
知らなきゃ損!データマネジメントの超基本 データモデリング講座③

はじめに
みなさん、こんにちは!
今回もデータモデルおよびデータモデリングという技術についてを解説します!
これまで、2回に渡り、データモデル・データモデリングの基本や、練習問題などを解説してきました。
前回までの内容についてはこちらをご覧ください。
今回は、前回の練習問題解説で説明しきれなかった「正規化」という概念についてをメインに解説していきたいと思います。
正規化とは?
そもそも正規化とは何でしょうか?
この説明をするためには少し、データベースとは何か?というところから簡単に説明する必要があります。
データベースとは、たくさんのデータを整理して保存するための仕組みです。
例えば、企業にある「従業員」というデータベースに、従業員の名前や住所、電話番号、などが保存されています。また、従業員一人一人に関する個人情報だけでなく、どんな企業のどの組織に所属しているのか?といった情報も含めて管理されています。
こうしたデータをきちんと整理して効率的に管理するために正規化という方法を使います。
正規化とは、データをルールに従って整理することです。これをすることで、データが無駄なく保存され、正確で一貫性のある情報を保つことができます。
簡単に言うと、正規化はデータを「きれいに並べる」ための方法です。
なぜ正規化が必要なのか?
データを正規化する理由は例えば以下のようなものがあります:
データの重複を減らす:
同じ情報を何度も保存したり、手で登録するのは無駄ですし、更新するときにミスが起きやすくなります。例えば、同じ従業員の名前や住所が、色々なテーブルやデータベースで何度も出てくると、その従業員が引っ越したときにすべての場所で住所を変更する必要があります。これを避けるために、データを分けて整理します。データの整合性を保つ:
整合性とは、テーブルや、データベースを跨いで、データが正しく一致していることを意味します。例えば、従業員の所属組織に関するデータが異なるテーブルやデータベースで違う内容だったら困ります。正規化することで、こうした矛盾が起きにくくなります。クエリの効率化:
クエリとは、データベースから情報を取り出すための質問のことです。データがきちんと整理されていると、必要な情報をすばやく見つけることができます。
正規化の実践解説
ここまで、正規化とは何かということを文章で説明してきました。
しかし、文章だけでは何を言っているのかイメージがつかない方も多くいらっしゃると思われます。
ですので、前回・前々回とお見せした練習問題をベースに正規化のイメージをお見せします。
前回まではこちらの名刺をベースに、データモデルとして表現する方法を説明してきました。

この名刺を以下のような流れでデータモデル化しました。


ここまでは、正規化をしていない状態でのデータモデルになりますので、ここから、正規化を行う過程をお見せします。
まず、この従業員エンティティのイメージをもう少し掴んでもらうため、値事例をお見せします。
従業員エンティティをそのままテーブル化する場合、おそらくこのような値が管理されることになるかと思われます。

この値を見ていると、以下2つのパターンに分けられます。
①従業員一人一人のレベルで値がようやく決まるような項目(氏名やメールアドレスなど)
②従業員よりも上のレベルですでに値が決まっている項目(会社や部署名など)
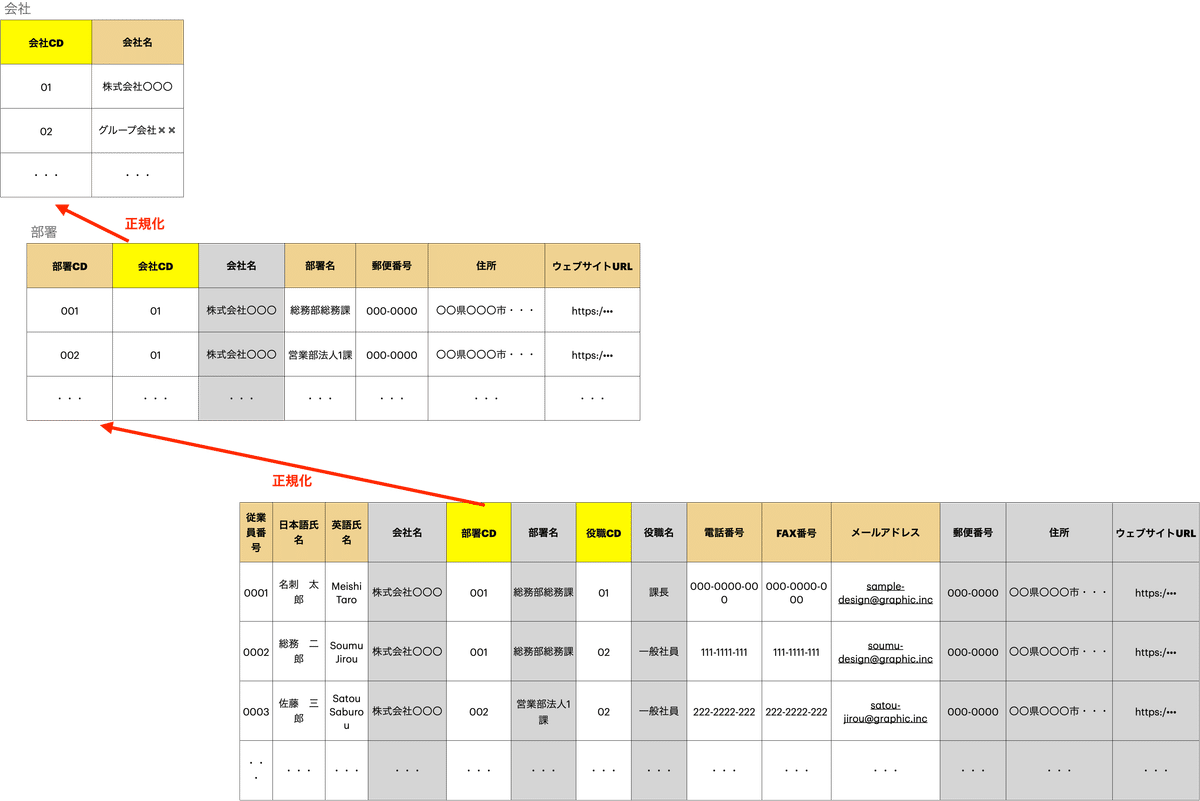
②については、以下の赤枠・青枠をご確認ください。

②の項目、つまり、上の図の会社名や、部署名、組織の住所などを、従業員一人一人に対し、毎回手打ちで登録するのは非常に面倒です。
これを解決するため、正規化を行います。
イメージとしては、上の図の赤枠部分を部署エンティティとして別途切り出し、青枠部分を役職エンティティとして別途切り出すイメージです。
※今回は、練習問題の都合上、別途部署コードや、役職コードが主キーとして存在する想定で、エンティティを切り出しています。

このように、正規化とは、対象エンティティの中で、冗長的に保持されている項目があればその項目たちと、それらを一意に識別する主キーを見つけ出し、別エンティティとして切り出すことを指します。
また、正規化の際、対象エンティティの中には、別エンティティの主キーだけを持たせておきます。こうすることで、いつでもその主キーをもとに、別エンティティの項目を引っ張ってくることができます。
これが、正規化のイメージとなりますが、もう一歩進んでみましょう。
部署エンティティをよく見ると、会社名が重複して登録されています。ここから、会社も同じように正規化できると判断できますね。
以下のようなイメージです。
※同じように、会社コードも都合上追加しております。
細かい話を細くすると、部署名の中に、部と課の名称がまとめて入っています。
これらは、本来別の組織であるべきなので、テーブルとしては分けておいた方が良いかもしれません。とはいえ、これは実際の組織図などを見てみないとわからないので、このブログ上ではこのままとしています。
また、住所やウェブサイトのURLについても同様に、会社のレベルで決まるのか、組織のレベルで決まるのかがわからないので、一旦このブログでは組織のレベルで決まるのだろうと想定しておきます。
正規化とは、このようなイメージで行います。
なお、正規化は第1〜第5正規形までの5つの段階が存在しています。
基本的には第3正規形までを覚えていただければ問題ないと考えています。
簡単にマッピングすると、第1正規形が本ブログの正規化ステップ⓪、第2正規形が正規化ステップ①、第3正規形が正規化ステップ②にあたると思ってください。
最後に、上記の正規化をデータモデルの表現で表すと以下のようになります。

最後に
以上のような流れで、正規化を実施していきます。
正規化はデータモデル・データモデリングにおいて核となる重要な概念になりますので、ぜひ覚えておいてください。
データモデルは奥が深くまだまだお伝えしきれていない内容が多くあるので、またどこかの機会で深掘りしていければと考えています。
少しでも、データモデルやデータモデリングって面白いかもと思っていただければ幸いです。
本日は以上になります、それでは!!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?