
免疫力のあるシステムとは

掃除も終えた土曜の昼下がりに、コーヒー飲みながら3月10日に公開されたデジタル庁が主催するGovtech Meetupの5回目を視聴。
その中で「ゆるさや余白を作る(疎結合する)ことで免疫力のあるアーキテクチャを作る」「分散データをつないでいく仕組み」をテーマとした話の部分で、デジタル庁CAの江崎さんがこんなコメントをしていて、思わず食いつきました。(注:多少意訳しております)
LOD、リンクトオープンデータというのがあって、これはID(識別子)の問題が一番大きくなってくる。考えている大きなシステムの中でちゃんと一意のIDを持ってること、そこをどう作るかというのを毎日本丸さん達が考えているわけです。そのためには「そのIDというものがどういうものだったら信用できるのか」というところが必要で、とてもパワフルで力のある自治体もあるし、そうじゃない自治体もある。そういう中で国としては信用できるサービスを提供しますので、それを使いたい方はぜひ使ってくださいと。他の非常にトラスタブルな同じサービスを民間等が作るかもしれないけど、国は少なくともデジタル庁などにいる最高のエンジニアを使って、最高のトラストサービスというのを提供し、それを自治体や民間が「機能」として使っていただいて、そのデータの信用度を保つっていただくことができるというのが、今考えている全体のアーキテクチャの中でのとてもに重要なポイントになります。それによって分散しているデータであっても信用度を保つことができるのか、根本的な部分を他の省庁とも連携しながら一生懸命考えているところです。
LOD(正式名称:Linked Open Data)は、World Wide Webの生みの親であるティム・バーナーズ=リーが提唱した「セマンティック・ウェブ」をベースにしたデータ処理のための方法論です。
Linked Open Data(リンクト・オープン・データ、略名: LOD)は、ウェブ上でコンピュータ処理に適したデータを公開・共有するための技術の総称である。従来のウェブがHTML文書間のハイパーリンクによる人間のための情報空間の構築を目的としてきたことに対応して、Linked Open Dataでは構造化されたデータ同士をリンクさせることでコンピュータが利用可能な「データのウェブ」の構築を目指しており、セマンティックウェブの形成に重要な技術となっている。
そして2013年に横浜市金沢区で「かなざわ育なび.net」を開設した時に、私が採用したデータアーキテクチャがLODでした。

育なび.netについては以前noteにも記事を書いたので、ご興味あれば御覧ください。
それから早9年、江崎さんのコメントを聞いてちょっと上から目線っぽいですが「ようやくLODみたいな根本的アーキテクチャの話が表舞台で取り上げられるようになったかぁー」と感慨深い気持ちになりました。(共通語彙基盤で扱われてましたけど、どうもマニアにしか受けてない感じだったので。笑)
育なび.netは、LODをベースとして構築したデータから作られたシステムがいかにサスティナブルなものとなり得るかを証明するために作ったシステムです。
当時、記者発表をする時にボスから「日本初!みたいなのは書けないの?」と聞かれて、超技術的な話になって答えるのが大変なので「さーどうすかねー。(*'ω'*)」と適当にごまかしたことがあるのですが(ボスごめんなさいw)、実は行政が住民向けサービスにLODを採用したのは、日本初どころかもしかして世界初だったかもしれない…とちょっと思ってます。
その仮説は見事に証明され、育なび.netで使った約30種類のデータは複数の課で分散管理されていたにも関わらず、各課の業務サイクルの中にうまく入れ込むことで的確に更新作業が行われるとともに、データに埋め込まれたIDによって適切にリンクされ、育なび.netの様々なアップデートに貢献してくれました。
なぜLODを使うことでサスティナブルになったのか?
それは、LODがデータが持つ性質を最も「自然」に表現しているものだったからです。
育なび.netでは、各課から提供されるオープンデータを元に区民に対して様々な情報提供を行いますが、ひとつの事物に対して関連する情報が1つの機関から提供されるとは限りません。
例えば「公園」を例にすると、
環境創造局 公園の所在地、広さ、座標
区土木事務所 公園に設置した遊具の種類、遊具のメンテナンス情報
区地域振興課 公園で開催されるイベントの情報
区総務課 避難所になっている場所
こんな感じに色々な部署から公園に関連するデータが提供されることがあり得ます。というか、それが自然です。
LODでは、まずそれぞれにしっかりとしたIDを定義し、そこに対して情報を紐づけていく「グラフ構造」を持たせます。
公園の例でさらに言うと、まず環境創造局から「野島公園」に関する基礎情報が提供されたとしたら、こんな感じに書いていきます。

次に管理事務所から「野島公園の駐車場」のデータが提供されたとします。
LODは、元のデータに付け足すのではなく「IDを関連づける」ことでデータ同士の連携をします。
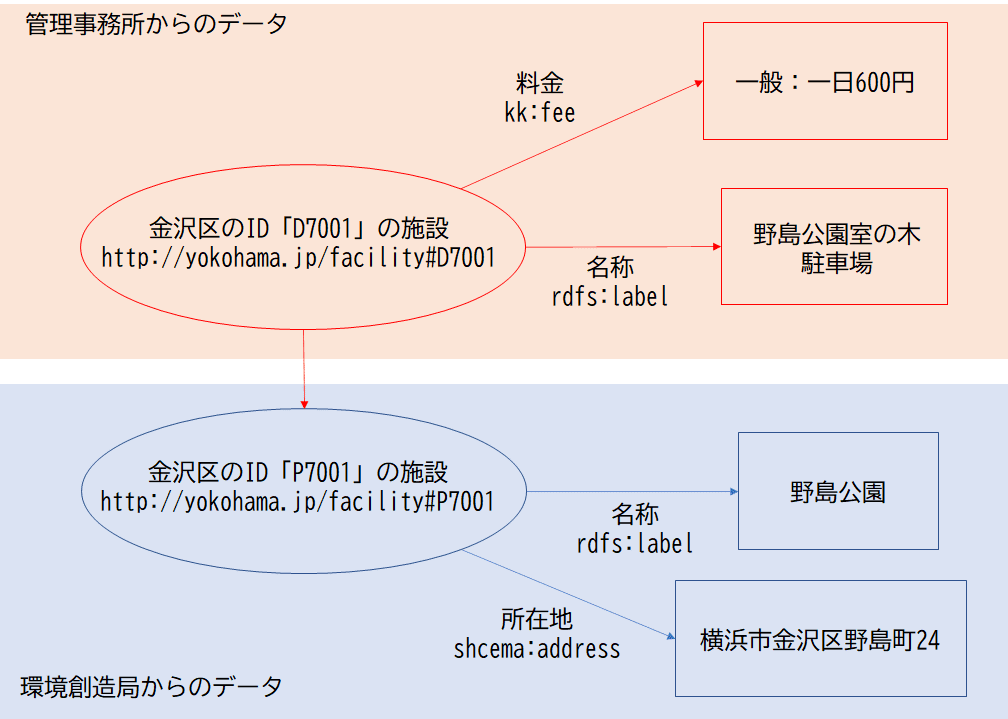
配列構造のデータベースに比べて、グラフ構造はデータ項目の追加が容易であるとともに、より複雑な検索条件に対応しやすいという利点を持っています。例えば「金沢区内にある広域避難場所で100台以上の駐車場を持つ公園の所在地は?」というような複雑な検索でも、SPARQL(スパークル)というLOD用の問い合わせ言語を用いてキーワードを区切ったり、複数回検索を行うことなく結果を導き出すことができます。
育なび.netでは、最初にデータ提供があった時にこのIDを埋め込んだデータに直して各所管に提供し「このIDは絶対触らないでデータ更新してね!」とお願いをした上で、更新されたデータをオープンデータとして公開してもらいます。
育なび.net側では、それを拾ってグラフ型データベースに変換・ストアし、それを使って常時新鮮なデータをユーザーに公開することができる、という仕組みです。

最初のデータを作るのと、それを各所管課の業務サイクルのどこに埋め込むのが良いかを探るところが手間がかかりますが、それさえ終わってしまえば常にフレッシュなデータが自動的に提供されることになるので、年度ごとの更新の際にも、担当である私はほぼ手間をかけることなく更新作業が完了していました。(まさに左うちわw)
LODのすごさは、同じルールのもとに作られているデータであれば、それが日本全国に散らばっていても、極端な話世界中に散らばっていてもHTTPリンクを辿ることで確実に捕捉することができるという点です。
ただし、そのための環境を作るのが最も大変な点でもあります。
マイナンバーを想像してもらえればわかりますが、IDというのは「一意」でないと意味がないので、それを誰がどう振り出すかという問題があります。またデータの意味-それが名前なのか料金なのか-をきちんと埋め込むために、例えば名称であれば「label」をちゃんとプロパティとして設定してね!ということを徹底することも必要です。日本の場合は「共通語彙基盤」というものを作ってこれを行おうとしています。(ちなみに私は行政サービス(個々の手続)にこのIDが必要だなーと思い、ユニバーサルメニュー普及協会で行われていた「PSID(public Service ID)」の策定検討に去年まで関わっていました。)
究極の面倒くさがりを自称する自分としては「みんながLODでデータ公開してくれれば、例えば育なび.netみたいなアウトプットサービスの質向上だけに注力できるのになー」と思うところなのですが、デジタル庁をはじめとして色々なところで議論が起こりつつある現状はとても嬉しいですし、自分としてもできることを引き続きやっていこうと思う土曜の昼下がりでした。
よければサポートお願いします!めっちゃ励みになります!