【Python】SP500の株価先行指数について(Russel 2000、SKEW指数、VIX指数)

株価を前もって予測できる指数はあるのでしょうか?先行して株価が上がるか下がるかがわかる指数があれば知りたいと思いませんか。
以前の記事で、ハイイールド債(HYG)に対して、日にちを前後にずらしてS&P500の株価との相関係数を確認することで、前もってHYGを監視することで、S&P500の株価の上昇もしくは下降を予測できないか検討しましたが、スライド日数 0 近辺、すなわち一致して動いているときが一番S&P500の株価との相関が大きい結果となり、先行指数とは言いにくい結果となりました。
今回は、その他の指数である、Russel 2000、SKEW指数、VIX指数の関係を分析して、これらの指数が将来のS&P500の株価を予測できる可能性があるか確認します。
Russel 2000は、米国小型株を集めた指数で、景気が悪くなると、小型株にまでお金が行き渡らなくなり、S&P500のような大型株より、先に低迷することが知られています。炭鉱のカナリアとして有名です。炭鉱のカナリアという言葉は、炭鉱で有毒ガスが発生した場合、人間よりも先にカナリアが察知して鳴き声をやむことから、その昔、炭鉱労働者がカナリアをかごに入れて坑道に入ったことに由来するそうです。
SKEWは、CBOE SKEW Index(CBOEスキュー指数)を表します。これは、市場参加者の長期的なリスクに関する見通しを提供する指数です。高いスキュー値は、大きな下落のリスクが増加していることを示唆します。
VIXは、CBOE Volatility Index(CBOEボラティリティ指数)を表します。これは、オプション市場のボラティリティを測定する指数であり、市場の恐怖心や不安のレベルを示すことで知られています。
これらの指数は、S&P500の株価の動きと相関があると言われており、過去の記事において、SKEWとVIXについてはある程度相関があることも確認しています。
なお、異なる指標の検討が簡単にできるように、関数化してセッティングを変えるだけで関係が可視化できるようにコードも変更していきます。
なお、最低限のポイントのみの説明にするため、Pythonライブラリ、モジュール等のインストール方法については割愛させて頂きます。お使いのPC環境等に合わせてインストールしてもらえればと思います。
1.ライブラリのインポート
S&P500とHYG、Russel 2000、SKEW指数、VIX指数を取得するために、pandas-datareader と yfinance ライブラリを使用します。その他、日時を扱うため datetime や 可視化に使う matplotlib や plotly ライブラリをインポートします。
import pandas_datareader.data as web
import yfinance as yf
import datetime
import pandas as pd
# グラフィック系ライブラリ
import matplotlib.pyplot as plt
from matplotlib import gridspec
import japanize_matplotlib
%matplotlib inline
import plotly.graph_objects as go # グラフ表示関連ライブラリ
import plotly.io as pio # 入出力関連ライブラリ
pio.renderers.default = 'iframe'2.必要な関数を定義する
セッティングを変えるだけで関係が可視化できるように関数化します。
2-1.データを取得、結合したデータフレームを作成する関数
#データを取得、まとめてデータフレームを作成する関数
def get_data(stooq_codelists, yf_codelists, fred_codelists, start_date, end_date):
# データ取得(stooq)
df_stooq = web.DataReader(stooq_codelists, 'stooq', start_date, end_date)['Close']
df_stooq.sort_index(inplace=True) # 日付を昇順に並び替える
# データ取得(fred)
df_fred = web.DataReader(fred_codelists, 'fred', start_date, end_date)
# インデックスの名前を 'Date' に変更
df_fred.index.rename('Date', inplace=True)
# データ取得(yahoo finance)
df_yahoo = yf.download(yf_codelists, start_date, end_date)['Close']
# データ結合
df = pd.merge(df_stooq, df_yahoo, on='Date', how='inner')
df = pd.merge(df, df_fred, on='Date', how='inner')
df.columns = ['SP500', 'HYG', 'Russel2000', 'SKEW', 'VIX', 'DGS2', 'DGS10']
# NaNがあれば前の値で埋める
df.ffill(inplace=True)
return df各種指数を pandas-datareader (stooq, fred), yfinanceから取得して、結合したデータフレームを作成する関数 get_data() 関数を作成します。
pandas-datareader (stooq, fred), yfinance から取得する各種指数のティッカーコードが格納されたリストをそれぞれ、stooq_codelists, fred_codelists, yf_codelists として get_data() 関数の引数に指定します。そして、スタート日時 start_date、最終日時 end_date も同様に関数の引数に指定します。最後に stooq、fred と yfinanceから取得したデータを結合します。
2-2.データを平滑化する関数
def simple_moving_ave(df, window):
col_list = df.columns # df列のカラム名をリストで取得
print('col_list=', col_list) # カラムリストを出力して確認(チェック用)
for col in col_list:
# 元々のdfの各列に対してwindow日の移動平均をとる
df[col + f'_SMA{window}'] = df[col].rolling(window=window).mean()
return df単純移動平均(SMA:Simple Moving Average)を算出し、データを平滑化する関数 def simple_moving_ave() 関数を作成します。df と移動平均を算出する日数 window を引数に指定します。
元々のdfの各列に対して、設定したwindow日の移動平均を取得し、新たな列としてdfに追加していきます。
2-3.時系列のデータを描画する関数
def graphic(df):
col_list = df.columns # df列のカラム名をリストで取得
col_len = len(col_list) # df列のカラム数を取得
print('col_list=', col_list, 'len', col_len) # カラムリストとカラム数を出力して確認(チェック用)
plt.figure(figsize=(14,32)) # figsizeを定義
# 余白を設定
plt.subplots_adjust(wspace=0.4, hspace=0.6)
cnt = 0
for col in col_list:
cnt+= 1
# グラフの描画
plt.subplot(col_len,1,cnt) # カラム数分縦にグラフを追加
plt.plot(df[col], label=col)
plt.title(col)
plt.legend()
plt.grid(True)
plt.show()
returnデータフレーム df を描画する関数 def graphic() 関数を作成します。df を引数に指定します。df のカラム分のデータを縦にグラフ化していきます。
2-4.分析したいデータをずらす関数
def shifted_data(df, shift_m, shift_p, specified_code):
# SP500と分析する指標のみのデータフレームを作成
df_shift = df[['SP500', specified_code]]
# シフトする日のリストを作成
shift_days = list(range(shift_m, shift_p+1))
for days in shift_days:
# 列名につけるサフィックスを決定(負ならB、正ならA)
suffix = 'B' if days < 0 else 'A' if days > 0 else 'Current'
# 日をシフトしたデータフレームを作成
shifted_df = df_shift[[specified_code]].shift(freq=f'{days}D')
# データフレームのカラム名をつける
shifted_df.columns = [f'{specified_code}_{abs(days)}D_{suffix}']
# df_shiftデータフレームにシフトしたデータフレームをマージ
df_shift = pd.merge(df_shift, shifted_df, on='Date', how='left')
# NaNの処理
df_shift.ffill(inplace=True)
df_shift.dropna(how='any', inplace=True)
return df_shift分析したいデータをずらす関数 def shifted_data() 関数を作成します。プラス側にずらす日数 shift_p、マイナス側にずらす日数 shift_m、分析したい指標のコード specified_code を引数に指定します。
shiftメソッドを使用して、分析する指標の日にちを shift_m から shift_p の範囲でずらしたデータフレーム shfted_df を算出し、S&P500と分析する指標のデータフレーム df_shift にマージします。
2-5.相関係数を解析する関数
def analyze_correlation(df_shift, shift_m, shift_p, specified_code):
df_shift_corr = df_shift.corr()[['SP500']] # 相関関係.corr()[['SP500']] # 相関係数の SP500の列のみをデータフレームにする
df_shift_corr.drop(index='SP500', inplace=True) # indexの SP500の行を削除
df_shift_corr.reset_index(inplace=True) # indexをリセットする
df_shift_corr.columns = ['スライド日数_元', '相関係数']
df_shift_corr.drop(index=0, inplace=True) # NaNの行を削除する
df_shift_corr['スライド日数'] = 0
# シフトする日のリストを作成
shift_days = list(range(shift_m, shift_p+1))
for days in shift_days:
# 列名につけるサフィックスを決定(負ならB、正ならA)
suffix = 'B' if days < 0 else 'A' if days > 0 else 'Current'
# データフレームのカラム名をつける
shifted_colum_name = f'{specified_code}_{abs(days)}D_{suffix}'
# スライド日数列にずらした日数を格納する
df_shift_corr.loc[df_shift_corr['スライド日数_元'] == shifted_colum_name, 'スライド日数'] = days
return df_shift_corr相関係数を解析する関数 def analyze_correlation() 関数を作成します。プラス側にずらす日数 shift_m、マイナス側にずらす日数 shift_p、分析したい指標のコード specified_code を引数に指定します。
df_shift.corr()でS&P500と各指標の相関係数を算出し、df_shift.corr()[['SP500']] でS&P500列のみの相関係数のデータフレームとします。最終的にずらした日数と相関係数の関係を知りたいので、ずらした日数である、'スライド日数' 列を作成しています。
2-6.スライド日数と相関係数の関係をグラフ化する関数
def graphic_shift(df_shift_corr, analysis_code):
# グラフの実体trace オブジェクトを生成
bar_trace_1 = go.Bar(x = df_shift_corr['スライド日数'], y = df_shift_corr['相関係数'], name = '相関係数')
# レイアウトオブジェクトを生成
graph_layout = go.Layout(
# 幅と高さの設定
width=800, height=600,
# タイトルの設定
title=dict(
text=f'スライド日数と相関係数の関係 ({analysis_code})', # タイトル
font=dict(family='Times New Roman', size=20, color='grey'), # フォントの指定
xref='paper', # container or paper
x=0.5,
y=0.87,
xanchor='center',
),
# 軸の設定
xaxis = dict(title = 'スライド日数', showgrid=False),
yaxis = dict(title = '相関係数', side = 'left', showgrid=False),
# yaxis2 = dict(title = '相関係数', side = 'right',showgrid=False, overlaying = 'y'),
# 凡例の設定
legend=dict(
xanchor='left',
yanchor='bottom',
x=0.5,
y=0.85,
orientation='h',
bgcolor='white',
bordercolor='grey',
borderwidth=1,
),
)
# 描画領域である figure オブジェクトの作成
fig = go.Figure(layout=graph_layout)
# add_trace()メソッドでグラフの実体を追加
fig.add_trace(bar_trace_1)
# fig.add_trace(scatter_trace_1)
# レイアウトの更新
fig.update_layout(
plot_bgcolor='white', # 背景色を白に設定
)
# 軸の設定
# linecolorを設定して、ラインをミラーリング(mirror=True)して枠にする
fig.update_xaxes(linecolor='black', linewidth=1, mirror=True)
fig.update_yaxes(linecolor='black', linewidth=1, mirror=True)
# ticks='inside':目盛り内側, tickcolor:目盛りの色, tickwidth:目盛りの幅、ticklen:目盛りの長さ
fig.update_xaxes(ticks='inside', tickcolor='black', tickwidth=1, ticklen=5)
fig.update_yaxes(ticks='inside', tickcolor='black', tickwidth=1, ticklen=5)
# gridcolor:グリッドの色, gridwidth:グリッドの幅、griddash='dot':破線
fig.update_xaxes(gridcolor='lightgrey', gridwidth=1, griddash='dot')
fig.update_yaxes(gridcolor='lightgrey', gridwidth=1, griddash='dot')
# 軸の文字サイズ変更
fig.update_xaxes(tickfont=dict(size=15, color='grey'))
fig.update_yaxes(tickfont=dict(size=15, color='grey'))
# show()メソッドでグラフを描画
fig.show()
returnずらしたデータとの相関を描画する関数 def graphic_shift() 関数を作成します。ずらしたときの相関係数のデータフレーム df_shift_corr と分析したい指標のコード analysis_code を引数に指定します。
3.メイン関数
メイン関数で、解析したい指標のセッティングをします。下記コードは以下のような条件にセッティングした解析例です。
# 解析する指標のセッティング
stooq_codelists = ["^SPX"]
yf_codelists = ['HYG', '^RUT', "^SKEW", "^VIX"]
fred_codelists = ["DGS2","DGS10"]
"^SPX" : SP 500 # 'HYG' : ハイ・イールド債
"^RUT" : Russel 2000
"^SKEW" : SKEW
"^VIX" : VIX index
"DGS2" : 2-Year Treasury Constant Maturity Rate
"DGS10" : 10-Year Treasury Constant Maturity Rate
# 解析する期間のセッティング
start = '2020-01-01'
end = datetime.date.today()
# 解析する1コードと期間のセッティング
analysis_code = 'Russel2000'
analysis_duration = 60
最後に、下記で相関係数が最大のときのデータを取得して表示しています。
max = df_shift_corr['相関係数'].max()
max_df = df_shift_corr[df_shift_corr['相関係数'] == max]
display(max_df)
if __name__ == '__main__':
# --------------- 解析セッティング ------------------
# "^SPX" : SP 500
# 'HYG' : ハイ・イールド債
# '^RUT' : Russel 2000
# "^SKEW" : SKEW
# "^VIX" : VIX index
# "DGS2" : 2-Year Treasury Constant Maturity Rate
# "DGS10" : 10-Year Treasury Constant Maturity Rate
# 解析する指標のセッティング
stooq_codelists = ["^SPX"]
yf_codelists = ['HYG', '^RUT', "^SKEW", "^VIX"]
fred_codelists = ["DGS2","DGS10"]
# 解析する期間のセッティング
start = '2020-01-01'
end = datetime.date.today()
# 解析する1コードと期間のセッティング
analysis_code = 'Russel2000'
analysis_duration = 60
# ---------------------------------------------------
# --------------- 定義した関数を実行 ----------------
# データを取得してまとめる
df = get_data(stooq_codelists, yf_codelists, fred_codelists, start, end)
print(df.isnull().sum())
display(df)
# データを平滑化する
window = 14 # 14日移動平均を算出
df = simple_moving_ave(df, window)
print(df.isnull().sum())
display(df)
# データを可視化する
graphic(df)
# 分析したいデータをシフトする
specified_code = analysis_code + f'_SMA{window}'
df_shift = shifted_data(df, -analysis_duration, analysis_duration, specified_code)
display(df_shift)
# 相関分析
df_shift_corr = analyze_correlation(df_shift, -analysis_duration, analysis_duration, specified_code)
display(df_shift_corr)
# シフトデータのグラフ化
graphic_shift(df_shift_corr, analysis_code)
# ---------------------------------------------------
# 相関係数がmaxのときのデータ取得
max = df_shift_corr['相関係数'].max()
max_df = df_shift_corr[df_shift_corr['相関係数'] == max]
print(max)
display(max_df)実行すると下記のような表示ができます。


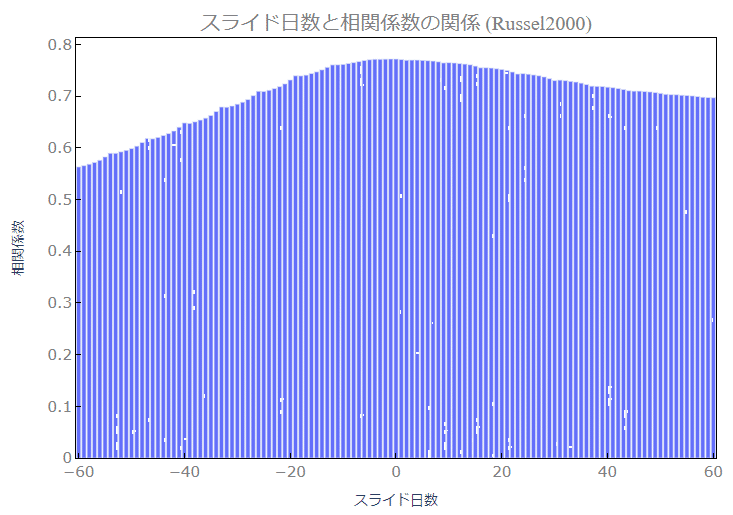

4.結果の考察
Russel2000、SKEW、VIXに対して、日にちを前後にずらして相関係数を確認することで、前もってこれらの指標を監視することで、S&P500の株価の上昇もしくは下降を予測できないか検討します。解析する期間は、2020年の1月1日から2024年2月3日(記事の投稿日)までの期間とします。
4-1.SP500とRussel2000を-60から60日ずらしたデータとの相関
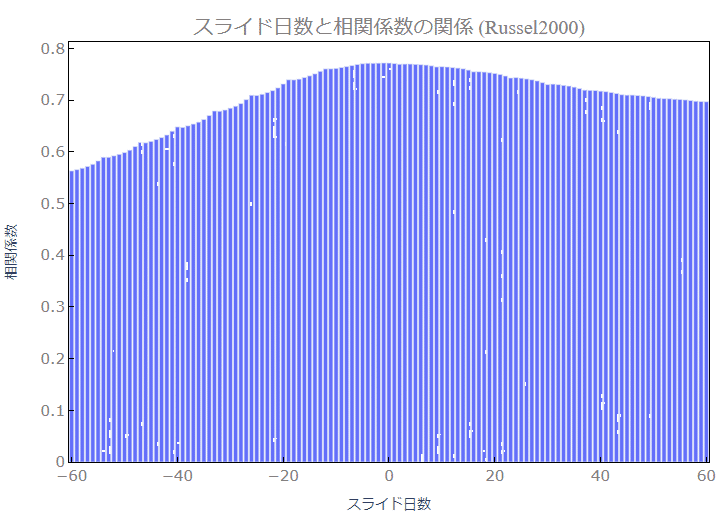

Russel2000の結果は、相関係数の山の頂点が若干ですがマイナス側になっています。もう少し詳細なデータ分析が必要ですが、Russel2000の株価が少しあとのS&P500の株価に影響しているかもしれません。
4-2.SP500とSKEWを-60から60日ずらしたデータとの相関


前もってSKEWを監視することで、S&P500の株価の上昇もしくは下降を予測できないか検討しましたが、スライド日数 0 近辺、ほぼ一致して動いているときが一番S&P500の株価との相関が大きい結果となりました。
4-3.SP500とVIXを-60から60日ずらしたデータとの相関
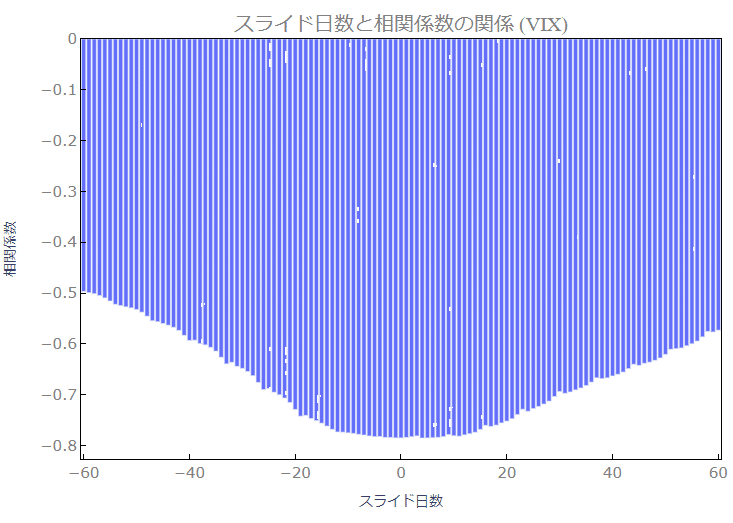
前もってVIXを監視することで、S&P500の株価の上昇もしくは下降を予測できないか検討しましたが、スライド日数 0 近辺、ほぼ一致して動いているときが一番S&P500の株価との相関が大きい結果となりました。
まとめ
今回は、前回の記事「【Python】SP500の株価先行指数について(HYGについて)」のコードを関数化して、設定した指標に対して、解析したい指標や期間をセッティングすることにより、日にちを前後にずらしたときの相関係数を表示できるように改良しました。
またRussel2000、SKEW、VIXに対して、日にちを前後にずらして相関係数を確認することで、前もってこれらの指標を監視することで、S&P500の株価の上昇もしくは下降を予測できないか検討しました。
今後は、期間を変更したり、更に他の指標についても同様の手法で、先行指数があるのかを確認していきたいと思います。
また、これらの指標となる株価の変化量に対しての影響等を調査してみても良いかもしれません。