
分類モデルの予測結果を補正 - CalibratedClassifierCV

機械学習の分類問題では、予測結果の「キャリブレーション」を行うと精度が向上することがあるらしい。ただ、実際に試してみたけれど、LightGBMやCatBoostのような強力なモデルでは、効果が限定的な気もする。いや、でも、もしかしたら理解や使い方が不十分なのかもしれない。もう少し詳しく勉強して、実践を重ねる必要がありそうだ。
機械学習における分類問題では、モデルが出力する確率の信頼性が重要です。特に、医療や金融などの分野では、予測確率が実際の確率とどれだけ一致するかが意思決定に直結します。
1. 分類問題のキャリブレーション
キャリブレーションとは、分類モデルが出力する確率を、実際の確率に近づけるための調整プロセスです。例えば、あるモデルが「このサンプルは70%の確率でクラスAに属する」と予測した場合、その予測が実際に70%の確率で正しいかどうかを確認する必要があります。
キャリブレーションを行うことで、モデルの予測確率が現実の確率により近づき、信頼性の高い予測ができるようになります。
2. 基本的な考え方(Isotonic Regression)
Isotonic Regressionは、モデルが出力した予測確率の順序を保ちながら、実際の確率に近づくように調整する手法です。具体的には、「目的変数が1のサンプルの予測確率が、目的変数が0のサンプルの予測確率より高い」という関係が正しく反映されるようにします。
import numpy as np
import pandas as pd
from sklearn.isotonic import IsotonicRegression
# サンプルデータ(5行)
y_true = np.array([0, 0, 1, 1, 1]) # 実際のラベル
y_pred_probs = np.array([0.3, 0.5, 0.6, 0.4, 0.9]) # モデルが出力した予測確率
# Isotonic Regressionの適用
calibrator = IsotonicRegression(out_of_bounds='clip')
y_calibrated = calibrator.fit_transform(y_pred_probs, y_true)
# キャリブレーション結果の確認
df_result = pd.DataFrame({
'Actual data': y_true,
'Predicted': y_pred_probs,
'Calibrated': y_calibrated
})
print("Isotonic Regression Results:")
print(df_result)
Isotonic Regression Results:
Actual data Predicted Calibrated
0 0 0.3 0.0
1 0 0.5 0.5
2 1 0.6 1.0
3 1 0.4 0.5
4 1 0.9 1.0この例では、Isotonic Regressionを使って予測確率を調整しました。調整前の予測確率と比較して、調整後の確率(Calibrated)は実際のラベルにより近づいています。このように、シンプルなデータセットでもキャリブレーションの効果が確認できます。
3. 実践的なキャリブレーション(CalibratedClassifierCV)
より実践的なキャリブレーション手法であるCalibratedClassifierCVを用いて、モデルのキャリブレーションを行います。この例ではRandomForestをベースモデルとして使用しています。
from sklearn.calibration import CalibratedClassifierCV, CalibrationDisplay
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
# サンプルデータセットの作成
X, y = make_classification(
n_samples=3000, n_features=50, n_informative=10, n_redundant=10,
n_classes=2, flip_y=0.05, random_state=42
)
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# RandomForestモデルの定義と訓練
model = RandomForestClassifier(n_estimators=50, random_state=42)
model.fit(X_train, y_train)
# CalibratedClassifierCVによるキャリブレーション
calibrated_model = CalibratedClassifierCV(estimator=model, method='sigmoid', cv=5)
calibrated_model.fit(X_train, y_train)
# キャリブレーション前後のテストデータに対する予測確率を取得
uncalibrated_test_probs = model.predict_proba(X_test)[:, 1]
calibrated_test_probs = calibrated_model.predict_proba(X_test)[:, 1]
# キャリブレーション前後のAUCを計算
auc_before = roc_auc_score(y_test, uncalibrated_test_probs)
auc_after = roc_auc_score(y_test, calibrated_test_probs)
print(f"\nAUC before calibration: {auc_before:.4f}")
print(f"AUC after calibration: {auc_after:.4f}")
# キャリブレーション前の状態をプロット
fig, ax = plt.subplots(figsize=(10, 6))
CalibrationDisplay.from_predictions(y_test, uncalibrated_test_probs, n_bins=10, name="Before Calibration", ax=ax)
# キャリブレーション後の状態を同じプロットに追加
CalibrationDisplay.from_predictions(y_test, calibrated_test_probs, n_bins=10, name="After Calibration", ax=ax)
# タイトルを追加して表示
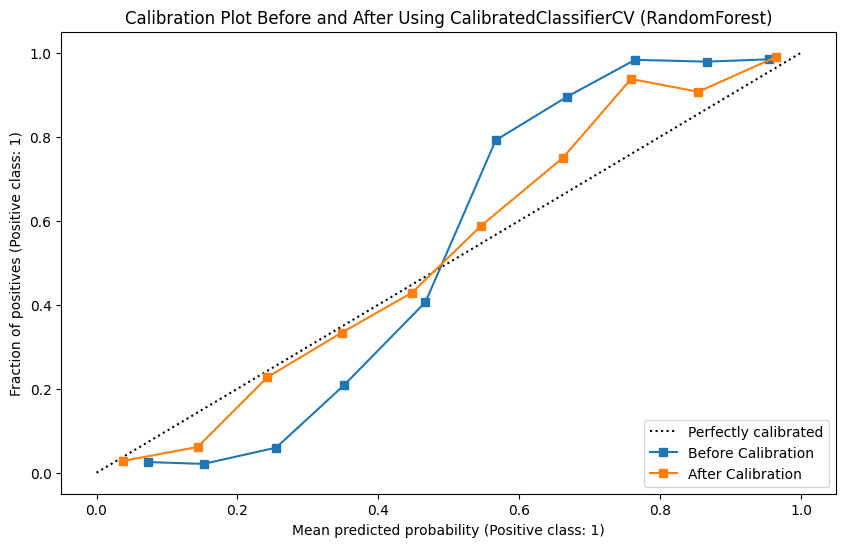
plt.title("Calibration Plot Before and After Using CalibratedClassifierCV (RandomForest)")
plt.show()
AUC before calibration: 0.9684
AUC after calibration: 0.9755キャリブレーションプロットを確認すると、キャリブレーション前後のモデルの予測確率の分布がどのように変化したかが視覚的に示されています。
まとめ
CalibratedClassifierCVは、分類モデルの予測確率をより現実に近づけるための有用なツールです。ただし、すべての状況で効果があるわけではありません。精度の高いモデル(例: LGBMやXGBoost)では、キャリブレーションの効果が限定的な場合もありますが、予測確率の信頼性が重要な場合には検討する価値があります。
キャリブレーション手法の選択では、sigmoidやisotonicの適用条件を理解し、データの特性に応じて使い分けることが大切です。また、キャリブレーションによる過適合のリスクを避けるために、結果は必ずテストデータで確認しましょう。
計算コストも考慮が必要です。キャリブレーションがパフォーマンス向上に寄与するかを見極め、リソースを効率的に使うことが求められます。特にツリーベースのモデルでは、キャリブレーションが不要なこともあるため、そのままの予測精度を確認した上で判断するのが良いでしょう。
これらの点を考慮し、キャリブレーションの必要性を慎重に判断することが重要です。
この記事が気に入ったらサポートをしてみませんか?