
『一部メンバー限定』 LoRA学習用データセットの基本

今回はLoRA学習の際に必要となるデータセットについての解説です。
一般的な数十枚のデータセットだけではなく、数百枚単位や一部追加学習レベルの話も含めての解説となります。
データ用画像の入手法、リサイズ・トリミングなどの各種便利ツール紹介、除外すべき画像の特徴(SDXLとSD1.xでは異なります)、キャプションなどを解説します。
便利ツールに関しては一般向け公開とし、それ以外をメンバー限定記事とさせていただきます。
その為、構成が少し変則的ですが、ご了承ください。
◆便利補助ツールの紹介
・XnConvert
一括リサイズ・トリミング等の際には必須になっているソフトウェアです。一つの処理だけではなく複数の加工も決めた順序で実行してくれるので作業効率が格段に上がります。
フォルダ単位での指定やまとめてドラッグ&ドロップで追加でき、動作も軽いです。

リサイズだけの場合は、
▼動作→動作を追加→画像→リサイズを選択。
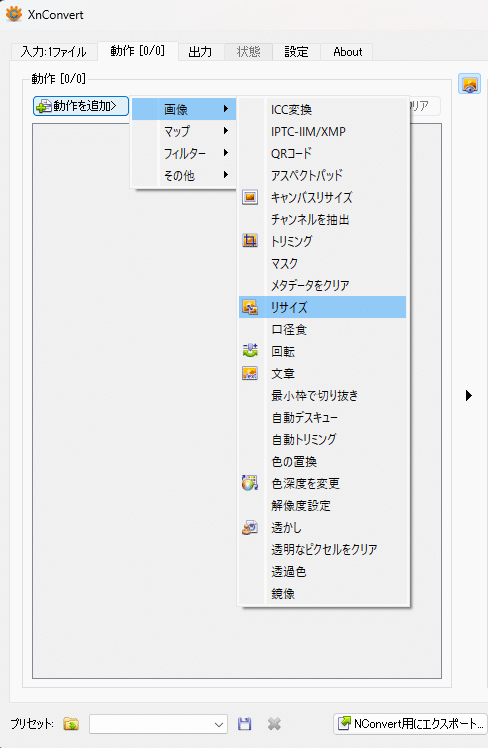


プレビューで変換前、変換後も確認可能。
アスペクト比を保ったまま、リサイズの場合は揃えたい方に数字を入れて、もう一方は0。
✓比率を保つ
で変換(C)を押せば一括でリサイズも行えます。
出力メニューで画像形式・画質・ファイル名・保存先等が指定可能です。
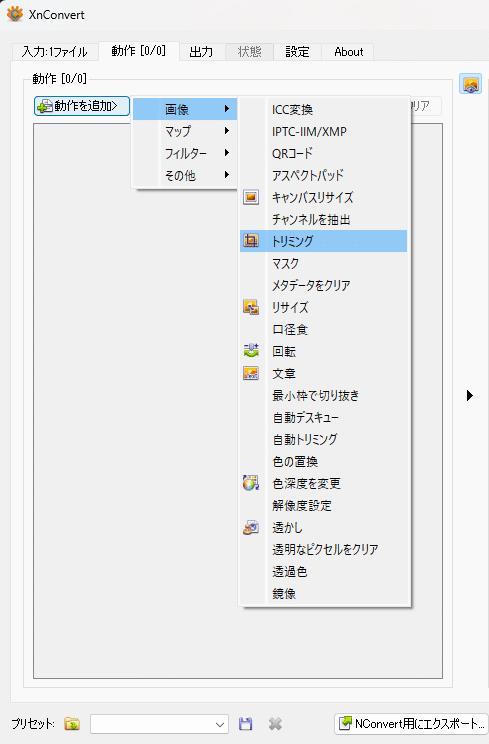
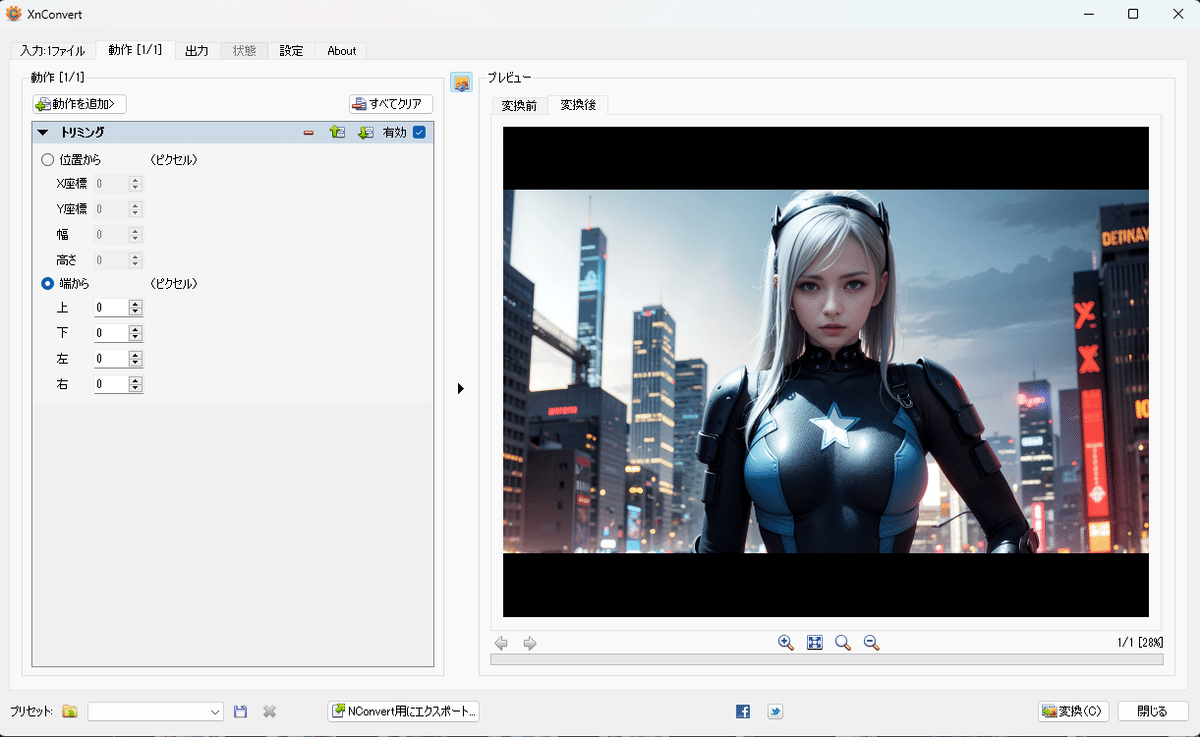
トリミングは上記のような座標式です。
顔中心でトリミングしたい場合は、後述のWEB UIの機能で行えます。
またXnConvertは複数処理を組み合わせることが可能です。
加えてキャンバスリサイズという機能があり、例えば全部768*768にしたい、1024*1024にしたい等の際に役立ちます。
サイズに満たない部分を指定の背景色で埋めることが可能です。
ただ下記のように、背景がしっかりと描きこまれている画像の場合、白・黒等で余白を埋めても、その部分を学習してしまい、上下に白や黒の余白が生まれやすいLoRAになるので注意が必要です。
逆に最初から白背景や黒背景、透過背景の画像。立ち絵や、スタジオ等で背景黒メインの写真などでは有用です。

またトーンカーブや彩度調整機能などもあるので、一番活用しているソフトウェアです。
・AUTOMATIC1111

顔中心にトリミングする場合は、AUTOMATIC1111の
▼Train→Preprocess imagesで✓Auto focal point cropを行い、処理するのが一番手軽だと思います。
ただ時々見切れてトリミングされるので、目視で最終チェックは必須です。
・縦長画像と横長画像の振り分け
大量のデータを扱う際に、混ざるとリサイズ・トリミング加工が面倒になるので、作りました。
素人が適当に作ったので必要に応じて改変してください。プログラムなどが分からない方はGPT等に投げれば修正案を出してもらえます。
下記を.py形式で保存し、コマンドプロンプトやターミナルで実行してください。
import os
from PIL import Image
import shutil
# 画像が存在するディレクトリ
image_dir = '振り分けたい画像が存在するパス'
# 画像を移動させるディレクトリ
vertical_dir = '縦長画像を保存したいパス\A'
horizontal_dir = '横長画像を保存したいパス\B'
# 画像ディレクトリ内の全てのファイルをチェック
for filename in os.listdir(image_dir):
# 画像ファイルのパス
img_path = os.path.join(image_dir, filename)
# 画像の読み込み
try:
with Image.open(img_path) as img:
# 画像のサイズを取得
width, height = img.size
# 縦長か横長か判定
if height > width:
# 縦長の場合、Aフォルダに移動
shutil.move(img_path, os.path.join(vertical_dir, filename))
else:
# 横長の場合、Bフォルダに移動
shutil.move(img_path, os.path.join(horizontal_dir, filename))
except:
print(f"Couldn't process image {img_path}")なおpillowが必要となりますので、導入されていない方はinstallしてください。
pip install pillow・DupFileEliminator
数十枚の小規模LoRAなら必要ないのですが、既存の大規模データセットを利用したり、WEBスクレイピングで画像を集めると、必ず画像の重複や差分による類似画像が大量に含まれます。
これは過学習の原因となるので、削除推奨です。
DupFileEliminatorは重複画像や類似画像を簡単に削除可能なので大変有用です。

まずは整えたいフォルダを指定し、重複ファイル検索で重複画像を削除。その後、類似画像検索に移行して、削除してください。
ただ明らかに解像度が異なる画像ですと引っかからないので、上記の処理を行った画像群を一度、一括リサイズしてから再度行うと精度が上がります。
これも数百枚以上のLoRAだと必須の作業です。
・waifu2x-caffe
AI処理による高画質・拡大ツールとして一時期かなり有名になり、AIによる画像処理を一般的に認知させた『waifu2x』のローカル環境版です。
LoRAを作成する際には可能な限り高画質の画像、ノイズが少ない画像を用意するほうが悪影響を低く抑えられますが、どうしても高画質なデータが用意できない時や、ISOノイズなどを軽減したい時に使用しています。
なお、waifu2x-caffeによる低画質画像を拡大してのLoRA作成はSD1.xであれば許容範囲と思えますが、SDXLだと推奨しません。
私はISOノイズ除去を中心に、レベル3で使用しています。
ノイズ除去は画像リサイズ・トリミング後、最後に行うと良いでしょう。

またはStable Diffusion WEB UIのExtraにてBatch from Directoryを用いて、自分にあったupscalerで高画質化を行うのも手ではあります。
他にも有料で優秀なAI高画質化ソフトウェアやStable Diffusionを用いた修復技術などもあるのですが、割愛。
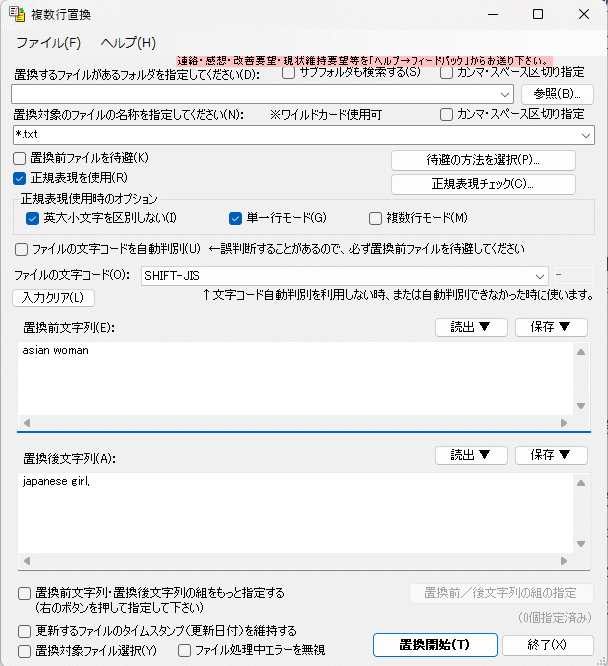
・複数行置換
.txt形式で出力したBLIP2キャプションを複数ファイル一括編集する為に使用しています。
wd-v1-4 taggerでのタグ付けの場合はタグ単位で拡張機能や有志が配布していた『学習用タグの編集を速く楽にするやつ』で編集できるのですが、1文形式のキャプションだと編集できないので用いています。
BLIP2だと日本人画像を読み込ませてもasian woman等になる為、japanese girlなどに変更する為に用いています。
・その他
①AI画像ファイル自動フォルダ分け
人物が写っている画像と写っていない画像を振り分けたり、アダルトと非アダルトを振り分けるソフトウェアですが精度は微妙です。特にアダルトと非アダルトは機能していません。
ただ人物が写っている画像と写っていない画像を振り分けは多少時間短縮になるので紹介致します。
上記のソフトウェアを用いれば、規模が大きめなデータセットの構築効率は上がると思います。
ただ最終的には目視チェック必須なので、単純労働の極致が発生し、かなり大変です。
なお以降はメンバー限定記事としての公開となります。ご了承ください。
この記事が気に入ったらチップで応援してみませんか?