
超解像OCRの実験記録② ~文字の超解像モデルの作成~

導入
前回は超解像OCRのうち、文字認識部分の実験を記事にしました。今回はその続きで、文字の超解像の実験について記録していきます。

文字の超解像
超解像について
まずは一般的な超解像について軽く説明します。
低画質の画像を高解像度化させるのに有効な手段として、ルールベースの手法も存在しますが、ディープラーニングを用いた超解像がここ最近の主流です。

https://arxiv.org/abs/2107.10833
超解像の学習は低解像度の画像(LR)と高解像度の画像(HR)のペアを用意し、LR画像をHR画像に近づけるように畳み込み層などを用いたモデルが使われます。ディープラーニングを用いた超解像の起点となったのは2014年に発表されたSRCNNです。3層の畳み込み層で低解像度の画像を入力とし、出力画像を高解像度画像に近づけます。各ピクセル間の平均二乗誤差(MSE)を損失関数として学習させるもので、従来の手法よりも高い品質の画像に変換することが可能になりました。

https://arxiv.org/abs/1501.00092
しかしMSEだけでは超解像した画像(SR)はぼやけた画像になりやすく、そのため生成とは別に識別のためのDNNを加えたGAN (Generative Adversarial Network) の技術を応用し、MSEに加えて識別器による損失関数を加えることでよりよい高画質化を可能にしたモデルが出ています。
文字の超解像
超解像は文字認識にも応用されています。読み取りづらい文字列画像に対し、初めに超解像で読みやすい字に変換することで文字認識を容易にすることができます。

https://arxiv.org/abs/2005.03341v3
文字列の超解像の場合は単に画像の情報だけでなく、文字列の持つ系列情報も加味して高解像度化を図ります。具体的にはCNNに加え、RNNやAttention構造を組み込んだモデル構成になります。
有名な文字の超解像モデルはTSNR (Text Super-Resolution Network) です。

https://arxiv.org/abs/2005.03341v3
論文はこちら。特徴としては、
焦点の違うカメラで撮影したリアルなHR-LR画像のペアをデータセットに使用( = TextZoom)
モデルには位置補正のためのSTN(前回記事でも軽く紹介)を超解像前に組み込む
CNNの後にBiLSTMに通すことで系列情報を読み取る
LossにはMSE以外にGP Lossを使用
エッジの勾配の差のMAEを損失とすることで、ぼやけた箇所をシャープにするように学習

https://arxiv.org/abs/2005.03341v3
などが挙げられます。
今回はこのTSNRの派生系であるTPGSR(Text Prior Guided Scene Text Image Super-Resolution)というモデルを使用します。
TPGSR
TPGSRは超解像のネットワークに文字認識モデルが接続され、画像から文字列を認識し、その情報も加味して高画質化するモデルです。論文はこちら。
この画像から得た文字列の情報をTextPriorと呼び、CNNで得た画像の特徴量に結合してRNNに通し、画像を生成します。

https://arxiv.org/abs/2106.15368
またこのTextPriorを生成するモデルには今回用いたCRNNを利用することができます。
LR画像、HR画像それぞれからTextPriorを抽出し、その平均絶対誤差(MAE)とKLダイバージェンスを合わせてTP Lossとします。
これを画像のピクセル間のMSE Lossと合わせて学習させます。
さらにTPGSRは、生成したSR画像をもう一度生成器に入れることを数段階繰り返して精度向上を果たしました。論文ではデータセットにもよりますが3~5段階あたりでベストになります。

https://arxiv.org/abs/2106.15368
TPGSRの学習
ここからTPGSRの学習に入っていきます。
今回使うデータセットは、上記で文字認識用に作成した文字列画像をHR画像とし、前処理によりHR画像を低画質化させてLR画像を作成、これらのペアを超解像用のデータセットとします。
画像の劣化処理
高画質の画像を低画質化させる必要がありますが、なるべく実際の低解像度の画像に近づける処理が、Real-ESRGANという超解像モデルの論文で紹介されています。

https://arxiv.org/abs/2107.10833
この論文では、実世界の画像の劣化は単なるブラーやリサイズなどの変換よりも複雑であると指摘し、また劣化は一段階以上になる場合も多々あることから、2ステージの劣化プロセスを踏むという処理を行っています。
このように前処理の劣化プロセスを改善することで超解像の改善を可能にしました。
今回はこのReal-ESRGANの前処理を使って低解像度画像を生成することにしました。

学習環境
データセットは作成した文字列画像20万枚
画像サイズ: 32×320
SRの繰り返し数: 3ステージ
損失関数は3つ
SRとHRのピクセル間の平均二乗誤差 (MSE Loss)
HRとSRをCRNNに通した際のそれぞれのTextPrior間のL1Loss (TP Loss)
エッジの勾配差のMAE (GP Loss)
⇒ MSE Loss : TP Loss : GP Loss = 1 : 1 : 1e-4
AdamW, 学習率1e-4, バッチサイズ8
Google ColabのV100で大体1日ほどでLossが収束しました。
検証時はLR, HR, SRそれぞれを前回記事で作成した文字認識モデルに通しました。SRの精度がLRを超えて徐々にHRの精度に近づいていくのが確認できました。
結果
低画質の画像に対して学習したTPGSRを適用しました。
ある程度のぼやけがクリーンになったり、文字を考慮したような超解像も時々見受けられます。

一番左は上記の劣化処理を施した画像、真ん中と右は実際の画像
右の「順」は川の三本線が復元されているようにも見える?
しかし、ブレが大きかったり人間が読むのも難しいものに対しては上手に復元できませんでした。

また、実際の低画質画像はものによってはアルゴリズムでの生成は難しそうに感じました。
よって、アルゴリズムで生成したLR-HRペアではなく、実際にLR-HRペアを撮影したデータセットを作ってみようと思います。
LR-HRペアを作成
TextZoomと呼ばれるデータセットは、実際に低画質と高画質のシーンテキスト画像のペアを撮影したものです。これを学習させた超解像モデルは、アルゴリズムにより生成された低画質画像を使うよりも、品質の高い高解像度化が可能になったそうです。

https://github.com/JasonBoy1/TextZoom
TextZoomの日本語版はないため、自分でLR-HR画像のペアを作成することにしました。
ImageGeneratorで作成した文字列画像を並べて、iPadでピントを合わせた画像(HR)と、手前または奥へピントをずらした画像(LR)を撮影。大体150枚ほど撮影し、そこから検出された文字列画像は5万枚ほどになりました。

撮影環境は、ディスプレイを撮影したのでできるだけブレやモアレが少なくなるよう心掛け、またLR画像のぼやけ度合いや画面の明るさ、ディスプレイの傾きなどを適度に変えてモデルの汎化性能を向上できるようにしました。
またピントの変更に伴い位置が微妙にずれるので、検出前にAKAZEによる特徴量マッチングからLR画像の位置合わせを行い、HR画像の検出座標をそのままLR画像に適用して文字列画像のペアを生成しました。

これをもとに学習させた結果を以下に示します。
作成したデータセットで学習した結果
検証データに対しては論文に近いような高画質化が見られました。文字の境目はもちろん、肉眼でぎりぎり読めない文字までも復元され、超解像度化によって文字認識モデルで正しく読めるようになった画像も多く存在しました。

ただ漢字は英語に比べて少し難しいように感じます。線の数など細かいところを見ると合わなかったりしています。

また、今回はピントずれの画像のみデータセットに加えたので、遠くからの撮影によって低画質になった画像などは、また少し劣化の仕方が異なり復元しにくいイメージです。汎用的なものを作成するにはまだまだ改善の余地があるように思えます。
おまけ: 「文字の超解像」の他の手法
Scene Text Telescope (STT)
TSNR後に出た論文。よりテキストにフォーカスするための構造に。論文はこちら。
シーケンスの情報を得るためにBiLSTMを利用していましたが、Attention機構にすると傾きや湾曲のあるテキストなどによりロバストに対応できるように。この構造をTransformer-Based Super-Resolution Network(TBSRN)と呼んでいます。

またピクセル間のMSE以外に二つの損失関数を導入。 SR画像とHR画像を、別で文字認識の学習をさせたTransformerモデルに通し、それぞれの出力テキスト間のCross Entropy Lossと、それぞれのAttentionマップ間のL1 Lossを算出します。
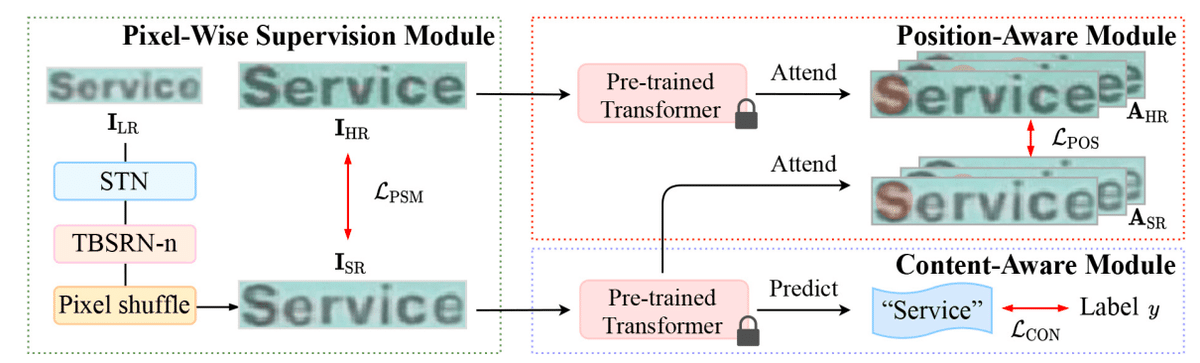
前者はContent-Aware Moduleと呼び、ただのCross Entropyではなく、似ている文字を区別させるために、文字同士の近さを重み付けしたWeighted Cross Entropy Lossを使用。重みは別で算出していて、文字の画像をVAEで学習させ、文字間の潜在表現から得られたユークリッド距離の逆数を重みにしています。これにより、(c, e)や(s, 5)など、近い文字同士の重みを高くすることで、似ている文字を区別しやすいような高解像度の画像を生成させることができます。
後者はPosition-Aware Moduleといい、画像内の文字領域に焦点が当てられたAttention mapを使用し、HRとSRのAttentionマップ間のLossを算出することでより文字領域に焦点を当てた画像を生成することができます。
Text Gestalt
文字レベルではなく、より詳細な筆画レベルまで焦点を当てたのがText Gestaltです。論文はこちら。
論文の著者は上述のScene Text Telescopeと同じです。
事前に学習されたTransformerの文字認識モデルを用意しますが、ラベルは以下のイメージのように、文字ラベルを筆画ラベルに変換して学習します。超解像の際にSRとHRをこのpre-trained Transformerに入れ、それぞれのAttentionマップ間のLoss (Stroke-Focus Module Loss, $${L_{sfm}}$$) を算出。

https://arxiv.org/abs/2112.08171v1
Text Gestaltによる結果
TPGSRにStroke-Focus Module Loss ($${L_{sfm}}$$) を加えて学習してみました。
うまくいった画像で言うと、以下のように ($${L_{sfm}}$$) ありの方では濁点を再現することができているように感じます。
STT、Text Gestaltは超解像モデルとは別でTransformerモデルを学習する必要がありますが(この記事には詳細は載せていません)、今回はそのモデルの認識精度がそこまで高くはありませんでした。うまく学習できれば漢字の細かい部分の復元などができるかもしれないので、今後の課題として取り組んでみたいです。

まとめ
OCRのために文字認識モデルと超解像モデルを学習してみました。
個人的にはどちらも満足のいく結果となりました。超解像の方はさらにデータセットのドメインを増やせればいいものに近づいていきそうな感覚が得られました。
手書き文字や縦書きなどにも対応できるモデルも作ることができれば応用範囲が広がると思うので今後はそちらもチャレンジできればと思います。
最後まで、読んでいただきありがとうございました。