シンプルなRAGシステムの実装

機械学習の授業でstreamlitを演習の一環として使っています。実際に手を動かしてアプリケーションを作成することにより、モノづくりの楽しさと機械学習の仕組みを同時に感じることができるのではと思っています。
RAGシステムの概要を教える機会があったため、その時に作った簡易なアプリを共有します。
前提知識
以下の内容はすでに説明済み
API経由でGPTと埋め込みモデルを使う方法
GPT3.5 (or 4)について
✾トークンとは
✾GPTの入力と出力
✾プロンプトの工夫
✾temperatureなどの引数
✾雰囲気だけざっくりとtransformerのアーキテクチャ
埋め込みモデル
✾埋め込みモデルの入力と出力
✾ベクトルが入力テキストの情報を含む
✾次元が多いほど情報量を多く含む(例えば、コーヒーをどのように説明するか。コーヒーを特徴付ける苦味、酸味、濃度などの観点がある。次元がそれぞれの異なる観点の軸とすると、次元数が多いほどテキストの情報を多く含んでいる、などのわかりやすい例を説明)
類似検索
✾二つのベクトル間の距離の計算方法Streamlitで簡易アプリの作成方法
RAGを実装するにあたって
以下の要点を説明しながら、streamlitに書き込んでいく。
文書(pdf)からテキストを抽出
langchainのloader機能を使う。
画像やテーブルなどの情報は抽出できていないため、改善余地がある。
テキストをチャンキング(テキストの分割)
langchainのsplitter機能を使う。
今回は一番シンプルな分割方法を使う。テキストを分割する方法はたくさんあるため、改善余地がある。
そもそもなぜテキストを分割する必要があるのか。→各チャンクをベクトル化して、チャンクとの類似検索を可能にする。
ベクトルデータベース
ベクトルデータベースはChromaDBを使う。
チャンクテキストをベクトル化して、テキストとベクトルをデータベースに保存。また、ファイル名などもメタ情報として保存。
ベクトルデータベースの検索機能
クエリをベクトル化して、保存されているベクトルとの類似検索機能がある。
メタ情報に条件を加えて(例えば、ファイル名)、類似検索を行くこともできる。
クエリと検索結果を基に要約
langchainのprompt機能を使用して、テンプレートを事前に用意する。
GPTで最後に要約してユーザーに返す。
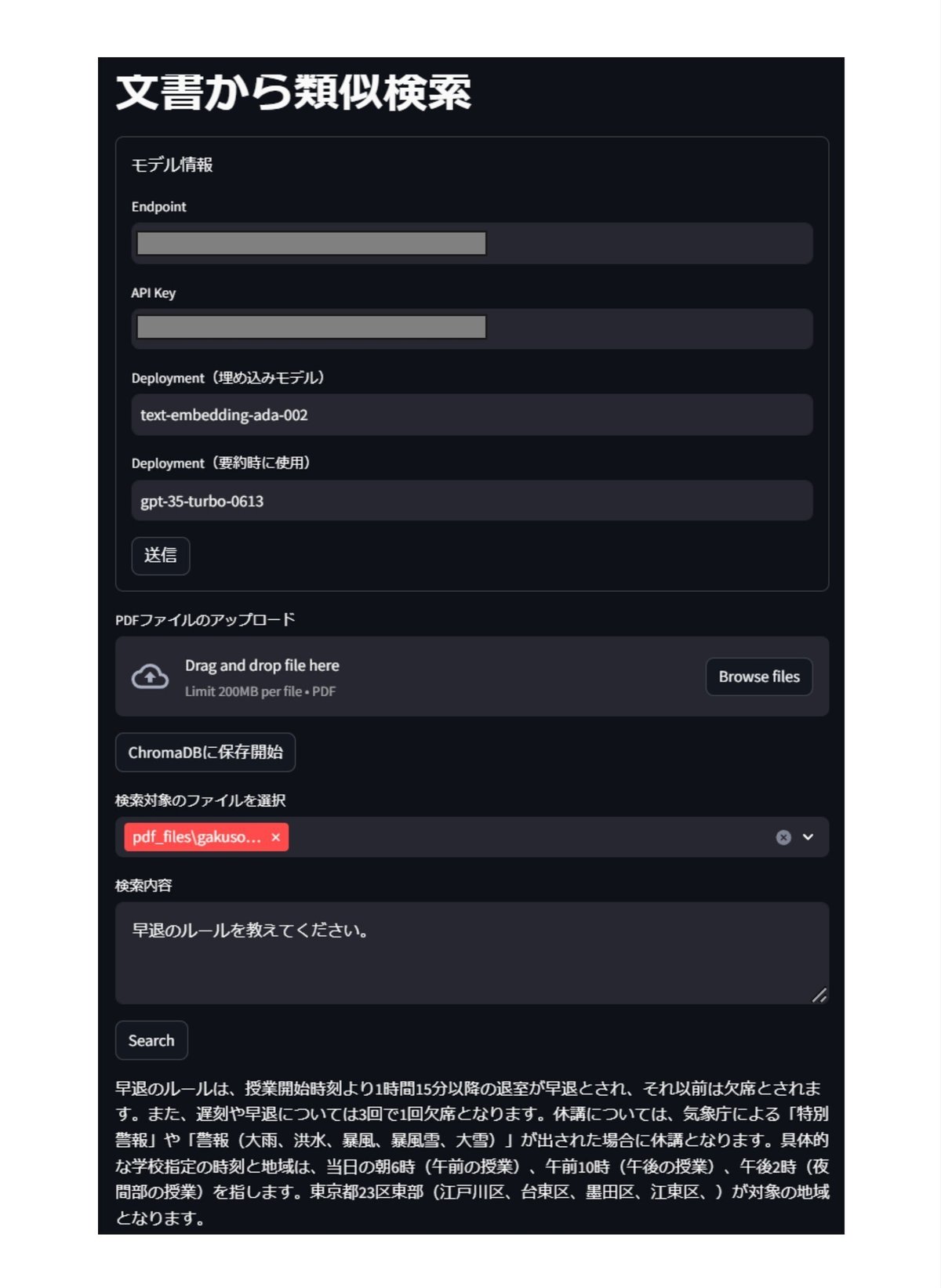
シンプルなRAGシステム
streamlitでは以下のUIになります。
以下のライブラリをインストール
pip install streamlit openai langchain tiktoken chromadb langchain-community unstructured[local-inference]以下のファイルをstreamlitで起動(事前に2つのフォルダpdf_filesとvectorstoreを作成)
授業では以下のスクリプトを段階的に書いていきます。
import streamlit as st
from langchain.embeddings import AzureOpenAIEmbeddings
from langchain.chat_models import AzureChatOpenAI
from langchain.vectorstores import Chroma
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
if 'embeddings' not in st.session_state:
st.session_state['embeddings'] = None
if 'gpt' not in st.session_state:
st.session_state['gpt'] = None
if 'vectorstore' not in st.session_state:
st.session_state['vectorstore'] = None
st.title('文書から類似検索')
with st.form('my_form'):
st.write('モデル情報')
AZURE_OPENAI_ENDPOINT = st.text_input('Endpoint')
AZURE_OPENAI_API_KEY = st.text_input('API Key')
deployment_embedding = st.text_input('Deployment(埋め込みモデル)')
deployment_summary = st.text_input('Deployment(要約時に使用)')
submitted = st.form_submit_button('送信')
if submitted:
try:
st.session_state['embeddings'] = AzureOpenAIEmbeddings(
openai_api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
deployment=deployment_embedding)
st.session_state['gpt'] = AzureChatOpenAI(deployment_name=deployment_summary,
openai_api_version="2023-05-15",
openai_api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
temperature=1)
st.session_state['vectorstore'] = Chroma(
persist_directory='vectorstore',
embedding_function=st.session_state['embeddings'])
except:
st.write('コネクションエラーが発生しました。')
# ファイルのアップロード
uploaded_file = st.file_uploader("PDFファイルのアップロード", type='pdf')
# フォルダに保存
from pathlib import Path
if uploaded_file is not None:
save_path = Path('pdf_files', uploaded_file.name)
with open(save_path, mode='wb') as w:
w.write(uploaded_file.getvalue())
# データベースの読み込み確認
if st.session_state['vectorstore'] is not None:
# データベースの中に保存済みのファイルを確認
files_in_db = list(set([file['source'] for file in st.session_state['vectorstore'].get()['metadatas']]))
start_indexing = st.button('ChromaDBに保存開始')
# ボタンを押したらindexing開始
if start_indexing:
files_in_db = list(set([file['source'] for file in st.session_state['vectorstore'].get()['metadatas']]))
st.write('PDFから読み込み...')
pdf_loader = DirectoryLoader('pdf_files', glob="*.pdf", exclude=files_in_db)
documents = pdf_loader.load()
st.write('読み込まれたドキュメント数', len(documents))
if len(documents) > 0:
text_splitter = CharacterTextSplitter(chunk_size=300,
chunk_overlap=30,
add_start_index=True)
st.write('チャンキング中...')
chunks = text_splitter.split_documents(documents)
st.write('データベースに保存...')
st.session_state['vectorstore'].add_documents(chunks)
st.session_state['vectorstore'].persist()
# データベースの中に保存済みのファイルを確認
files_in_db = list(set([file['source'] for file in st.session_state['vectorstore'].get()['metadatas']]))
selected_files = st.multiselect('検索対象のファイルを選択', options=files_in_db)
user_input = st.text_area('検索内容')
start_search = st.button('Search')
if start_search:
# 類似検索の条件を指定
retriever = st.session_state['vectorstore'].as_retriever(search_type="similarity",
search_kwargs={"k": 2,
'filter':{'source':{'$in':selected_files}}})
# 類似検索
retrieved_docs = retriever.invoke(user_input)
# 要約用のプロンプトテンプレート
template = '''
必ず「検索結果」を基に、「ユーザーからの質問」に答えなさい。
出力は質問への回答の要約のみを含むこと。
【ユーザーからの質問】
{input1}
【検索結果】
{input2}
'''
prompt_template = PromptTemplate(
input_variables=['input1', 'input2'],
template=template
)
# 要約用のLLMを準備
chain = LLMChain(llm=st.session_state['gpt'], prompt=prompt_template)
# 検索結果を要約
extracted_texts = "\n\n".join([doc.page_content for doc in retrieved_docs])
ans = chain.run(input1=user_input, input2=extracted_texts)
st.write(ans)ここまで読んでいただきありがとうございます。少しでも何かのお役に立てば嬉しいです。