
【それPythonでできます】距離やベクトル計算、そして加速していく時間も!?

こんにちは。すうちです。
今回は、ひさしぶりにPythonのプログラムを使った投稿です。
--
はじめに
エンジニアという仕事柄、プログラムを書いてテストしたり、その前に何か調べてどう作るか考えたりする日々を過ごしています。
開発過程で計算結果や答えを得る場合、入力を決めた後は関数(自作やライブラリ含む)に任せるので、面倒なことはプログラムを書いてパソコンにやって頂いている訳です。
これはPythonに限った話ではないですが、プログラムのメリットは今まで人間が直接関わってた作業の自動化にあると思います。
以降、そんなプログラムを使った例をいくつかあげてみます。
ざっくり距離を知りたい(2次元)
例えば、地図アプリで目的地までの距離を知りたい場合があると思います。Googleマップなどは調べたい範囲を線で結んで距離を測定する機能があります。

試しに東京駅(出発)からコレド日本橋(目的地)まで線を引いて、距離を測定してみると711.31mと表示されました。
既に答えは出ているので、あえてプログラムでやる必要はないですが、地図を画像(各画素を座標)と見立てて考えてみます。

たとえば目的地までの経路に直角三角形があるとして、それらの頂点座標がわかれば三平方の定理で距離(A+B)を計算できそうです。以下、Python プログラムです。
import numpy as np
import math
# 距離20mの画素幅
pix_20m = abs(1906-1837)
pix_m = pix_20m/20
# 三角形の各頂点座標
xy0 = (102,1200)
xy1 = (656,1200)
xy2 = (656,560)
xy3 = (656,46)
xy4 = (1713,560)
# 距離A
w0 = (xy1[0]-xy0[0])
h0 = (xy3[1]-xy1[1])
d_A = math.sqrt(w0**2 + h0**2)
# 距離B
w1 = (xy2[0]-xy4[0])
h1 = (xy3[1]-xy2[1])
d_B = math.sqrt(w1**2 + h1**2)
# 距離A+B
d_AB = (d_A + d_B)
d_AB_m = d_AB/pix_m
print(f' d_A: {d_A:.1f} pix, d_B: {d_B:.1f} pix, d_AB: {d_AB:.1f} pix, d_AB_m: {d_AB_m:.1f} m')計算結果
d_A: 1280.1 pix, d_B: 1175.3 pix, d_AB: 2455.4 pix, d_AB_m: 711.7 m
結果は 711.7mでした。三角形の線は後から引いて頂点座標はマウスでおよその位置をペイントソフトで見た値なので誤差も含まれますが、わりと近い値が出ました。
プログラムの補足
計算で得られる距離A,Bはあくまで画像上の距離なので、実際の距離に換算する必要があります。これは地図右下(赤枠)の20mスケール(画像では約69画素分)を利用しました。※最後のd_AB_mを求める計算
距離を計算する(3次元~N次元)
続いて3次元に話を移します。順番前後しますが、(X ,Y, Z)の意味は後述します。
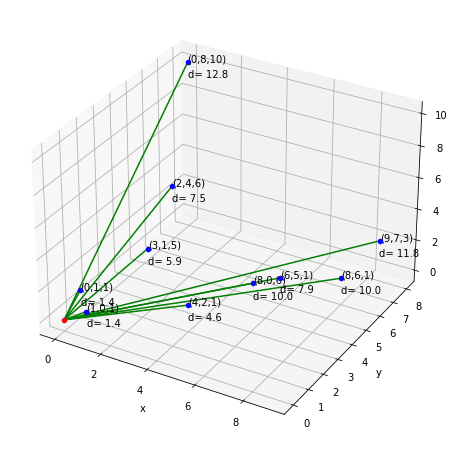
以下、Python プログラムです。
import numpy as np
import random
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 距離計算の関数
def calc_distance(x_diff, y_diff, z_diff):
distance = np.sqrt(x_diff**2 + y_diff**2 + z_diff**2)
return distance
# データ生成(ランダムN個)
key = 167
random.seed(key)
print(f'seed={key}')
num = 10
dim = 3
min_val, max_val = 0, 10
xyz_pos = []
for loop in range(num):
xyz = []
for n in range(dim):
val = random.randint(min_val, max_val)
xyz.append(val)
xyz_pos.append(xyz)
# データPlot & 距離計算
fig = plt.figure(figsize=(16,8))
ax = fig.add_subplot(111, projection='3d')
for i, (x,y,z) in enumerate(xyz_pos):
if i == 0:
(x0,y0,z0) = (0,0,0)
ax.scatter(x0, y0, z0, color='red')
x_diff, y_diff, z_diff = (x0-x), (y0-y), (z0-z)
distance = calc_distance(x_diff, y_diff, z_diff)
print(f' distance[{i:02}]: {distance :.1f} \t| (x0,y0,z0)=({x0}, {y0}, {z0}), \t(x,y,z)=({x}, {y}, {z})')
ax.plot([x0,x], [y0,y], [z0,z], color='green')
ax.scatter(x, y, z, color='blue')
ax.text(x,y,z, f'({x},{y},{z})')
ax.text(x,y,z-1, f'd= {distance:.1f}')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
plt.show()プログラムの補足
2点間 (X,Y),(X',Y')の距離は三平方の定理で計算しましたが、3次元も考え方は基本同じです。2点間の全ての差 (X,Y,Z),(X',Y',Z’)の2乗和平方根で求められます。
プロットした例は、データがないと何もできないので、今回はランダム生成した値を使いました。random.randint(min_val, max_val) は指定範囲(引数は最小、最大)のランダム値を返します。これで複数個の(X ,Y, Z)を作っています。
あとは原点(0,0,0)とそれ以外の(X,Y,Z)間の距離を繰り返し計算しています(calc_distance)。
図に描けるのは3次元までなので、今回は3次元にとどめましたが、上記の距離はN次元に増えても計算上は可能です。※同様に(X0,X1,X2,…Xn)と(X0',X1',X2',…Xn')の差から求められる
これって何に使えるのか?(例:単語の特徴抽出、オススメ機能など)
前置き長くなりましたが、3次元以上になると一般的にベクトルとして扱います。ベクトルは複数の数値を一つのまとまりで扱い、ある特徴を表現することができます。
例えば、オススメ機能などはユーザや商品をベクトル化してその特徴量(購買した/しない、見た/見ない等の行動)を使って実現できます。
他にSNSのテキストから単語を抽出して、類似した意味の単語はベクトルで近い位置に配置される特徴を利用する方法もあります。
具体的にはベクトル間の類似度や前述の2点間の距離を計算して、それが近ければ両者の特徴が似ていると判断します。
さらに詳しく知りたい方は、こちらの記事がわかりやすいです。
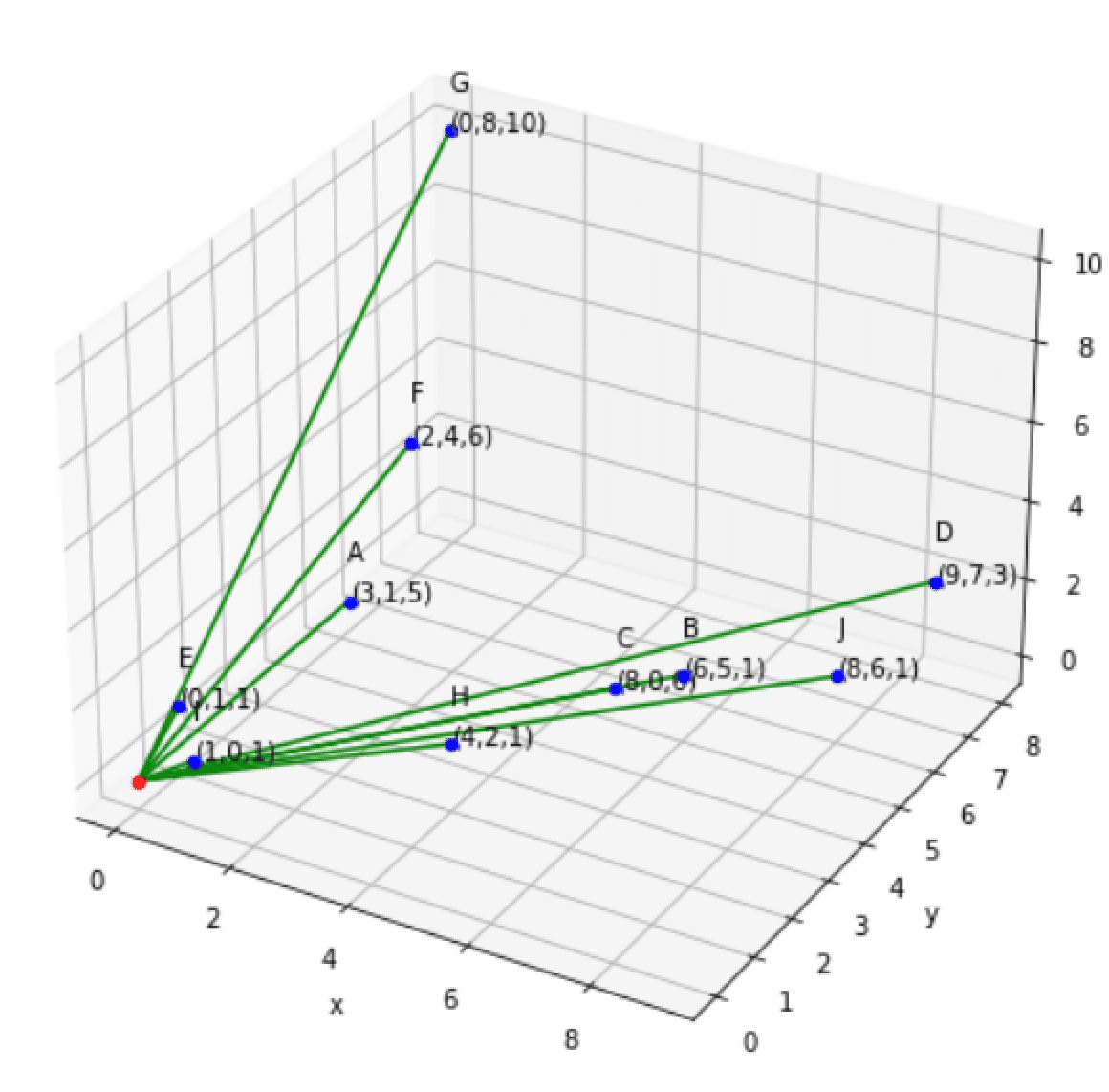
ここで、ベクトルのイメージと類似度の計算をnoteに置き換えてみます。
以下noteユーザのベクトルがあるとして、意味は左から
(スキされた数、フォローされた数、コメントされた数)とします。
Gさん:(0, 8, 10)
Bさん:(6, 5, 1)
Jさん:(8, 6, 1)
コサイン類似度の関数は引用先と同じです。Bさんを基準にGさんとJさんと比べてみます。
# コサイン類似度
def calc_cossim(vec0, vec1):
return np.dot(vec0, vec1) / (np.linalg.norm(vec0) * np.linalg.norm(vec1))
# BさんとGさんの類似度
similarity = calc_cossim((6,5,1), (0,8,10))
print(f'Similarity(B,G): {similarity:.3f}')
# BさんとJさんの類似度
similarity = calc_cossim((6,5,1), (8,6,1))
print(f'Similarity(B,J): {similarity:.3f}')計算結果
Similarity(B,G): 0.496
Similarity(B,J): 0.998
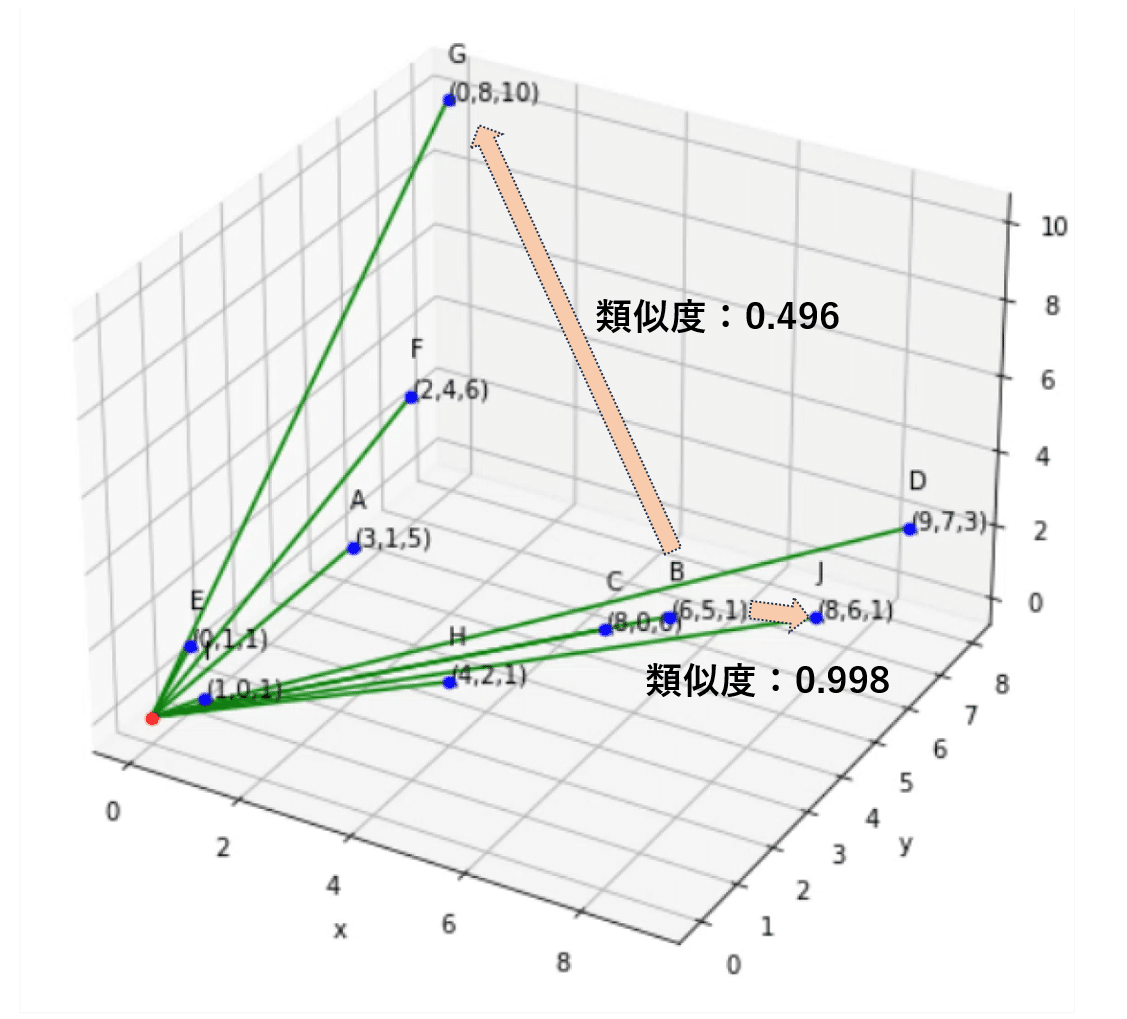
コサイン類似度は、1に近いほど類似度が高く、逆に-1は正反対を意味します。この結果からBとJのユーザは特徴が似ている。BとGはさほど似てないと言えます。
余談:人生の加速する時間を見える化してみる
最後に余談ですが、気づけばもう8月…
年々時間が経つのが恐ろしく早く感じます…汗
ふと以前読んだこの記事のことを思い出し、自分でもPythonのプログラムでやってみました。
1年の体感時間は、年齢に比例して加速する(1年=365日/年齢)計算で可視化すると、確かに私の一年はすごく短い。。。

以下、上記の前提に基づく、あくまで1歳の頃を基準にした体感の話ですが、、、
age30: 12.2 days(1year)
age40: 9.1 days(1year)
age50: 7.3 days(1year)
age60: 6.1 days(1year)
だそうです…汗
こんなこともPythonでできます。。。
プログラムを使って身近で思いついた例を紐付けてみましたが、伝わったかどうかは置いといて、今回はこの辺で…笑
最後まで読んで頂き、ありがとうございました。
--
参考書籍:
つくりながら学ぶ! PyTorchによる発展ディープラーニング
小川雄太郎 (著)
人生は図で考える 後半生の時間を最大化する思考法
平井 孝志 (著)