
【Poke-Controller】音声認識(音声検知)のサンプルプログラム

はじめに
Poke-Controller上で、効果音(SE)を検知するサンプルプログラムです。
もともとは、ポケモンの色違いSEを検知したくて作りました。
他にも応用できるかと思いますので、自由に改変して使ってみてください。
プログラムは下記に格納しています。
サンプルプログラムの紹介
サンプルプログラムでは、e-shop起動時の効果音を検知します。
「Start」を押すと、効果音を検知する処理が開始します。
e-shop起動時の効果音を検知すると、「CAPTURE」ボタンを長押しして動画撮影した後、HOME画面に戻って処理を終了します。
(e-shop画面はキャプチャ不可ですが、他の場面では使えるかも)
実際のデモ映像はこちらです。
前提条件
利用にはPyAudioのインストールが必要です
過去の記事の項目「事前準備」を参考にしてください。
(人によって環境が違うため、記載のやり方ではできないかもしれません)
マイクなど他の入力デバイスがパソコンに刺さっていると、音声認識が上手くいかないことがあります。
上手くいかない場合は、マイクなどの入力デバイスを外してみてください。
大まかな仕組み
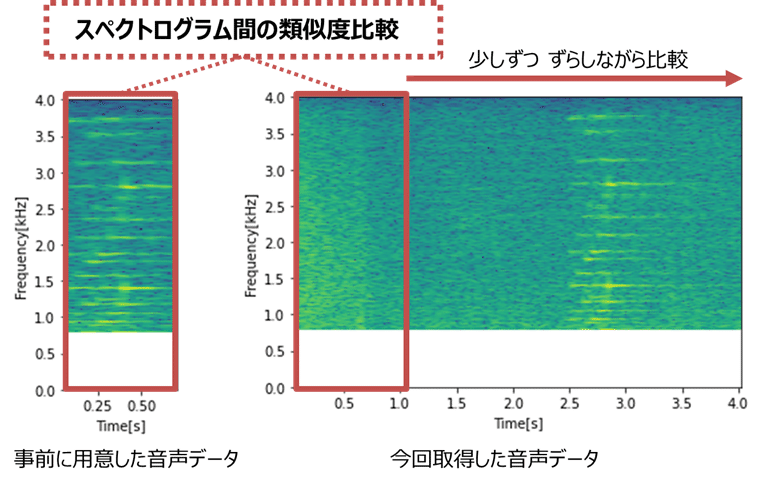
音声データの周波数を比較して、類似度を計算しています。
事前に用意した音声データのスペクトログラムを、今回取得した音声データのスペクトログラムに対して、少しずつずらしながら比較します。
類似度が閾値を超えた場合、検知したとみなします。
補足(仕組みに興味のある方向け、読まなくてOK)
プログラムの大まかな流れを記載します。
1.事前に用意した音声データを読み込み、スペクトログラムを作成
※サンプルプログラムはスペクトログラムのcsvを直接読み込み
※スペクトログラム作成後に低周波数帯域(約780Hz未満)をカット
2.約2秒に1回、比較用の音声データを取得
初回のみ:今回取得した音声データ(約2秒)を利用
次回以降:前回取得した音声データの後半(約1秒)と、今回取得した音声データ(約2秒)を結合したものを利用
※取得する音声の切れ目で効果音が鳴っても検知できるよう、前回取得した音声データの後半部分を補完
3.項2で取得した音声データからスペクトログラムを作成
※スペクトログラム作成後に低周波数帯域(約780Hz未満)をカット
4.項1と項3で作成したスペクトログラムの類似度を計算
(1)項3の中から項1と同じ幅のデータを取得(項3´)
(2)項1と項3´の配列を転置後に1次元化してコサイン類似度を計算
(3)コサイン類似度が閾値以上の場合、検知したとみなす
(4)閾値未満の場合、項3から取得する幅を少しずらして比較
※項3から取得する幅をずらして最後までいったら項2に戻る
サンプルプログラムの使い方
1. ダウンロードしたファイル「Sound_CompSx.py」を格納する
下記フォルダに格納してください
パス:Poke-Controller-master\SerialController\Commands\PythonCommands

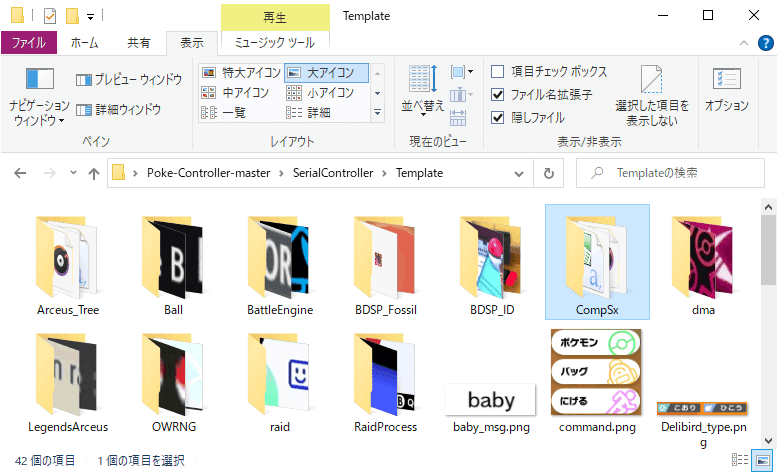
2. ダウンロードしたフォルダ「CompSx」を格納する
下記フォルダに格納してください
パス:Poke-Controller-master\SerialController\Template\
3.ホーム画面で「SoundTest_音声比較_v1.0」を実行する
「Start」すると音声認識処理を開始します。
手動(Controller)で「e-Shop」のアイコンを選択すると、「ピコーン」という効果音が鳴るので、その音を検知して終了します。
自動で「e-Shop」のアイコンを選択するようにしたい場合は、下記のコードを追加してください。
※190行目あたり
while stream.is_active():
try:
dummycount+=1 #デバッグ用の無駄な処理、プログラム流用時は不要なので削除する
'''
#音声認識処理中に実施したい処理を記載する
'''
####ここからが追加する処理####
self.press(Hat.BTM, 0.2, 1.0) #Nintendo Switch Onlineにカーソル
self.press(Hat.RIGHT, 0.2, 1.0) #ゲームニュースにカーソル
self.press(Button.A, 0.2, 3.0) #ゲームニュースを選択
self.press(Button.B, 0.2, 3.0) #ホーム画面に戻る
self.press(Hat.RIGHT, 0.2, 1.0) #e-Shopにカーソル
self.press(Button.A, 0.2, 3.0) #e-Shopを選択
self.press(Button.B, 0.2, 3.0) #ホーム画面に戻る(この前に音声検知されそう)
####ここまでが追加する処理####
#音声認識処理を終了(try内を無限ループさせたくない場合はコメントアウトを解除)
#stream.stop_stream()
except KeyboardInterrupt:
break※サンプルプログラムは、音声ファイル「hikaku.wav」を使用しません!
サンプルプログラムでは、「hikaku.csv」との比較をしています。
「hikaku.wav」は再生できないダミーファイルです。
(画像と違って音声はキャプチャ機能がなく、取得したものの公開は良くない気がするため、hikaku.wavの直接配布はしていません)
プログラムを改変する場合は後述する手順で修正してください。

プログラムを利用する場合のポイント
サンプルプログラムを改変する際のポイントを記載します。
1.比較用の音声データを準備(必須)
まずは比較したい音声データを準備します。
サンプルプログラムで取得する音声と同じサンプリングレート(=8,000)である必要があります。
同梱している音声データ録音用のサンプルプログラムを使用すると、同じサンプリングレート(=8,000)の音声を作成できます。(Sound_Rec.py)
「Start」を押してから8秒間の音声を録音、「recdata.wav」を出力します。


作成した音声は8秒間と長すぎるので、必要な長さに編集します。
フリーソフト「Audacity」などを使って短くしてください。
サンプルプログラムは1秒未満の音声データを想定しています。
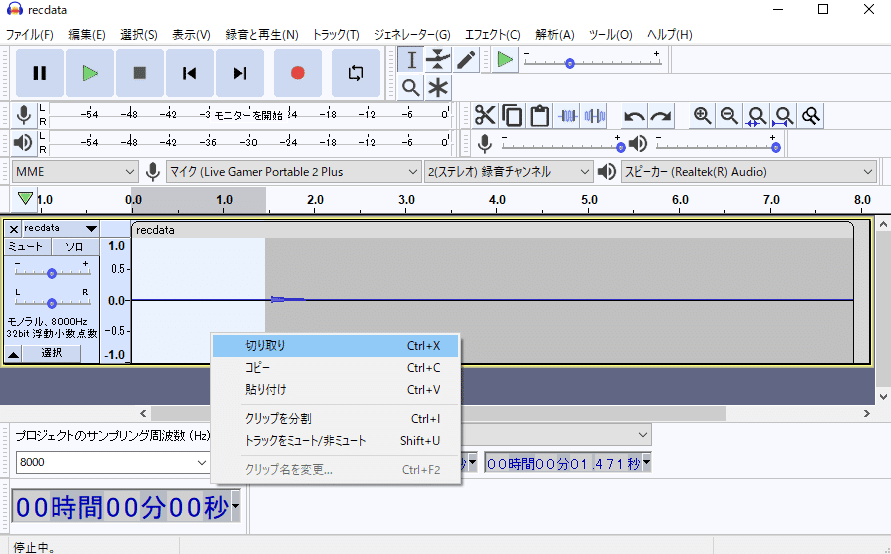
ドラッグして範囲選択後、切り取りを選択すれば音声をカットできます
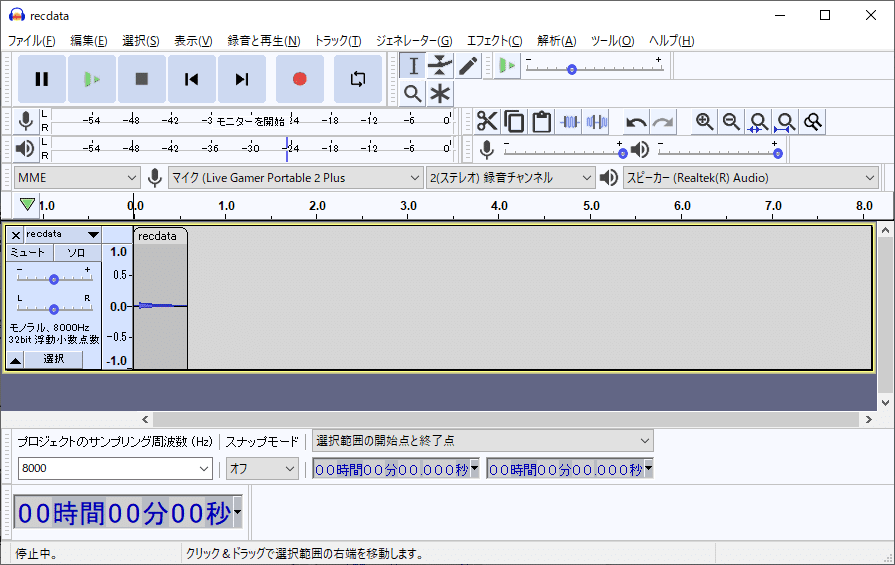
必要な長さに編集した後、書き出します
短くした後、「hikaku.wav」を上書きして保存します。
これで比較用の音声データが準備できました。
2.プログラムの編集(必須)
サンプルプログラムは「hikaku.wav」を使用しないので修正が必要です!
下記を編集してください。
1.175行目「hikaku.wav」を読み込む処理のコメントアウトを削除
2.177行目「hikaku.csv」を読み込む処理をコメントアウト
※172行目あたり
'''
#事前に用意した音声データの比較は①音声データのwav, ②スペクトログラムのcsvのどちらかを選択する
'''
#①事前に用意した音声データを読み込む処理
#freqs2, times2, Sx2 = wavsignal('Template/CompSx/hikaku.wav')
#②または事前にcsv変換したスペクトログラムを読み込む処理
Sx2 = np.loadtxt('Template/CompSx/hikaku.csv', delimiter=',', dtype='float32')
これで、「hikaku.wav」を使用するようになりました。
その他、下記の要領で自動化に必要な処理を適宜、追加してください。
3.メイン処理の追加(必須)
自動化プログラムに必要な処理を追加してください。
音声認識の関数は「audiosx()」で定義しています。
必要な前処理は「audiosx()」の前、
必要な後処理は「audiosx()」の後に記載してください。
※40行目あたり
def do(self):
'''
#必要な前処理を入力
'''
#音声認識処理
self.audiosx()
'''
#必要な後処理を入力
'''
音声認識中に実行したい処理は、try文の中へ記述してください。
サンプルプログラムでは何もせず、dummycountを+1し続けています。
try文中の最後にある「stream.stop_stream()」のコメントアウトを外すと、音声認識が無限ループせず終了するようになります。
※190行目あたり
while stream.is_active():
try:
dummycount+=1 #デバッグ用の無駄な処理、プログラム流用時は不要なので削除する
'''
#音声認識処理中に実施したい処理を記載する
'''
#音声認識処理を終了(try内を無限ループさせたくない場合はコメントアウトを解除)
#stream.stop_stream()
except KeyboardInterrupt:
break
4.音声検知の閾値を修正したいとき(任意)
音声検知の閾値は0.8が初期値です。
この値は、使用する場面によって大きく変わるため変更が必要です。
誤検知が多い場合は閾値を上げ、検知できない場合は閾値を下げます。
※94行目あたり
#閾値以上の場合に一致したと検知(今回は0.8)
if maxv > 0.8:
print('---------------------音声を検知!----------------------')
myh = str(int(((self.ends - self.starts) / 3600) % 24))
mym = str(int(((self.ends - self.starts) / 60) % 60))
mys = str(int((self.ends - self.starts) % 60))
print('経過時間' + myh + '時間' + mym + '分' + mys + '秒')
self.press(Button.CAPTURE, 1.0, 1.0)
self.press(Button.HOME, 0.3, 0.3)
self.finish()「maxv > 0.8」の「0.8」の値を修正してください。
「0~1」の範囲で、「0.95」や「0.6]など値を変更します。
5.1秒以上の音声を検知したいとき(任意)
サンプルプログラムは1秒未満の音声データと比較する想定です。
1秒以上の音声データを比較したいときはプログラムの修正が必要です。
未確認ですが、下記の修正で対応できると思います…!
(少し面倒なので、1秒未満の長さに編集する方が楽かも)
※55行目あたり
#音声認識
def audiosx(self):
CHUNK = 16384 #事前に用意した音声データの再生時間の2倍以上かつ、2のべき乗の値(1秒以下ならこれで大丈夫なはず)
global RATE
RATE = 8000 #事前に用意した音声データと同じサンプリングレート
「CHUNK = 16384」の値を、修正します。
事前に用意した音声データの再生時間に応じた値に変更が必要です。
計算方法が少しややこしいですが、まず下記を計算します。
事前に用意した音声データの再生時間(秒)×8,000(サンプリングレート)
上記で計算した値の1.5倍より大きい、2のべき乗の値に設定してください。
例えば、音声データの再生時間が1.4秒の場合、
1.4 × 8,000 = 11,200
11,200 × 1.5 = 16,800
この16,800は、現在のCHUNK=16384よりも大きいです。
CHUNKより大きい値の音声は検知できない可能性があります。
※音声を比較する処理は、このCHUNKの値(再生時間)毎に行うため
初回のみ、CHUNKの幅の再生時間
次回以降、前回取得したCHUNKの後半部分+CHUNKの幅の再生時間
の音声データを使って、音声比較を行います
そして、CHUNKの値は2のべき乗でないと処理できません。
(これはPyAudioの仕様だと思います。それとも音声処理的な仕様?)
そこで、CHUNKを16384の2倍にします。
16,384 × 2 = 32,768
※55行目あたり
#音声認識
def audiosx(self):
CHUNK = 32768 #事前に用意した音声データの再生時間の2倍以上かつ、2のべき乗の値(1秒以下ならこれで大丈夫なはず)
global RATE
RATE = 8000 #事前に用意した音声データと同じサンプリングレート「CHUNK=32768」とすることで、音声データの再生時間が1.4秒でも、検知できるようになる(はず)です。(未確認!)
あとがき
何かに使えるかもと思い、サンプルプログラムを公開しました。
しかし、音声認識を使う場面はあまり多くないかもしれません。
だいたいの自動化は画像認識があれば事足ります。
例えば、ポケモンの固定リセットの色厳選をしたい場合でも、エンカウントしてから「たたかう」までの時間差を計算すれば色違いの判別は可能です。
自動化できなくても、乱数調整した方が早いこともあります。
そこで、乱数調整が確立されておらず、画像認識よりも早く検知できることから、レジェンズアルセウスの音声認識自動化を作成していました。
しかし、時代は進むもので、レジェンズアルセウスも乱数調整で色違い厳選ができるようになってきました。
偉大な方々の検証のおかげです、非常にありがたいことです…!
音声認識じゃないとできないことは多くなさそうです。
ただ、技術の選択肢が増えるのは悪いことではないと思います。
上手い使い方は、きっと頭の良い人が考えてくれます!
よろしくお願いします!