
日本語って宇宙に繋がってる、、、?

人工知能/機械学習を使ってホワイトカラーの生産性を向上させる「自働化(にんべんの自動化)」をやりたなぁ、と思って自然言語処理なるものに頭を突っ込んだ。 ネットやオンライン教材、書籍等を漁りながら「自然言語処理ってなに?」「どうやるの?」という疑問への答えを探していてふと思った。 「そもそも、日本語ってなんやねん?」
多少が英語が使えることもあって、日本語の特殊性については漠然とした考えはあったが、改めて「日本語」なるものを調べてみると「ほんまに、日本語って変わってんなぁ」と独りつぶやいてしまった。 同時に、これを機械に理解させるのは極めて難しいことだと感じ始めた。
機械に理解させるには離散的記号をコンピューターが理解できる数値に変換しなければならない(らしい)。 これまで主流だった自然言語処理に加え深層学習/ニューラルネットによる処理が登場したことで、機械が言語を扱えるようになる可能性が広がってきた。 しかし、いろいろ読み聞きしていると、やはり「日本語」は機械にとってとても手強い相手のように思える。 なぜなら、日本語は曖昧にとても寛容な言語だからだ。
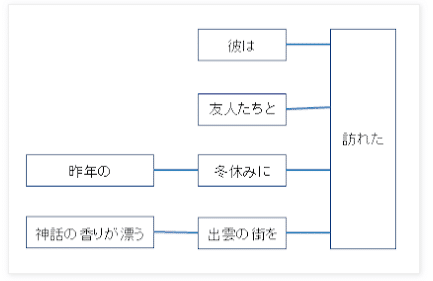
「彼は友人たちと昨年の冬休みに神話の香りが漂う出雲の街を訪れた」という文をSVOで整理すると以下のように整理できる。

しかし、日本語を使う日本人にとっては強い違和感を感じる。 実際の日本語は、次の図のように体言が全て述語に並列に係っていて、さらに順序にもかなりの自由度を持たせている方がとても自然だ。
(出典:日本語のチカラ https://kf-planning.blogspot.com/2015/05/blog-post_13.html)
これまで多くの優れた頭脳をもった専門家が、形態素解析、係り受け解析、述語項構造解析、強いては深層学習等の様々な方法を見出し、その精度を上げる研究を続けている。 残念ながら数学が苦手は自分には、これらの技術をかなり抽象度度の高い概念としては理解できるが、精緻なロジックを表した数式で理解できない。 しかし、直感で感じることは、日本語における「係り受け」や「文の構造」を機械が理解できる法則に落とし込むことはとても難しいということだ。
深層学習(ニューラルネットの多層化して学習させる方法)のように大量の学習から単語や句の関係を経験値化して機械に言語処理させる方法も見出されたが、自分には「伝統的自然言語処理」と比較して正解の確率が高くなったのであって、日本人が日本語を使うようにコンピューターが処理できるようになったとは思えない。
そもそも「日本語って何?」という疑問で頭が混沌としていた時、気分転換に読んだ本がきっかけであるイメージが湧いてきた。 その本とは「E = mc2のからくり(山田克哉氏著/講談社)」だ。
細かいことを書き出すと長くなるので、 ここでは、そのイメージと基本的な考え方だけ書き留めておこうと思う。

そもそもの「日本語」は、恐らく「太陽系」または「原子」のような構造をしているんだと思う。 述語(または用言句)が太陽(原子核)のような存在で、発話者の伝えたいことの中心(核)にある。 そして太陽を中心に伝えたい事の詳細の要素(体言)が恰も惑星のように太陽を周回する軌道上にある。 その要素を更に詳しく表現するための形容詞等の修飾語が惑星の周りを回る衛星として存在する。 これらの天体、即ち単語または句は、質量(=引力)と距離と運動速度のバランスで、述語の周りをグルグル回りながらも引き付けあって「文」を形作っているように思える。
直感は、さらに自分の頭の中で囁いてくる。 「もし、それぞれの単語の質量(=引力)と単語間の距離、そして運動速度を測ることができれば、日本語の文構造は物理の法則で計算できるのではないか?」
夜空に広がる宇宙に、自然言語処理のヒントが秘められているような気がしてならない。