
「カイシャ脳」で差をつけろ!顧客サービスにおけるLLMを使った2つの実装戦略

カスタマーサポート×LLMの豆知識
カスタマーサポートにおける大規模言語モデル(LLM)の活用について、様々な取り組みが開始されています。
弊社も、AWSのプログラムや、Googleの試験利用に参加させていただいています。
いろいろと実験をしつつ、実装に向けて推進している最中ですが、並行で、コールセンター/コンタクトセンターにおけるLLMについて情報提供ができればと思います。
本日のテーマは、競争が加熱する『独自の大規模言語モデル(独自LLM)』に関連した話題である『ファインチューニングとレトリバリーダーについて』の話をしようと思います。
『企業独自データ×生成AI』の2つのアプローチ
ちょうど本日の日本経済新聞の村山さまの記事に、『カイシャ脳』という言葉で表現されていましたが、企業データ×LLMは非常にホットなテーマだと思います。*本記事のタイトルにも『カイシャ脳』ということばを使わせいただいていますが、村山さまに許可をいただいております*
結論からいうと、企業データ×LLMは、2種類の実装方法があります。下の図を見ていただければと思います。
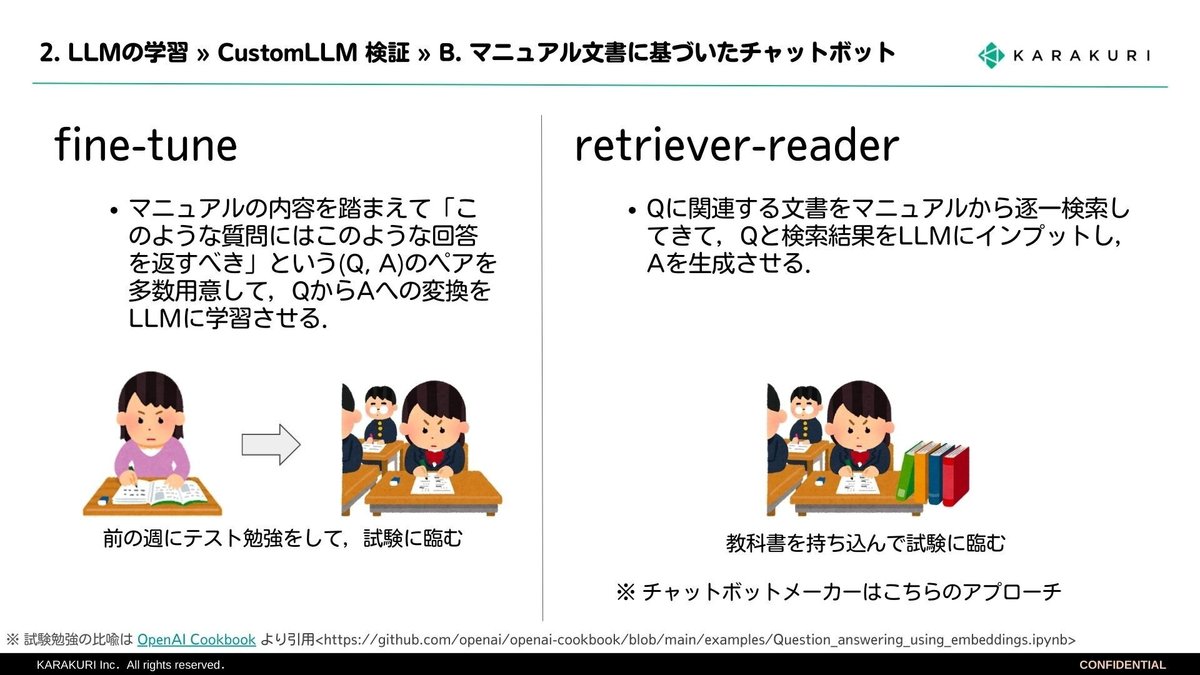
1つは、ファインチューニング。こちらは耳にしたことがあるワードかなと思います。もうひとつは、レトリバリーダー(レトリバル型とも言われる)という方式です。
もう少し専門的な解説を、chatGPTにお願いすると・・・以下になります。
ファインチューニング (Fine-Tuning):
事前に大規模なデータセットで訓練されたモデルを、特定のタスクや領域に適した形に調整する手法です。
タスク固有のデータを使って追加訓練を行い、モデルがその特定のタスクに更に適した回答や予測を出せるようにします。
レトリバル型 (Retrieval-based):
あらかじめ用意された知識ベースやデータベースから、質問に最も適した回答を検索して出力する手法です。
このタイプのモデルは、設問が固定されているケースや、事前に知識がコンパイルされているケースに特に有用です。
カスタマーサポートの顧客対応をイメージした際の長所・短所は以下のようにまとめられます。(注:現在のところ)

弊社は、ファインチューニングするケース、レトリバル型(Retriever-Reader)で実装するケース、ともに試験中ですので、追って情報公開できればと思います。
今回は2つの実装方法がある、という豆知識の共有でした。
引き続き、カラクリLLMラボでも情報提供を続けていきますので、よろしくお願いします。