
今際の国のアナタ - 強化学習による行動生成エンジンを用いたゲーム開発
今回は、Netflixオリジナルシリーズ『今際の国のアリス』の公開を記念して、エナジードリンク『ZONe』とコラボレーションした、"本能"のみで操作する新感覚ブラウザゲーム『今際の国のアナタ』について、Qosmoが担当した人工知能部分を取り上げたいと思います。
まずはじめに、本ゲームの元となった『今際の国のアリス』について簡単に説明させていただきます。
『今際の国のアリス』は、 麻生羽呂さんによる漫画が原作で、2020年12月に、Netflixオリジナルシリーズ『今際の国のアリス』としてドラマ化されました。
『今際の国のアリス』では、山﨑賢人演じる有栖良平(アリス)らが生死を賭けたデスゲームへと参戦していくことになるわけですが、ではもし自分が同じデスゲームへと参加したら、と考えてみるとどうでしょうか?もし今アリスと同じゲームへと参加することになったとしたら、いったいどのような行動を取るのでしょうか?
『今際の国のアナタ』は、「『今際の国のアリス』の作品の中で行われる生死をかけた"げぇむ"に、もしも自分が参加することになったら」という想像の世界を、AIを使用してリアルに再現したブラウザゲームです。プレイヤーはゲーム開始時に出題されるいくつかの質問に答え、その回答に応じてキャラクターにパラメータが割り振られます。その後、プレイヤーは自分ではキャラクターを操作することはできず、そのキャラクター自身が割り振られたパラメータに応じて様々な行動を取り、ゴールを目指して物語が展開していくことになります。
本ゲームにおいて、Qosmoはゲーム開発に加えてキャラクターの行動生成エンジンの開発を行いました。この行動生成エンジンについて、詳しく見ていきたいと思います。
ゲームAI
ゲームにおけるAIは、ゲームAIというジャンルとして、学術的なAI研究と交わりながら発展してきました。特にゲームのキャラクターAIとしては、「ステート・マシン」や「ビヘイビア・ツリー」といった手法が古くから使われてきました。これらの手法は現在でも広く使われており、単体あるいは組み合わせる形で様々なゲームに実装されています。今回の「おにごっこ」においても、鬼や仲間のキャラクターのAIには「ビヘイビア・ツリー」を使用しています。ビヘイビア・ツリーは柔軟でカスタマイズしやすいため、「おにごっこ」においても特定のキャラクターAIの実装には最適な選択肢でした。
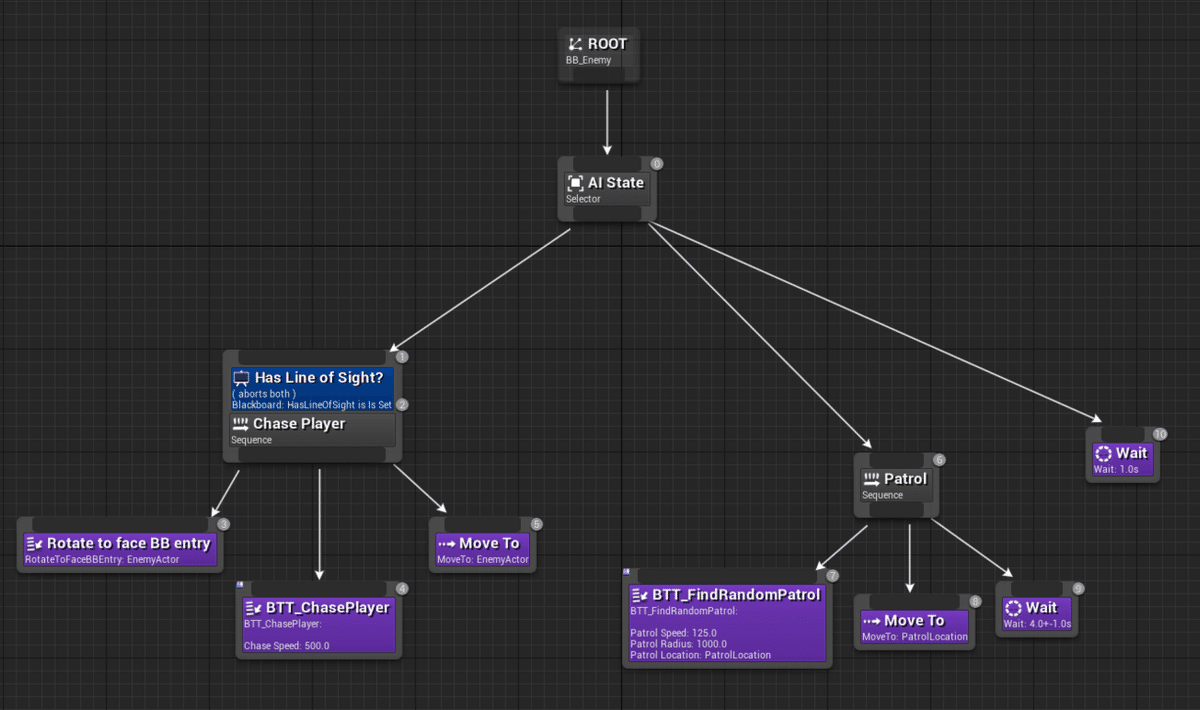
Unreal Engine4でのビヘイビア・ツリーの一例。様々なノードを組み合わせ、状態に応じてキャラクターの動きを制御します。
強化学習
しかし、『今際の国のアナタ』においては、プレイヤーのパラメータは性格診断の回答に応じて決定されるため、そのパラメータの数は膨大なものとなります。それら特定のパラメータ1つ1つに対応するビヘイビア・ツリーを用意するのはほぼ不可能に近いでしょう。そこで、プレイヤーのAIに関しては、強化学習を用いて実装することにトライしました。強化学習は機械学習の一種で、エージェントが試行錯誤を通じて環境に次第に適応していくような学習の枠組みになります。
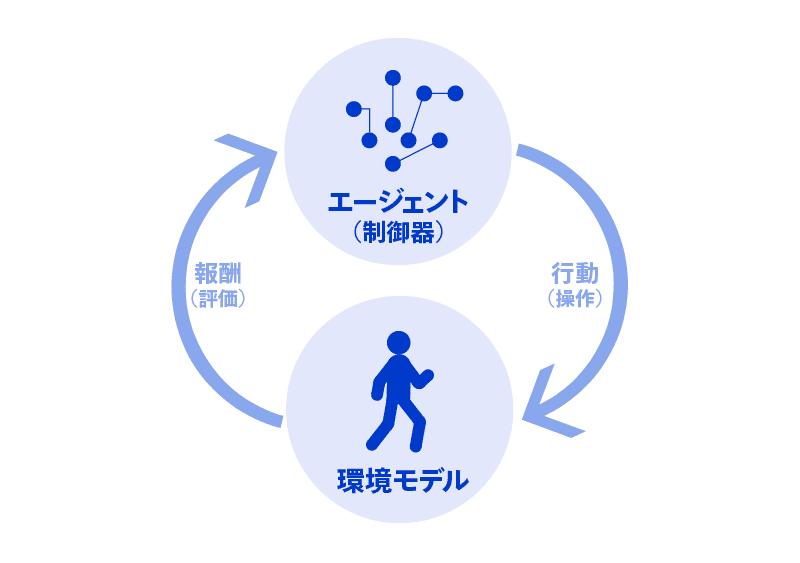
強化学習の仕組み
性格診断の結果に応じて、プレイヤーには「俊敏」「記憶」「敏感」「友好」「筋力」の5つのパラメータが割り振られます。そして、そのパラメータに応じて多様な振る舞いを生成する必要がありました。例えば「俊敏」が高いプレイヤーは一度に遠い距離まで移動することができる、「友好」が高いキャラは味方とうまく連携することができる、など様々なバリエーションが考えられます。強化学習を使用することで、このような多様な振る舞いを生成できないか?というのが今回の大きなチャレンジでした。
とはいえ強化学習を実際のゲームで活用した事例はまだ少なく、研究の分野においても強化学習の環境はOpen AIのgymなどシンプルな環境に限定した論文が多いのが現状です。そのため、ゲームのルール自体はなるべくシンプルに努めることで、学習がうまくいくように調整する必要がありました。
ゲーム×強化学習
今回は、すでに出来上がったゲーム環境に対して強化学習を行うのではなく、ゲーム開発と強化学習を並行して行う必要がありました。そのため、実装環境としてUnityが提供するML-Agentsを採用しました。ML-Agentsを使用することで、Unityで開発したゲーム環境内でキャラクターエージェントの訓練を行うことができます。内部的には、ML-AgentsがUnityとPython間の通信を取り持つことで、Python(使用したML-Agents Release3時点ではTensorFlowがバックエンドでしたが、Release10以降PyTorchがデフォルトとなっているようです)スクリプトで学習を行っています。そのため、学習済みモデルのUnity側での読み込みや、Tensorboardを用いたロギングなどもデフォルトで対応しており、必要に応じてPythonスクリプトを記述することで独自のアルゴリズムを試すこともできます。
ゲーム開発にUnity、そして強化学習のライブラリとしてML-Agentsを使用したことで、ゲームバランスの調整と学習の調整サイクルを素早く回すことができました。ゲームにおける強化学習の活用はまだまだ手探りな部分も多いため、このゲーム開発と学習のサイクル速度は非常に重要でした。
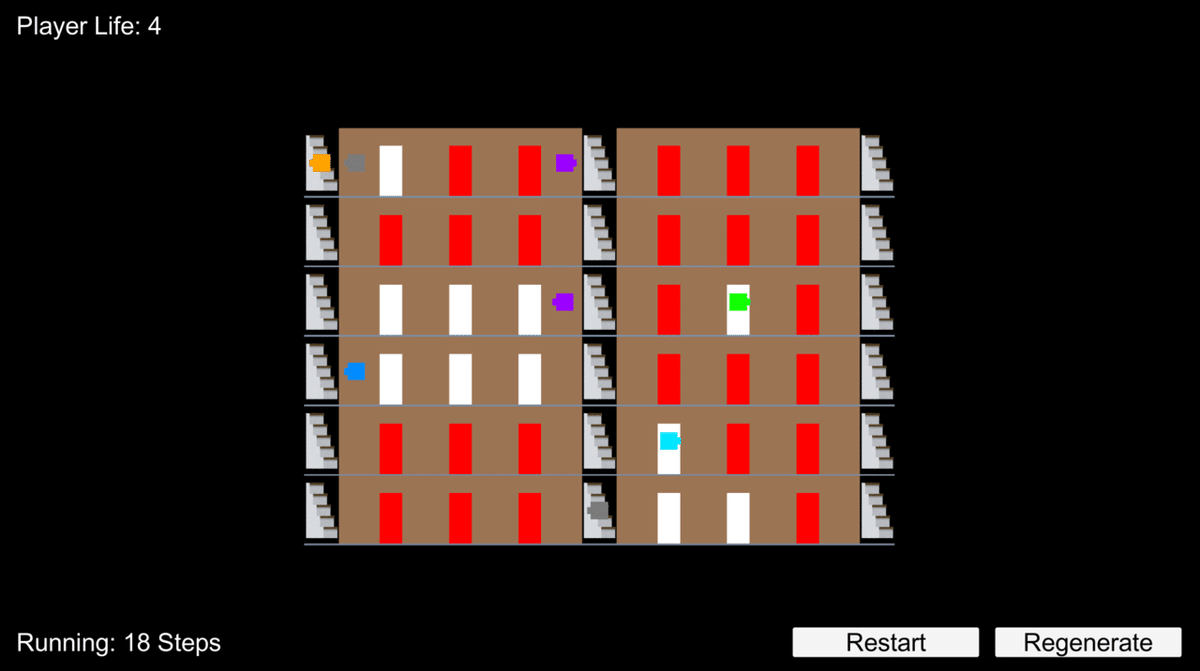
Unityでの学習時のデバッグ画面
学習フェーズでは、プレイヤーキャラクターは「できるだけ早く」「できるだけ鬼と遭遇しない」「できるだけ多くのドアを開ける」ように学習を進めていきます。この際、プレイヤーキャラクターにはパラメータとして性格診断の結果を組み込んでおり、その値の組み合わせに最適化された行動を取るようになります。このパラメータは「俊敏」「記憶」「敏感」「友好」「筋力」の5つにそれぞれ5段階で振り分けられ、各パラメータ毎にそれぞれ異なった効果を持ちます。「俊敏」は一度に移動できる距離、「記憶」は味方がゴールの位置を教えてくれた際の記憶時間、「敏感」は視野の広さ、「友好」は仲間の出現頻度、「筋力」は体力に影響します。その結果、「俊敏」が高い場合には鬼から素早く逃げることができますし、「敏感」が高い場合には鬼の接近をいち早く感知することができるはずです。このようにして、性格診断に応じて様々な特徴が生まれるようにゲームの設計を行いました。
『今際の国のアナタ』においては、ユーザーはプレイヤーキャラクターの行動を見守ることしかできないため、時に思いがけない行動を取るキャラクターに対して一喜一憂することもあるでしょう。こうした体験は、強化学習を利用したことによってもたらされた体験であったように思え、とても新鮮でした。
また今回は、Qosmoがゲーム開発・強化学習部分を担当、実際のゲームのフロントエンド部分はsalvo Inc. さんに担当していただき、非常にクオリティの高いゲームへと仕上げていただきました!






実際のゲーム画面
まとめ
以上、『今際の国のアナタ』についてご紹介させていただきました。ゲームにおける強化学習についてはまだまだ事例も少ないですが、大きな可能性を秘めているように思えます。特にML-Agentsを使うことで、ゲームのみならず様々な用途で強化学習を応用できると思います。例えば、堀川淳一郎さんによる強化学習を用いたプロシージャル・モデリングの実験などがあります。また、Unreal Engineでもバージョン4.26.0において、Python環境とUE4プロジェクトの連携を取り持つUE4MLというプラグインがリリースされています。ゲームエンジンと強化学習の組み合わせには様々な可能性があり、本プロジェクト『今際の国のアナタ』もその一例となれば幸いです。
Credit
企画制作
電通+電通テック+Qosmo+salvo
CD
尾上永晃
企画
岸裕真、水野泰雅、並木隼人
AD
河野智、三上裕之、富樫健一、三浦優太
D
玉井裕和、小久保夏江
Pr
栗原孝行、川内史、高橋大輔
PM
安江沙希子、安藤英洋、山崎詩織
SE
植草史仁
AE
山本和毅、水越悠輔、櫻井一起
TD
徳井直生
マシンラーニング+ゲーム開発
中嶋亮介
PRG+リサーチャー
Bogdan Teleaga
FE
池山春夢、三上裕之、田中義人
サーバーサイドエンジニア
川上祐介