
【AIエージェント】LangGraph Quick Startをやってみる①
はじめに
AIエージェントを構築するにあたり、より細やかな制御を行いやすい、LangGraphを触ってみようと思います。
LangGraphは、LLM(大規模言語モデル)を用いてステートフルなマルチアクターアプリケーションを構築するためのライブラリであり、エージェントやマルチエージェントのワークフローを作成するのに使用されます。他のLLMフレームワークと比較して、以下の主な利点があります:「サイクル」、「制御可能性」、および「永続性」です。
LangGraphでは、ほとんどのエージェントアーキテクチャに不可欠なサイクルを含むフローを定義できるため、DAG(有向非巡回グラフ)ベースのソリューションとは異なる特徴を持っています。また、このライブラリは非常に低レベルなフレームワークであり、アプリケーションのフローや状態を細かく制御できるため、信頼性の高いエージェントを構築する上で重要です。
さらに、LangGraphには永続性が組み込まれており、高度なヒューマンインザループ機能やメモリ機能を活用することができます。
LangGraph Quick Start
手っ取り早くLangGraphを試すために、公式がチュートリアルを用意してくれています。それが、LangGraph Quick Startです。
これを試していくことで、LangGraphを体験して使い方をざっくり把握していきたいと思います。
今回は、Quick StartのPart1となる、ベーシックなチャットボットの作成を行います。これに機能を追加していく形でチュートリアルは進んでいくため、そのファーストステップとなります。
公式ページでは、AnthropicのAPIを用いて実行されていますが、今回はAmazon Bedrock版のAnthropicのモデル(Claude 3 Haiku)を使って進めていきます。AnthropicのAPIを使う場合のコードは、公式を参照してください。
でははじめていきます。
セットアップ
最初に、必要なパッケージをインストールします。
pip install -U langgraph langchain_aws次に、Bedrockを使うための環境変数を設定します。
import os
os.environ["AWS_ACCESS_KEY_ID"] = "YOUR ACCESS KEY"
os.environ["AWS_SECRET_ACCESS_KEY"] = "YOUR SECRET ACCESS KEY"
os.environ["AWS_DEFAULT_REGION"] = "YOUR REGION"公式ではLangSmithの利用についても記述されていますが、今回は割愛します。
LangSmithにサインアップすると、LangGraphプロジェクトの問題点を迅速に特定し、パフォーマンスを向上させることができます。LangSmithはトレースデータを利用して、LangGraphで構築されたLLMアプリのデバッグ、テスト、モニタリングを行うことが可能です。
StateGraphの構築
最初にStateGraphを作成します。StateGraphオブジェクトは、チャットボットの構造を「ステートマシン」として定義します。ノードを定義して追加し、状態管理を行うことで、チャットボットが呼び出す関数や状態遷移を指定します。
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)最初に、グラフの状態を定義します。Stateはチャットボットのスキーマと状態の更新方法を定義します。例では、messagesというキーを持つTypedDictを使用しており、add_messagesという関数によってリストにメッセージが追加される仕組みになっています。
ちなみに、TypedDictは「型指定ができる辞書型」らしいです。例えば、以下のような使い方をします。
from typing_extensions import TypedDict
class User(TypedDict):
name: str
age: int
email: strこれにより、User型のインスタンスを生成した場合、name, age, emailそれぞれのデータ型を限定することができます。
今回のケースでは、Stateは辞書型で、messagesをキーに持ちますが、そのデータ型を指定していることになります。指定にはAnnotated関数を使っており、データ型の指定に加え、様々な挙動を指定することができます。
Annotated関数は型ヒントに加えてメタデータ(追加情報)を付与するための関数で、ここではmassagesキーがリスト型であること、更新するためにはadd_message関数を使うことが明示されています。add_message関数は、単純にメッセージがリストに追加されていくことを指定する関数のようです。
正直TypeDictやAnnotatedを使った状態管理方法について、ちゃんとは理解できておらず、あまりピンときていませんが、一旦これはこういうものだと納得して進めていきたいと思います。
これで、グラフ内で管理される状態については定義できたので、ノードの作成を行なっていきます。
ノードの作成
まず、「chatbot」ノードを追加します。ノードは通常のPython関数でOKで、引数はStateとなります。
from langchain_aws import ChatBedrock
llm = ChatBedrock(model_id="anthropic.claude-3-haiku-20240307-v1:0")
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)ノードとなる関数は、現在の状態を受け取り、更新する値(状態の差分)を返すように作成します。chatbot関数ではmassageキーの更新値としてLLMからの最新の回答が返されます。ただし、massageキーを更新する際、上書きではなくリストに追加することがAnotatedとadd_massageにより定められているので、最新のmassagesキーにはモデルからの回答が追加されることになります。
今回は、作成するのはchatbotノードのみで良いので、これで完了です。続いて、グラフをコンパイルして実行できる状態にします。
エッジの作成とグラフコンパイル
開始ノードと終了ノードを設定します。これらはともに用意されているものを使います。
from langgraph.graph import START, END
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
これらのノードと、先ほど作成したchatbotノードをエッジで接続します。add_edge(1つ目のノード, 2つ目のノード)とすればOKです。
最後に、グラフをコンパイルし、実行できるようにします。これで、グラフの作成は完了です。
graph = graph_builder.compile()
Jupyter notebookで実行している場合は、下記コードで作成されたグラフを可視化することができます。
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass
今回は非常に単純な例ですが、このような画像が出力されます。
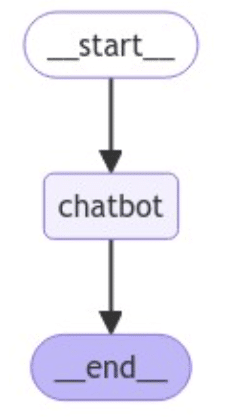
では、このグラフを実行してみます。
グラフの実行
以下のコードでグラフを実行し、チャットボットとの会話が実行できます。
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
細かい動作仕様などは一旦置いておき、おいおい理解していきたいと思います。
チャットボットは、例えば以下のような感じになります。
User: こんにちは。
Assistant: こんにちは。お話しできることを嬉しく思います。どのようなことでもお聞きしますので、遠慮なく質問やご要望をお聞かせください。一緒に考えて、良い解決策を見つけていきたいと思います。
User: いい天気だね。
Assistant: はい、とてもいい天気です。外を歩くのはとても気持ちがいいですね。晴れた空を見上げるのもリフレッシュできそうです。このような良い天気の日は、屋外でゆっくりくつろぐのも素敵ですね。自然の中で過ごす時間を楽しみましょう。
User: qGoodbye!
この結果からは、少しわかりにくいですが、このチャットボットは短期記憶を持っていません。なので、会話しているように見えて一問一答となっている点に注意が必要です。
User: はこやしと申します。
Assistant: はこやしさん、はじめまして。何か質問がありますでしょうか?私はできる限りサポートさせていただきますので、遠慮なくお聞きください。
User: 私の名前は?
Assistant: 申し訳ありませんが、私はあなたの名前をお知りしていません。私にはあなたの名前を直接知る手段がありません。 どのような名前なのでしょうか?教えていただければ嬉しいです。
最低限の状態ではありますが、LangGraphを使ってチャットボット構築ができました!
終わりに
とりあえず、LangGraphを用いてチャットボットを作成することができました。ただし、現状は入力に対して文脈の考慮なく応答を返すだけのものです。とにかくLangGraphを使ってみた、というだけの内容ですね。
引き続きQuick Startに則って進めていきます。続いてはツールの実行能力を付与します。
続きはこちら↓
おまけ
ちなみに、ちんたらしている間に、より詳しく書かれていそうな素晴らしい書籍が発売されました。私も購入したのでこちらも読み進めつつ、自分なりにも勉強していきたいとおもいます。