
デバイス数の変化によって連合学習(federated learning)の性能がどのように変化するか検証する

はじめに
こんにちは。株式会社Rosso、AI部です。
近年、個人情報を保護しつつ機械学習を行う連合学習(federated learning)という新しい手法が登場しています。
ただし、連合学習を行う際は、従来の機械学習モデルと比べ、性能が悪化しないかどうかに留意する必要があります。
この観点を踏まえ、本記事では、連合学習を行う際に使用するデバイス数に着目。連合学習を行う際のデバイス数が変化した場合、性能が従来の機械学習モデルと比較してどのように変化するか、簡単な検証を行います。

連合学習の概要
機械学習でデータを使用する際には、個人の顔が映し出された画像や、性別、年収、住所などで構成されているテーブルデータなど、個人情報が入ったデータを取り扱うケースがあります。
そのようなデータを扱う場合、個人が特定されないようにデータを加工したり、個人情報の委託先に監督を行うなど、プライバシー保護に配慮して適切にデータを利用することが求められます。
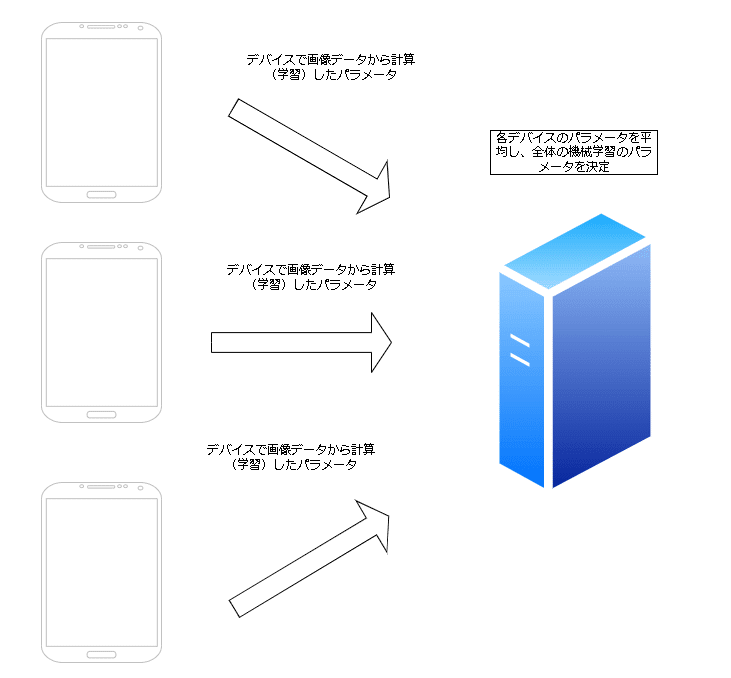
連合学習(federated learning)とは、各デバイス間で、学習モデルのパラメータや更新状況のみを共有することで、データを集約せずに機械学習モデルを学習させる手法のことです。従来の機械学習と違い、個人情報を保護しながら学習させることが可能です。
連合学習では、機械学習による計算を行う各デバイスのことをクライアントと呼び、各クライアントが計算した結果をサーバーに送信することで、一つのモデルの学習を可能にします。
これにより、個人情報など機密性の高いデータでも、外部に共有することなく、学習させることが連合学習では可能となります。
例えば、各個人のスマートフォンに保存された画像を使って、画像認識の機械学習モデルを学習するケースを考えてみましょう。
この場合、通常の機械学習モデルでは、学習に使う画像をサーバーに送信し、サーバーは送信された画像を元にパラメータの更新を行い、画像認識モデルの学習を行います。

この場合、サーバーには各スマートフォンの画像が保存されているので、プライバシーに関わる画像が含まれているとサーバーにその情報がいきわたってしまうデメリットがあります。
その点、連合学習では、パラメータの更新は各デバイス(この場合は各スマートフォン)が行い、サーバーは各デバイスから送られたパラメータを平均することで全体のモデルのパラメータ更新を行うため、通常の機械学習モデルの学習と違い、サーバー側に画像が共有されることはありません。
そのため、スマートフォンに保存された機密性の高い画像であっても、サーバーに共有することなく、学習を行うことができます。
連合学習は、googleが2017年に発表したFederated Averagingの手法が発端になっています。
連合学習の処理の流れは、下記のようになります。
①サーバーは、全てのクライアントからランダムに数個のクライアントを選択します。(client selection)
②サーバーは選択されたクライアントにグローバルモデルを配布し、モデルを配布されたクライアントは各自、保有するデータを使ってローカルで学習を行い、パラメータを更新します。(local update)
③更新されたモデルはローカルモデルと呼ばれ、各クライアントはサーバーにローカルモデルのパラメータを共有します。
④サーバーは共有されたパラメーターを平均し、グローバルモデルとします。(model aggregation)
連合学習の検証
上記のように、連合学習はプライバシー保護を行いながら学習を行いたい場合に威力を発揮する手法ですが、従来の機械学習に比べて、精度は担保されるのかという疑問が発生します。特定の状況下では、連合学習は従来の機械学習との精度は変わらないとされています。
本記事では、連合学習の際のデバイス数を変化させて、連合学習と従来の機械学習モデルの精度がどのくらい変化するのか、簡単な検証を行ってみます。
連合学習の手法としては、連合学習の元祖的な手法であるFederated Averagingを使用します。Federated Averagingの内容については、次項で説明します。
Federated Averagingの概要
まず、論文に記載されているFederated Averagingの疑似コードを和訳+補足事項を追加したものを掲載します。
Federated Averagingの疑似コードは下記のようになります。
インデックス$${k}$$で表される$${K}$$個のクライアントが存在し、 $${B}$$はローカルミニバッチサイズで、$${ E}$$ はローカル内のエポック数, $${η}$$は学習率とする。
$${t}$$は各ラウンドを表す。
サーバー側のアルゴリズム:
重み$${w_0}$$を初期化
for each round $${t=0,1,..}$$ do
$${m←max(C・K,1)}$$
( $${C}$$は全体のクライアントから参加するクライアントを無作為抽出する割合)
$${S_t←}$$mのクライアントから無作為抽出した集合
for each client $${k∊S_t}$$ in parallel do
$${w_{t+1}^k←ClientUpdate(k,w_t)}$$
$${w_{t+1}^k←∑^K_{k+1}\frac{n_k}nw^k_{t+1}}$$
($${n,n_k}$$ は全体のデバイス数と$${S_t}$$ 中のデバイス数をそれぞれ表す)
$${ClientUpdate(k,w) :}$$(クライアント側のアルゴリズム)
$${ℬ←(P_K}$$をバッチサイズBに分割させる。$${P_k}$$はクライアント$${k}$$が保有するデータである)
for each local epoch $${i}$$ from 1 to E do
for batch $${b ∈ B}$$ do
$${w←w-η▽ℓ(w;b)}$$
return $${w}$$ to server
(ここで$${▽ℓ(w;b)}$$ は損失関数の勾配を表す)
"Communication-Efficient Learning of Deep Networks
from Decentralized Data"
により、引用し和訳・補足
Federated Averagingでは、model aggregationを加重平均を取ることによって、連合学習を行っています。
(疑似コードの$${w_{t+1}^k←∑^K_{k+1}\frac{n_k}nw^k_{t+1}}$$ によって、グローバルモデルのパラメータが加重平均により更新されることが分かると思います。)
Federated Averagingでは、同一の初期値を取るモデルのパラメータを各クライアントの保有するデータでそれぞれ独立に更新し、最終的に更新したパラメータの加重平均により、全体のモデルのパラメータを更新しています。
最後に、Federated Averagingでは、計算に参加するデバイス数は十分に小さいと仮定されています。
連合学習の実装
本検証では、Intelが提供する連合学習のライブラリの一つであるopenFLを使って、検証を行ってみたいと思います。
GitHub - intel/openfl: An open framework for Federated Learning.
なお、同名のライブラリで、ゲームやアプリケーションを構築するためのフレームワークが存在するので、注意が必要です。
http://www.openfl.org/
openflのインストールは、下記のpipのコマンドにより実行します。
pip install openfl
今回、検証した環境は下記の通りになります。
CPU:AMD Ryzen 5 2600 Six-Core Processor
GPU:NVIDIA GeForce GTX 1050
メモリ:8.0GB
CUDA : 11.0
cuDNN :8.7.0
OS: Ubuntu 18.04 LTS
openfl 1.4
tensorflow 2.7.2
keras 2.7.0
また、題材としては、MNISTを使用して簡単な分類タスクを行い、デバイス数の変化による連合学習の検証を行っていきたいと思います。
まず、通常の機械学習モデルによるMNISTの分類タスクを行った結果、loss,精度,処理時間は下記のようになりました。
loss: 0.1360 精度 0.9598 処理時間(sec) 10.0054
このとき、検証に用いたコードは下記になります。
from __future__ import absolute_import, division, print_function, unicode_literals
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import time
s=time.time()
VALID_PERCENT = 0.3
(X_train, y_train), (X_test, y_test) = mnist.load_data()
split_on = int((1 - VALID_PERCENT) * len(X_train))
train_images = X_train[0:split_on,:,:]
train_labels = to_categorical(y_train)[0:split_on,:]
valid_images = X_train[split_on:,:,:]
valid_labels = to_categorical(y_train)[split_on:,:]
test_images = X_test
test_labels = to_categorical(y_test)
def preprocess(images):
#Normalize
images = (images / 255) - 0.5
#Flatten
images = images.reshape((-1, 784))
return images
# Preprocess the images.
train_images = preprocess(train_images)
valid_images = preprocess(valid_images)
test_images = preprocess(test_images)
feature_shape = (784,)
classes = 10
def build_model(feature_shape,classes):
#Defines the MNIST model
model = Sequential()
model.add(Dense(64, input_shape=feature_shape, activation='relu'))
model.add(Dense(classes, activation='softmax'))
return model
model = build_model(feature_shape,classes)
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels,epochs=5)
e=time.time()
t=e-s
loss, acc = model.evaluate(test_images, test_labels)
print('loss:',loss,'acc',acc,'time',t)
ここでは、エポック数を5に設定して学習をさせています。
次に、同じネットワークをopenflによる連合学習によって、学習をさせたいと思います。
openflの基本的な使い方としては、まず、FederatedDataSetにより、使用データを連合学習用のデータに変換します。その次に、FederatedModelに変換した連合学習用のデータと学習モデルを渡し、連合学習(今回はFederated Averaging)を行います。また、通常学習モデルのエポック数を5に設定したので、比較のため、override_configのaggregator.settings.rounds_to_trainを5に設定しました。
fx.run_experiment(collaborators,override_config={'aggregator.settings.rounds_to_train':5})
全体の連合学習の検証コードは下記になります。
import numpy as np
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import pandas as pd
import openfl.native as fx
from openfl.federated import FederatedModel,FederatedDataSet
import time
import csv
#デバイス数をiで指定する
def FedAveraging(i: int):
s=time.time()
#Setup default workspace, logging, etc.
fx.init('keras_cnn_mnist')
#Import and process training, validation, and test images/labels
# Set the ratio of validation imgs, can't be 0.0
VALID_PERCENT = 0.3
(X_train, y_train), (X_test, y_test) = mnist.load_data()
split_on = int((1 - VALID_PERCENT) * len(X_train))
train_images = X_train[0:split_on,:,:]
train_labels = to_categorical(y_train)[0:split_on,:]
valid_images = X_train[split_on:,:,:]
valid_labels = to_categorical(y_train)[split_on:,:]
test_images = X_test
test_labels = to_categorical(y_test)
def preprocess(images):
#Normalize
images = (images / 255) - 0.5
#Flatten
images = images.reshape((-1, 784))
return images
# Preprocess the images.
train_images = preprocess(train_images)
valid_images = preprocess(valid_images)
test_images = preprocess(test_images)
feature_shape = train_images.shape[1]
classes = 10
fl_data = FederatedDataSet(train_images,train_labels,valid_images,valid_labels,batch_size=32,num_classes=classes)
def build_model(feature_shape,classes):
#Defines the MNIST model
model = Sequential()
model.add(Dense(64, input_shape=feature_shape, activation='relu'))
model.add(Dense(classes, activation='softmax'))
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'],)
print(model.summary())
return model
#Create a federated model using the build model function and dataset
fl_model = FederatedModel(build_model,data_loader=fl_data)
collaborator_models = fl_model.setup(num_collaborators=i)
names = [str(k) for k in range(i)]
models = [collaborator_models[k] for k in range(i)]
zipped = zip(names, models)
collaborators = dict(zipped)
#Original MNIST dataset
print(f'Original training data size: {len(train_images)}')
print(f'Original validation data size: {len(valid_images)}\\n')
#Get the current values of the plan. Each of these can be overridden
print(fx.get_plan())
#Run experiment, return trained FederatedModel
final_fl_model = fx.run_experiment(collaborators,override_config={'aggregator.settings.rounds_to_train':5})
#Save final model and load into keras
final_fl_model.save_native('final_model')
model = tf.keras.models.load_model('./final_model')
#Test the final model on our test set
l,a=model.evaluate(test_images,test_labels)
e=time.time()
t=e-s
return l,a,t,i
if __name__ == '__main__':
#/resultfed.csvに結果を保存する
with open('./resultfed.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['loss', 'acc', 'time','device_num'])
writer.writerow(FedAveraging(2))
writer.writerow(FedAveraging(3))
writer.writerow(FedAveraging(5))
writer.writerow(FedAveraging(10))
writer.writerow(FedAveraging(15))
writer.writerow(FedAveraging(20))
writer.writerow(FedAveraging(50))
検証の結果、デバイス数を変えて、連合学習を行ったときのloss,精度、処理時間は下記の表の通りとなりました。

通常学習時の精度が0.9598なので、デバイス数が少ないときは、通常学習と連合学習の差はそこまで大きくなく、デバイス数が多くなるほど、精度が低下し、通常学習時より、精度の差が開いてしまうことが分かります。
図にすると、デバイス数が少ないときは、デバイス数が増加すると、急激に精度が低下し、ある程度のデバイス数以降は、デバイス数の増加につれ、なだらかに精度が低下するようです。

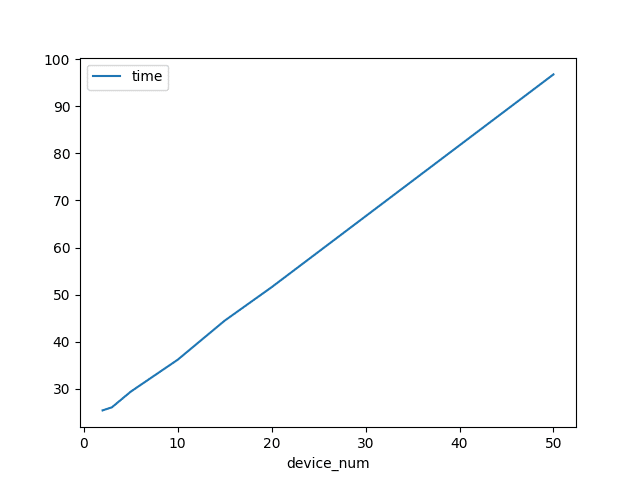
一方、処理時間は、通常学習時は、10.0054(sec)なのに対し、デバイス数が2のときも25.4315(sec)ほどかかってしまうので、デバイス数が少ないときも、通常学習時よりも2.5倍以上の処理時間を要してしまうようです。
グラフにすると、デバイス数にほぼ比例して、処理時間が増加する傾向があるようです。
まとめ
以上の結果から、Federated Averagingの元論文通り、デバイス数が十分に小さいときは、通常の学習と遜色ない精度で連合学習を行うことができることが分かりました。また、学習時間については、デバイス数が少ないときも、通常学習に比べて処理時間が多くなる傾向があることが分かりました。連合学習は、近年のプライバシー・個人情報保護問題に対応して誕生した比較的新しい分野だといえます。本記事が皆様の連合学習の学習の助けになれば幸いです。
参考記事
SSII2022 [OS3-02] Federated Learningの基礎と応用
Communication-Efficient Learning of Deep Networks from Decentralized Data
無線設計の問題として見る 分散連合機械学習