緯でデータを作成し、どのような結果に至ったのかが分かるようになりました。また、このチェックリストを分析することで、プロジェクト全体の傾向や改善点も把握しやすくなります。これらの取り組みは、設計支援を行う際に非常にありがたがられます。

対応策
・データ同士の関係性が不透明になる
・検討の速度にデータ生成が追い付かない
の2つの課題には、モデリング計画、半自動化により対応
・検討の経緯と検討データの関係性に齟齬が生じる
チェックリストにより対応
検討パターンの記述と検討経緯の抽出
課題3
・検討パターンの管理
・検討の経緯の忘却
データ生成の高速化による、様々な検討パターンの可否は、建築の質を向上させる点で効果的です。しかし、建築には多くの検討箇所があり、それぞれにAパターン、Bパターン、Cパターンと複数のバリエーションを作成すると、他の箇所との兼ね合いで非常に複雑化します。その結果、検討パターンの管理が困難になるという問題が生じました。
この課題に対処するために、定期打ち合わせに合わせて、その回に作成したモデルの検討内容をまとめる資料を作成しました。また、そのモデルがどのチェックリストに対応したものなのかを紐づけることで、検討パターンと経緯を整理しやすくしています。

各案のパターンの、データには反映されないものの、打ち合わせで話し合われた素材や仕様なども含めて内容を整理し、検討パターンに紐づけています。こうすることで、チェックリストから「この発言や決定はどの案に対するものだったのか?」を追えるようになりました。
検討の経緯の抽出
チェックリストがあることで、検討の経緯を尋ねられた際、依頼範囲内であれば「それは○○のときに○○さんがこのように話していて、現在も保留の状態です」と、その時の資料を添えて返答できるようになりました。チェックリストが増えるにつれて、質問に対して適切な回答を探すのに時間がかかるようになり、これが2つ目の課題である【検討の経緯の忘却】につながっています。
膨大な検討記録やステークホルダーの発言がチェックリストには残っているものの、すべてを記憶しているわけではないため、頼りになるのは曖昧な記憶や議事録、そしてキーワード検索です。しかし、議事録から該当箇所を見つけるのは手間がかかり、またキーワード検索も人によって異なる名称や表現が使用されるため、必ずしもヒットしないという問題がありました。
(※これらを考慮し、基本的に名称を統一するよう提案はしています)
こうした背景から、【検討の経緯を素早く抽出する必要がある】必要性が生じ、解決策として、チェックリストをデータベースとするチャットボットならぬ「チェックボット」を作成しました。(チェックリストにちなんで)。

チェックボット
チェックボットはGraphRAG(Graph-based Retrieval Augmented Generation)を活用した検索機能により、質問の内容からチェックリスト内の意味的に近い内容を抽出します。例えば、「防火区画の検討について教えて」と質問すれば、防火区画に関する過去の検討内容を、チェックリストの質問・回答部分からもっとも関連性の高いものを返答します。また、回答の際には参照したチェックリストのIDも併せて返し、どの1問1答に基づいた返答かがわかるようにしています。(あくまでプロトタイプです)
※※GraphRAGとは、グラフデータベースを活用して関連性の高い情報を効率的に抽出する技術です。
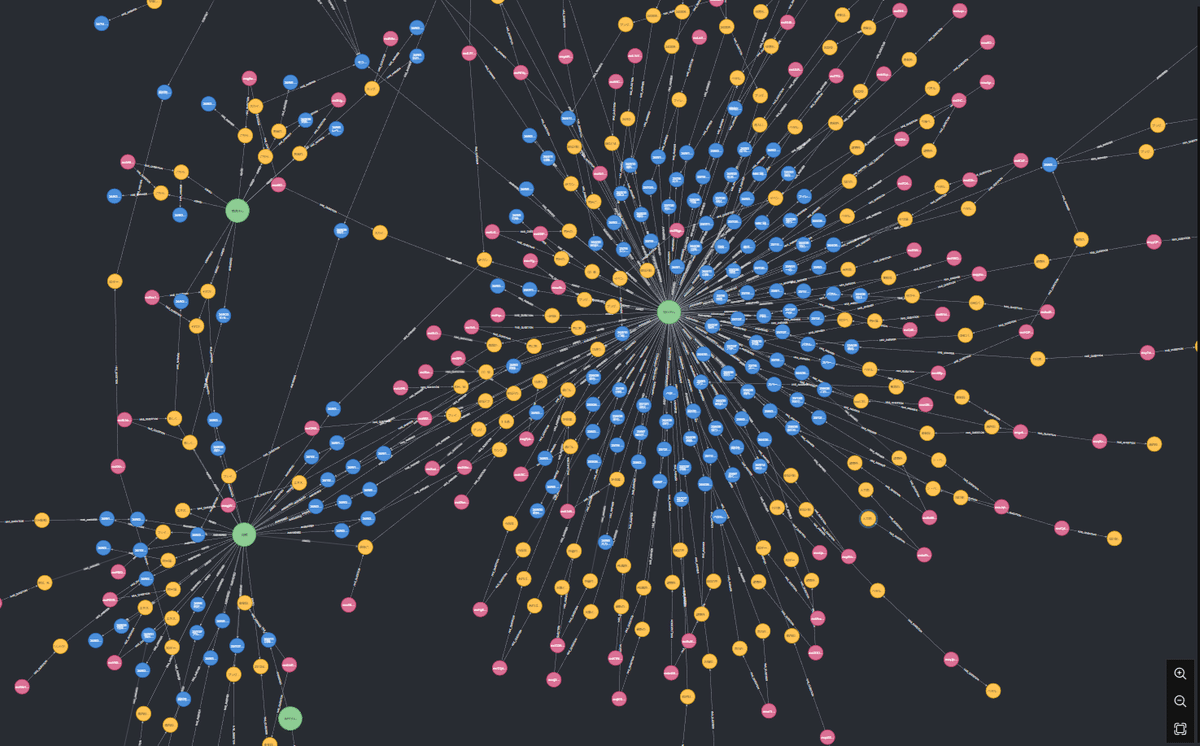
この仕組みにより、質問があればまずチェックボットに入力し、調べる手間を大幅に短縮できるようになります。将来的には、「○○さんが○○について述べた意見をまとめて」や「8〜12月の検討内容を教えて」といった、より高度なリクエストにも対応できるようになると考えています。

対応策
・検討パターンの管理
チェックリストをグループピングして検討経緯のまとめ資料と紐づけることで対応
・検討経緯を素早く抽出
チェックボットにより対応
4章.諸悪の根源と展望
課題と対応策の整理

課題1.「意匠・構造・設備によるギャップ」
対応策: 意匠側で構造の芯線だけでも用意しておくことや、構造のストーリーを明確にするなど、検討フローの見直しを行いました。
課題2.「データ同士の関係性が不透明になる」、「検討の速度にデータ生成が追い付かない」
対応策: モデリング計画、ファイル同士の関係の記述よって対応しました。
課題3.「検討の速度にデータ生成が追い付かない」
対応策:半自動化によって対応しました。
課題4.「検討の経緯と検討データの関係性に齟齬が生じる」
対応策: チェックリストの作成を行い、検討内容とデータの関係性を明確にしました。
課題5.「検討パターンの管理」
対応策: チェックリストに検討経緯の資料を紐づけ、検討グループを与えることで対応しました。
課題6.「検討経緯を素早く抽出」
対応策: AIを活用してチェックリストをボット形式で検索・抽出できるようにしました。
諸悪の根源は何だったのか?
ここまで読んでいただいた皆様であれば、そろそろお気づきかもしれませんが、もう少しお付き合いください。これまでの対応策を図式化すると、検討の経緯であるチェックリストに建築の各情報が紐づいていることがわかります。

建築の各データは、検討の経緯であるチェックリストから生成されています。検討の経緯とは、さまざまな検討における意思決定の積み重ねであり、そしてその繰り返しによって設計がまとめられ、この繰り返しによって設計がまとめられ、最終的には建築が完成へとつながっていきます。当たり前のことのように思えますが、ここが重要なポイントです。
建築データは細かく見ていけば意思決定に基づいて生成されるものであり、意思決定なしには存在しません。私たちの問題は、データの出所や検討目的、基準が不明確なままデータを生成し、その積み上がったデータから過去の検討経緯を推測せざるを得なかったことです。つまり、私たちの問題は、常に意思決定に起因していたのです。
ところが、私たちは意思決定を次の意思決定につなげる仕組みがなく、誤ったデータを生成していたのではないでしょうか。それは知らず知らずのうちに、「壮大な意思決定の伝言ゲームに失敗し続けてきた」という状況です。

なぜ伝言ゲームに失敗し続けるのでしょうか?その原因は、過去の意思決定を集約したデータベースが存在せず、それぞれが個人の脳内に履歴を保存していたことにあります。人は忘れる生き物であり、忘れた部分は推測で補うしかありません。そのため、会議という場で意思決定の履歴を思い出し、すり合わせ、新たな意思決定を行う必要があるのです。しかし、繰り返しますが、人間は忘れます。推測が外れてしまった場合、それは意思決定の履歴が改ざんされてしまった事とそう変わりません。
こうして、知らず知らずのうちに誤った意思決定が新たな意思決定の基礎となり、結果的に誤ったデータが生成されます。そのようにして蓄積されたデータは、検討経緯を追うことができないのは当然のことでした。こうして原因不明の問題が積み重なっていき、問題が発覚した時には手遅れととなるのです。私たちはこうした状況を繰り返してきたと考えられます。
結論として、諸悪の根源は、「議事録のフォーマットが古い」ということです。
議事録は多くの場合、個々の業務に関わる情報のみが記録され、フォーマットもバラバラです。トラブル時の証拠としての役割が強調される一方、意思決定の経緯を確認するためのものとしては使いづらいものでした。この理由から、今回の対象とした建築物には、規模が小さいものや複雑でないものを除外しました。少人数のプロジェクトであれば、従来の方法で意思決定の履歴を維持できますが、一定規模以上の建築プロジェクトでは、意思決定の紐づけを会議やすり合わせのみで行うことは難しいのです。
従来、日本の建築業界はお家芸として、コミュニケーションの力で意思決定の紐づけを行ってきましたが、インターネットや3D CADの普及、建築の高度化・複雑化に伴い、コミュニケーションだけで行うこと自体に限界がありました。また、この業務は各人のコミュニケーションによって成立していたものであり、職能としては存在していなかったため、機能不全を起こしていても気づくことができませんでした。そのため、問題が生じてもすぐには気づけず、責任の所在をめぐる押し付け合いに陥りがちです。実際には、ステークホルダー全員が意思決定の履歴を共有せず、互いに「改ざんされた」情報を扱っているともいえるでしょう。
もう一度言いますが、全体の意思決定を一元的に紐づける職能は存在しないのです。これがさまざまな問題を隠蔽し、気づいたときには大きなトラブルへと発展しているのです。
議事録としての超線形設計プロセス
超線形設計プロセスとは、私の師である藤村氏が提唱した建築設計の手法です。私はこの試みを知りながら、なぜ今回の結論に至るまでに7年もかかったのか、不思議に思います。(笑)超線形設計プロセスを簡単に説明すると、意思決定の積み重ねを視覚化し、検討を重ねる手法です。

The Super Linear Design Process Theory: Towards New Contextualism | Ryuji Fujimura
掲載『10+1』 No.48 (アルゴリズム的思考と建築, 2007年09月30日発行) pp.161-166

The Super Linear Design Process Theory: Towards New Contextualism | Ryuji Fujimura
掲載『10+1』 No.48 (アルゴリズム的思考と建築, 2007年09月30日発行) pp.161-166
このプロセスはまさに新しい形の議事録と言えます。藤村氏はこれを発展させ、複数の人々が関わる公共建築のワークショップにおいて、意思決定の経緯を並べることで合意形成につなげる手法を実践していました。私は長い間、これを3D CADで並列処理して検討すれば、建築検討で起こる問題は解消されるだろうと漠然と考えていましたが、ここで重要なのは意思決定を視覚化すること自体ではありません。むしろ、大量のデータを生成して提示するだけでは根本的な解決にはならないという点でした。
では、藤村氏が提示したものとは何だったのでしょうか。藤村氏の超線形設計プロセスは、発注者が理解しやすい形に落とし込んだ、「発注者用の議事録」の発明でした。そのため、このプロセスには「ジャンプしない」「枝分かれしない」「後戻りしない」というユニークなルールがあり、発注者にとっては設計経緯を簡潔に理解できる形式となっています。これまでの発注者は、設計者が提出するものを鵜呑みにするしかなく、なぜそうなったのかは分からないまま、「先生が言うなら正しいのだろう」と進めるしかありませんでした。藤村氏は、検討経緯にフィルターをかけて発注者と共有することで、多様な関係者からの合意形成を得る手法を生み出していたのです。その意味で、藤村氏の発明は革新的だったと言えるでしょう(同じような指摘をすでにしている人もいるかもしれません)。
しかし、この超線形設計プロセスは発注者側の議事録としては機能する一方で、実務者用の議事録としては機能していません。なぜなら、建築形状に関する意思決定の「なぜ分散する必要があるのか?」「なぜ角のラインを通すのか?」という経緯を追うのは、前述の伝言ゲームの失敗により困難だからです。つまり、今後建築業に必要なのは、実務者用の議事録をアップデートすることです。
BIMがなぜうまくいかなかったのか
これまで、建築プロジェクトにおけるさまざまな課題に対して試行錯誤を続ける中で、3Dデータからのアプローチに限界を感じていました。私は、3Dデータが正しく更新されれば問題は解消されると信じていました。しかし、今ではそれこそがBIMの罠であり、BIMソフトの罠だったのだと感じています。まず、BIMとは何かを改めて確認しましょう。BIMの触れ込みはこうでした:
「BIM(Building Information Modeling)とは、コンピューター上に作成した3次元の建物のデジタルモデルに、コストや仕上げ、管理情報などの属性データを追加した建築物のデータベースです。建築の設計、施工から維持管理までのあらゆる工程で情報を活用するためのソリューションであり、現在主流になりつつあるワークフローです。
BIMを実現するソフトを使って3次元モデルを作成し、設計から施工、維持管理に至るまで、建築ライフサイクル全体でモデルに蓄積された情報を活用することで、業務の効率化や建築デザインのイノベーションを促進する、画期的なワークフローとされています。」
しかし、これまでの経験を通じて理解できたのは、これらの理想が現実には実現できていないということです。最大の問題は、多くの人々がBIMソフトを通してこれらの理想を実現しようとした点にあります。
特に深刻なのは、幾何学的な形状から意思決定の経緯を追えないという点です。BIMソフトは3Dモデルの作成や属性情報の付加に優れていますが、設計プロセスにおける意思決定の履歴や背景を効果的に伝える手段としては限界があります。私は、BIMソフトが話をややこしくしたのではないかと考えています。BIMソフトは結局のところ、仕上げ表や図面作成の効率化ツールに過ぎません。最近では360度ビューの共有ツールも登場していますが、これはクラウド上でデータを共有して閲覧できるというものであり、議事録のフォーマットを革新するものではありません。
本来、BIMは「概念」や「思想」として捉えるべきものでした。しかし、この点の整理ができていないために、「BIMを導入した(ソフトを使った)けれど、一体何のメリットがあるのか?」という疑問が生じてしまいます。
建築プロジェクトにおいて、まず私たちが取り組むべきだったのは、意思決定の履歴や経緯を効果的に共有し、関係者全員がその情報を瞬時に取り出し、共通の理解をもって進めるための仕組みでした。これにより、分科会や事前協議の時間を大幅に短縮し、その後のデータ不整合のリスクを軽減できます。重要なのは、BIMをツールとしてではなく、プロセスやコミュニケーションを革新するための「概念」として捉えることでした。
DBとLLM(大規模言語モデル)の役割
なぜ議事録のフォーマットが古いままなのでしょうか?これは技術的な問題が背景にあると考えられます。こ従来の議事録は証拠としての性質が強く、フォーマットも特に統一されていませんでした。仮に社内で統一されていたとしても、それは各社内の範囲に留まり、新たな意思決定を行う際に過去の経緯を瞬時に取り出すことは容易ではありませんでした。特に途中で変更が多発するプロジェクトでは、議事録を見返してもその経緯を整理するのは困難でした。そのため、意思決定の際に過去の経緯を瞬時に取り出すツールは、人間の脳以外に存在しませんでした。
しかし、昨今ではこの問題を解決できる可能性のある技術が登場しています。それがLLM(大規模言語モデル)です。LLMは言語や概念の意味を理解し、人間の思考プロセスに近い形で情報を処理する能力を持っています。さらに、セマンティック検索によって、質問の意味を理解して検索を行えるようになり、単純なキーワード一致だけでなく、概念的な類似性を踏まえた複雑な質問にも対応可能です。
例えば、5年にわたるプロジェクトで人の入れ替わりがあった場合でも、「○○さんの発言をまとめてください」と質問すれば、過去の意思決定データベースからその内容を整理して提供してくれるため、意思決定に関わる議事録データから瞬時に過去の検討経緯を取り出すことが可能になったと言えます。
グラフデータベースとセマンティック検索
GraphRAG(Graph-based Retrieval-Augmented Generation)は、グラフデータベースとセマンティック検索、さらにLLM(大規模言語モデル)の技術を組み合わせ、ユーザーの質問に対して関連する情報を効果的に検索・提供する仕組みです。具体的には、グラフデータベースが持つデータの構造化と関係性を活用し、セマンティック検索の意味的な類似性の理解を組み合わせることで、質問に対して文脈や意図に沿った的確な情報を引き出すことを目指しています。
ここで重要なのは、セマンティック検索が単にキーワードの一致に依存せず、検索クエリの「意味」を理解し、文脈や関連性に基づいた検索結果を返す点です。従来の検索エンジンがキーワードの一致のみを重視していたのに対し、セマンティック検索ではクエリの文脈や意図も考慮されるため、より自然な検索体験が可能になっています。セマンティック検索の発展にはLLM(大規模言語モデル)の登場が大きな役割を果たしました。例えば、ChatGPTのようなLLMは大量のテキストデータをもとに学習されており、言語の文脈や意味を深く理解できるため、従来の検索技術と比較して精度の高い検索結果が得られます。

セマンティック検索を支える技術のひとつが「埋め込み」(Embedding)です。Embeddingとは、テキストデータを高次元のベクトル空間に変換し、数値データとして扱う手法を指します。単語や文章をベクトルに変換することで、セマンティック検索では「ベクトル計算」を用いた類似度計算が可能になります。これにより、たとえ異なる言葉遣いをしても意味が近いクエリやドキュメントが見つかるようになります。

ハルシネーション(幻覚)の問題
ここで気になるのは、AIも人間同様に誤った情報(ハルシネーション)を生成してしまうことです。これは避けられない問題であり、今後も完全な解決は難しいと思われます。この対処方法としては、生成された回答がどのソースに基づいているかを明示し、データベース上の情報源にアクセスできるようにすることが挙げられます。チェックボットでもそうしています。

「直接データベースにアクセスすればいい」と考える方もいるかもしれませんが、建築の実務では「○○さんが○○について検討した経緯を教えてください」といった質問に対し、データベースだけが表示されても全体像を理解するのは困難です。そこで、AIの回答や要約から、時系列に並べられたソースを参照できるようにすることで、ハルシネーションの対策が可能になると考えています。
もう一つの対策は、不要な情報を入れないことです。現状のように長いワード文書形式ではデータベースとして活用するのが難しいため、チェックリストでは1問1答形式を採用しました。これはLLMにとっても都合が良く、余計な情報を極力排除することでセマンティック検索の精度を向上させ、ハルシネーションの発生率を抑えることができたと考えています。
これらの技術を活用することで、伝言ゲームの失敗を限りなく減らし、長引く会議を短縮することにつながるのではないかと考えています。GraphDBやセマンティック検索とLLMの応用により、建築プロジェクトにおける意思決定の履歴を効果的に管理し、必要な情報を瞬時に取り出すことが可能になるのではないかと考えています。
第三者の存在の職能
議事録のアップデートが必要なこと、そしてその技術的なことについて話してきました。次に疑問に思うのは、一体この職能は誰が担うのか?という点です。私は試行錯誤の過程で建築生産のフローを調査し、その内容を「建築生産の歴史と展望」シリーズにまとめましたが、そこにヒントがあると感じています。ここで言及していることは、建築のさまざまな課題を解決するには、発注者と受注者の間にもう一つの第三者の存在が必要なのではないか、という考えです。当初は、生産設計者がその役割を担うのではないかと考えていましたが、それは間違いでした。
第三者が担うべき職能は、意思決定のデータベースを管理し、取り出すことです。現状、この職能は建築業界には存在しておらず、各ステークホルダーが片手間で行っているか、個人レベルで管理しているに過ぎません。一部の書籍では、諸外国のように契約を厳密化することで、受注者間の不整合や問題を改善できるとされていますが、契約を結んでも、技術的に実現できなければ問題は解決しません。こうした意思決定の履歴を管理する職能は現在存在していませんが、今後、建築の透明性と公正性を確保するために、第三者の職能として確立される可能性があるのではないでしょうか。
現状では、白矩社内で、依頼された業務の範囲でのみデータベースが作成されていますが、理想はチェックボットのようなアプリケーションに各ステークホルダーが自由にアクセスし、経緯を確認できるようになることです。これにより、検討がスムーズになり、より良いプロジェクトの実現につながると考えています。また、データベースを通じた情報抽出であれば、非常に中立な立場を維持できるでしょう。
「職能」と言っていますが、これは必ずしも人である必要はないかもしれません。国が提供するオープンソースのアプリケーションを使い、建築プロジェクトの進行に活用する形も考えられますし、保険のような形で、各ステークホルダーが費用を負担してシステムを維持する体制もあり得ます。具体的な形は分かりませんが、今後、こうした発注体制についての議論が進むのではないでしょうか。
いずれにせよ、建築プロジェクトにおける意思決定の透明性と効率性を高めるために、第三者の職能やそれを支える仕組みの導入が求めるのではないでしょうか。
5章.まとめ
建築の問題だけではない
これまで私たちは、議事録のフォーマットをアップデートできずにいましたが、これらの実務的な問題は、LLM(大規模言語モデル)の登場により解決の道が開かれました。今後、LLMを活用したアプリケーションが実装され、その恩恵は計り知れないものとなるでしょう。さらに、履歴管理の堅牢性を求める場合には、ブロックチェーン技術を活用することで、意思決定の履歴を改ざんから守ることも可能です。業種ごとに異なる課題はあるかもしれませんが、全体的な方向性は共通していると考えられます。この記事が広まり、こうした新しい思索が多くの人々と共有されることを願っています。
私は建築分野の課題に向き合ってきたため、本記事も建築業界にフォーカスしています。特に建築業界は、プロジェクトの期間が長く、設計者や施工者、行政、クライアントなど多様なステークホルダーが存在するため、問題が複雑に絡み合う傾向があります。そのため、ある意味で課題の集大成のような側面も持っています。しかし、これは建築だけの問題ではありません。長期的なプロジェクトや多くのステークホルダーが関わるプロジェクトであれば、似たような課題を抱えているはずです。例えば、ソフトウェア開発、インフラ整備、大規模なイベント運営なども、情報共有や意思決定の履歴管理において同様の問題に直面しているのではないでしょうか。
ぜひ建築以外の分野の方にもこの記事が届き、課題解決の突破口となることを願っています。
白矩は何をやってきたのか?
これまで白矩がどのような会社なのか、その実態がいまいちわからなかったかもしれません。もちろん、弊社をよくご存じの方々は役割を理解してくださっていますが、私自身も「自分たちが何をしているのか」「何を伝えるべきなのか」を明確に言葉にすることができずにいました。「建築の課題を解決するため」と言い続けてきましたが、具体的な内容についてはうまく説明できなかったのです。私自身が明確に理解できていなかったのですから、外から見ればなおさら分かりにくかったことでしょう。
しかし、今回この記事を書いたことで、はっきりと気がつきました。それは、「新しい議事録のフォーマットを構築すること」に他なりません。まだ完全な形ではありませんが、いずれ何かしらのプロトタイプが生まれるでしょう。この記事を読んだ方々の中には、さっそく動き出して社会実装してくださる方もいるかもしれません。そのように広がっていけば、建築業界の課題解決も一層進むことでしょう。
かつては、BIM(Building Information Modeling)に希望を見出しましたが、一向にその先は見えませんでした。建築生産のフローや契約関係など、いろいろと調べましたが、納得のいく解決策を見つけられずにいました。ところが、たまたま興味を持って触れていたGraphDB(グラフデータベース)やLLM(大規模言語モデル)が、その解決のヒントになるとは思いもよりませんでした。また、このような発想に至ることもなかったでしょう。
長い建築の歴史において、LLMは大きな転換点であると感じます。これまで私は3Dデータから建築を見続けてきましたが、結局のところ、データ生成の効率化よりも、「意思決定に関わるデータの整理と抽出」の方が、プロジェクトに及ぼす影響が大きいと考えるようになりました。複雑化する建築に対して、私たちは意思決定の履歴を正確に繋ぐことが技術的にできていませんでした。分散しがちな記憶、しかも改ざんの可能性がある人間の脳に頼るしかなかったのです。ですが、それを代替する手段が現れました。それがAIです。AIによって、さまざまな人の意思決定の履歴を紡ぎ、建築が完成に至るまでの意思決定の「物語」を構築することが可能になったのです。そして、その物語から必要な情報を瞬時に抽出できる仕組みを作ることが、建築プロジェクトにおいて最も重要なことだったのだと思います。これまでの試行錯誤を重ねた結果、私が辿り着いた一つの答えが、次の言葉に表れています。
建築は「意思決定」の物語である。
謝辞
この記事を書く前に、ふとしたご縁で東京大学の「i-Constructionシステム学寄付講座」という会に参加させていただきました。そこで、東京消防庁での取り組みについて少しお話させていただいたのですが、話題が少し移り、私が今回考えていた仮説や関連する取り組みを紹介した際、参加者の皆様が非常に喜んでくださり、大きな励みになったことを覚えています。「もしかしたら自分が思っている以上に興味深い話なのかもしれない」と感じ、次の日には早速、記事を書き始めました(笑)。参加者の皆様ありがとうござます。またこの会にお誘いいただいた丹野さんにも感謝いたします。
そして、こうして建築の課題について深く考えることができたのも、会社メンバーである宮崎さんと高橋さんの協力があってこそです。お二人は一級建築士であり、実務経験も豊富なため、私では気づけない実務的な細かな点や貴重なフィードバックをいただくことができました。心から感謝いたします。
最後に、この長い記事を読んでいただきありがとうございました。この記事が、皆様にとって何かしらの感動や気づきをもたらすことができていれば幸いです。また、日本の建築業界の発展に少しでも貢献できることを願っています。
あとがき
時間をかけて、「諸悪の根源は議事録のフォーマットが古いからだ」とお話ししてきましたが、この記事を書き終えて、実は「建築プロジェクトの意思決定プロセスは、言語ゲームと同様に他者との合意に依存しており、その性質上、完全な解決が難しいのではないか?」とも思い始めています。(笑)
どういうことかと言いいますと、ここにはヴィトゲンシュタインやクリプキ、そして東浩紀といった方々の思想が関係しています。ヴィトゲンシュタインの「言語ゲーム」では、「言語や意味の理解は、その使用(=ゲームのプレイ)によって決定され、規則は明示的に存在するわけではない。」ということを示しました。クリプキはヴィトゲンシュタインの考えを発展させ、「規則や意味の理解は他者との社会的合意によって成立し、個人だけでは確定できない。」ことを指摘しています。
これらを踏まえて、東浩紀は「訂正可能性の哲学」で、共同体や規則は固定的なものではなく、プレイヤー(個々人)の行為と他者からの評価、訂正のプロセスを通じて動的に形成され、それを「家族」という共同体として再定義しています。
直観的に、多くのプロジェクトでは、多様な人々が関与し、状況やルールが変化する(検討フェーズが変わったり、人が入れ替わったり等)動的な共同体の性質を持っていると思います。
ここで問題となるのは、私が言ったような議事録がアップデートされ、AIがまるで他者のように振る舞ったとして、それが他者として合意形成に参加できるのか?という点です。このような共同体は、常に訂正する性質を孕んでいる以上、避けて通れない課題のような気がします。
しかし、これ以上は私の手には有り余るので、ここから先はどなたかにお任せしたいと思います。(笑)