WhisperとColaboratoryで動画コンテンツをテキスト化!自動で文字起こし

OpenAIのWhisperと、Google が提供するColaboratoryで、無料で動画データを文字に起こすツールを作成していきます✨
(今回はリアルタイム処理ではなく、既にある音声データや動画をテキストデータとして文字起こしします。)
Wisperとは
OpenAIが提供する無料の音声認識モデルです。このモデルは、Webから集められた68万時間分の多言語音声データを学習しており、非常に高い精度で音声を文字に変換することができます。
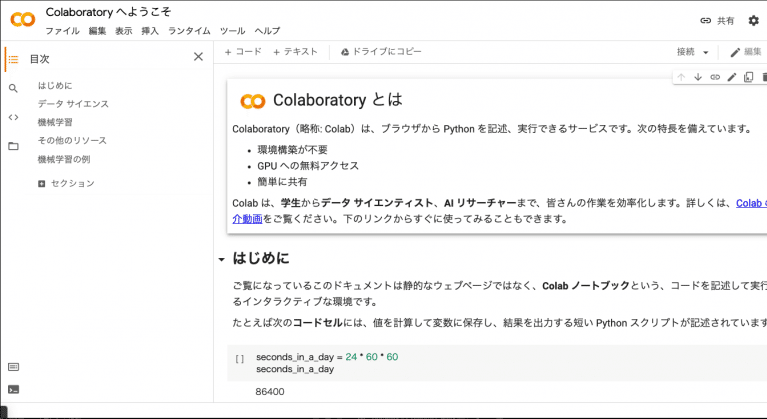
Google Colaboratoryとは
Googleが提供するサービスで、ブラウザから直接Pythonを記述・実行することができます。ローカル環境の構築が不要で、さらにGPUも搭載されているため、高性能な計算など可能です。無料版でも十分なスペックを持っているので、今回はこちらを活用していきます◎
01.環境セットアップ
Google アカウントにログインした上で、公式サイトにアクセスしてください。
すると、このような画面が表示されます。
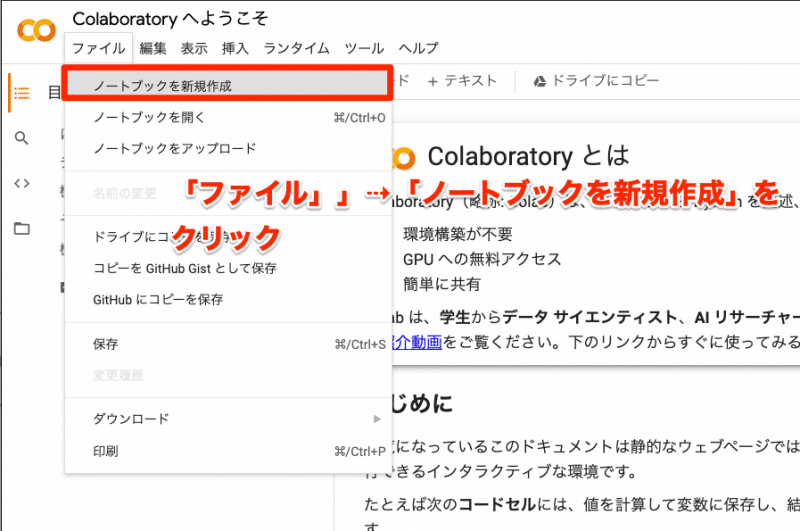
「ファイル」→「ノートブックを新規作成」をクリックし、新規ノートブックを作成していきましょう。
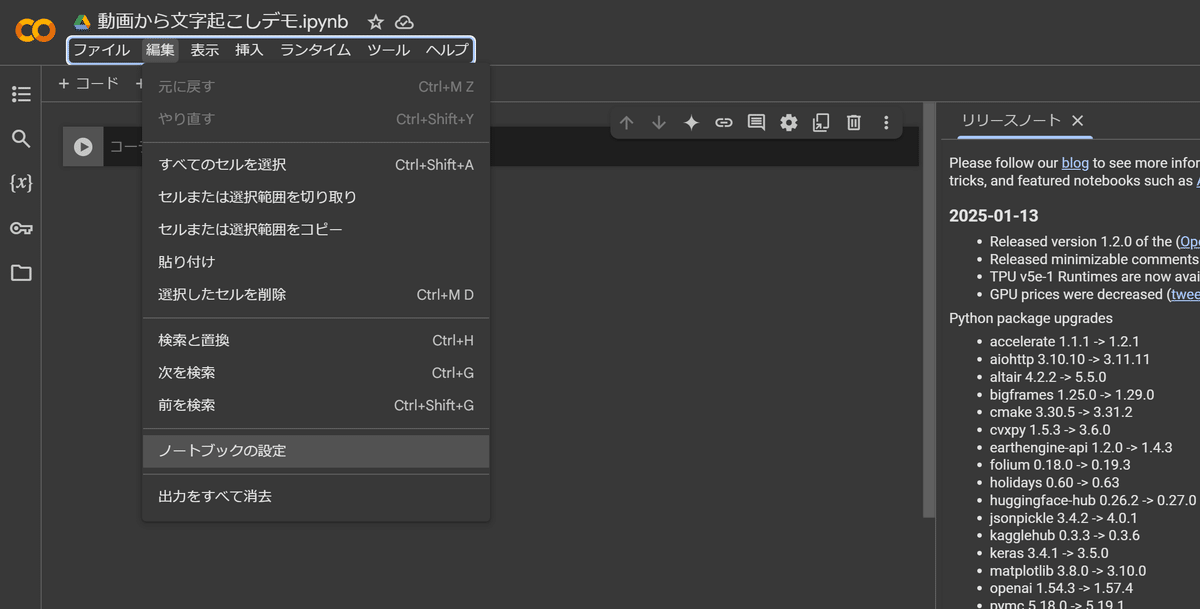
適宜、ノートブック名を付けてあげてください。
作成したファイルは「My Drive」→「Colab Notebooks」から確認できます。

続いて【編集】 > 【ノートブックの設定】を展開し、
ランタイムのタイプを「T4 GPU」または「GPU」に変更てください。
💡これにより、高速な処理が可能になります。
02.Whisperのインストール
💡基本操作をざっくり説明
【+コード】を選択するとコードセルが追加されます。
赤枠(コードセルの入力場所)からコマンドを入力していきます。

それでは、Whisperをインストールするために、以下のコマンドを下記の赤枠内に入力して、三角の実行ボタン(▸)を押します。
# Whisperのインストール
!pip install git+https://github.com/openai/whisper.git
処理が実行されます。
つづいて再度「+コード」をクリックして、以下のコマンドを下記の赤枠内に入力して、三角の実行ボタン(▸)を押します。
# 必要なライブラリのインポート
import whisper
これで、基本的な環境構築は完了です。
03. フォルダーの作成
音声ファイルをアップロードするフォルダと、文字起こし後の処理済みデータを格納するフォルダーを作成していきます。
以下のコマンドを実行してください。
# フォルダーの作成
for folder in ["content", "download"]:
if not os.path.exists(folder):
os.mkdir(folder)
これで以下の準備が整います:
contentフォルダー:音声ファイルをアップロードする場所
downloadフォルダー:文字起こし結果を保存する場所
04. 音声データをアップロード
音声データを用意し、contentフォルダーへアップロードしてください。
💡今回はTikTokの動画コンテンツデータをアップロードします。
TikTokの投稿で右クリックしてダウンロードし、mp4形式のファイルとして準備しました。
05. 文字起こし処理
今回は以下を想定して、処理を行っていきます。
・音声ファイルが複数ある
・音声データは日本語
・データの形式はMP4
以下のコマンドを実行してください。
import whisper
import os
from tqdm import tqdm
# モデルのロード(一度だけ実行)
model = whisper.load_model("base")
# contentフォルダー内のMP4ファイルのみを取得
audio_files = [
f for f in os.listdir("content")
if f.endswith('.mp4')
]
print(f"処理対象のMP4ファイル数: {len(audio_files)}件")
# 全ファイルを処理
for audio_file in tqdm(audio_files, desc="文字起こし処理中"):
try:
# 日本語指定で文字起こし実行
result = model.transcribe(
f"content/{audio_file}",
language="ja", # 日本語指定
verbose=False # 進捗バーをシンプルに
)
# 結果を個別のテキストファイルに保存
output_file = f"download/{os.path.splitext(audio_file)[0]}.txt"
with open(output_file, "w", encoding="utf-8") as f:
f.write(f"【{audio_file}の文字起こし】\n\n")
f.write(result["text"])
print(f"\n✓ 完了: {audio_file}")
except Exception as e:
print(f"\n× エラー ({audio_file}): {str(e)}")
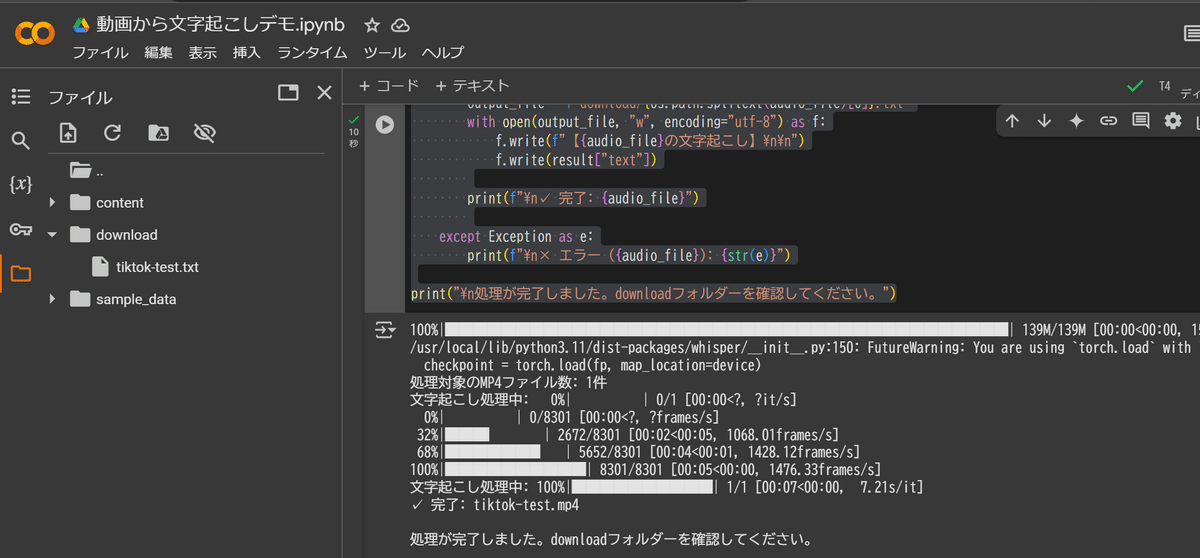
print("\n処理が完了しました。downloadフォルダーを確認してください。")
以下のように「処理が完了しました」と表示されたら、downloadファイルに文字起こしされたテキストデータが格納されます。
精度を上げるためのコツ
Whisperのようなモデルは高精度ですが、特に専門用語や漢字の誤認識が発生することがあります。以下の方法で精度を向上させることができます。
コツ1: モデルの選択
Whisperにはモデルサイズが5つ存在し、サイズが大きいほど精度が上がっていきます。結果に応じて調整してみてください。
model = whisper.load_model("medium") # または "large"、"turbo"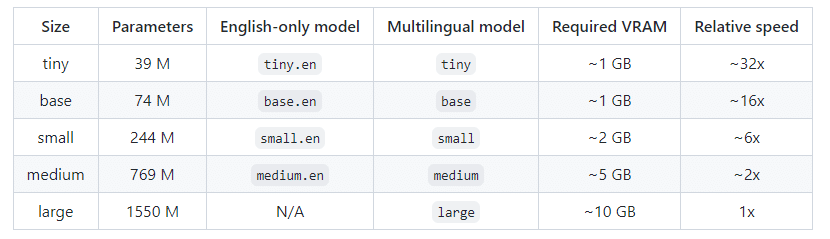
※ただし、Colaboratoryの無料版ではメモリ制限があるため、largeモデルを使用する際には注意が必要です。
コツ2: 言語の指定
transcribe関数にlanguageパラメータを明示的に指定することで、精度が向上する場合があります。日本語の音声を処理している場合は、language="ja" を指定してください。
result = model.transcribe(“音声ファイル名”, language=”ja”)コツ3: プロンプト(prompt)の活用
transcribe関数にinitial_promptパラメータを使用することで、文字起こしのヒントを与えることができます。例えば、特定の分野の音声データであれば、関連するキーワードやフレーズをプロンプトとして与えることで、精度を向上させることができます。
result = model.transcribe("audio.mp3", language="ja", initial_prompt="宇宙、量子力学")コツ4: 音声データの品質改善
音声データの品質が低い場合、文字起こしの精度が低下します。Audacityなどの無料の音声編集ソフトを利用して、ノイズを除去したり、音量を調整したりすることを検討してください。
コツ5: ChatGPT APIと組み合わせる
Whisperで得られた書き起こし結果を、APIを使ってChatGPTのような生成AIで内容の構成・要約や分析など、より高度な処理も実現できます。
留意点:
WhisperをAPI経由で利用すると、利用した分だけ料金が発生します。
【従量課金制】1分ごとに約0.006ドル、日本円に換算すると1時間利用した場合約50〜60円。
💡コストをかけたくない方は、Google ColaboratoryやGitHubにあるオープンソースを使えば無料です。
おわりに
お疲れ様でした!これでGoogle Colaboratoryを使った動画コンテンツの文字起こしの手順は完了です!今回の記事が少しでも役に立てれば幸いです🐇
急なトラブルが発生した場合や、Web開発・AI連携についてのご相談があれば、ぜひお気軽にお声掛けください。
\アイデアや意見交換も大歓迎です/
最後まで読んでくださり、ありがとうございました🌱