
超解像OCRの実験記録① ~文字認識モデルの作成~

導入
はじめに
こんにちは、株式会社Rosso、AI部です。
最近弊社でOCRを求められることが多く、巷でもニーズが増えているのではないかと感じています。
またその中でも、遠くからの撮影やブレが発生する状況など、読み取りづらい文字画像に対するOCRも需要があり、そういった状況でも正しく読み取るための手段として、前処理に超解像を行う技術が注目されています。
よって今回は文字認識の学習および、文字列画像を読みやすくする超解像の学習を通して超解像OCRの実験を行いました。
この記事では、文字認識の学習について書き、次回の記事で超解像部分に踏み込んでいこうと思います。
超解像OCRの流れ
超解像OCRの主要な流れは、以下のように3段階になっています。
①撮影した画像を、文字列を検出する物体検出モデルに通す。
②文字検出された画像を超解像により高解像度に変換する。
③文字列画像を文字認識モデルに通し、予測した文字列を出力する。
今回、物体検出モデルは既に作成済みなので、文字認識モデル&文字の超解像モデルの作成を中心におこなってみました。

記事の趣旨
①この記事ではアルゴリズムや実装についてはそこまで詳しく触れず、あくまで実験したことをベースに書いています。基礎知識や使われるモデルについて詳しくみたい場合は他サイトを参考にしてみてください。
文字認識モデル ⇒ CRNN (論文はこちら)
文字の超解像モデル ⇒ TPGSR (論文はこちら)
文字認識
はじめに文字認識モデルについて簡単に説明します。
文字認識モデルとは、文字列が書かれた画像からその文字列を予測するモデルです。
元々文字認識は、画像の特徴量抽出をするフェーズと、そこから系列情報を読み取りテキストを出力するフェーズの二段階で構成されているものなどがありましたが、2015年に出たCRNNが出発点となり、画像の入力から文字列の出力までをend-to-endで学習・推論できるモデルが主流となりました。
文字認識にはTesseactやASTERなど新しいモデルもたくさん出ていますが、今回はこのCRNNを用いて学習してみることにしました。
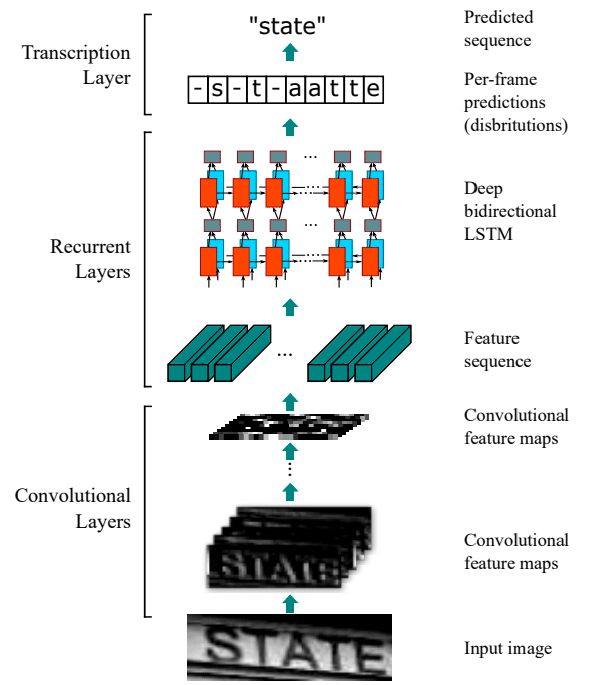
CRNN
CRNNは、まず画像からVGGNetを用いて特徴量を抽出、それを二層のBiLSTMに通す構造となっています。そしてBiLSTMからの出力は固定長となっていますが、可変長のテキストを予測する必要があるため、それを実現できるアルゴリズムが必要です。CRNNではこの層にCTC(Connectionist Temporal Classification) Lossを用いています。論文はこちら。
https://arxiv.org/abs/1507.05717
CTC Lossの詳しい説明は割愛しますが、AttentionなどのDeep Learningでテキストを予測する手法もある中、CTC Loss自体は学習が必要なパラメータは存在しないため、計算速度も比較的早いです。
ちなみにCTC Lossの理解はこのサイトが参考になりました。
文字列データセットの作成
学習のためにアノテーションされた物体検出後の文字列画像が欲しいので、データセットを探してみました。
既存のものを使えれば楽なのですが、調べてみても文字認識用の公開されたデータセットで日本語が含まれているものは非常に少ないです。

MJSynth: https://arxiv.org/pdf/1406.2227.pdf
SynthText: https://arxiv.org/pdf/1604.06646.pdf
IIIT5K-Words: https://www.di.ens.fr/willow/pdfscurrent/mishra12a.pdf
Street View Text: https://vision.cornell.edu/se3/wp-content/uploads/2014/09/wang_iccv2011.pdf
よってデータセットを自作してみることにしました。
既に作成された文字列検出の出力結果などを参考に、画像サイズや余白、傾きなどの範囲を決定し、文字列画像の作成コードをプログラムしていきます。
文字列の種類
数字、記号、英語、日本語がランダムに並んだ文字列
住所、名前、生年月日のフォーマットで作成された文字列
日本語の文
全て15文字以内で生成
フォント
明朝体、ゴシック体など、メジャーなフォント12種類
文字サイズ
低画質の画像にもなり得るため、初めから文字サイズが小さいものも用意。
背景
記事、広告、新聞、ディスプレイに映ったようなものなど、さまざまな雰囲気の画像を使用
その他
上下に別行を加える
文字検出時に上下に別の文字列が映る場合があるため時々追加。
縦横の線
枠や下線など、いろいろな文字データに含まれる。これも時々追加。
これらを適度な確率で選択して生成できるコードを作成し、画像を作り出しました。実際に作成された画像は以下のようなものになります。

学習のために、訓練データを10万枚、検証データを3万枚作成しました。
これらを用いて、画像から正解となるテキストを予測する文字認識モデルを作成していきます。
なお、実際の検出画像に含まれるような回転、ぼかし、ノイズなどの処理は文字認識モデルの前処理段階で施すことにしました。
CRNNの学習
作成した画像データを用いてCRNNに学習させてみます。以下に学習条件などを紹介。
データ拡張
アスペクト比の変更、回転
ガウシアンノイズやごま塩ノイズ
画像サイズを1/2に縮小して戻すことで低解像度化
などの変換を確率的に選択し、以下のようなさまざまな劣化のかかった画像を作成しました。

学習環境
文字の種類は日本語、英数記号など合わせて4129文字を用意
画像サイズ: 32×320
高さに合わせてアスペクト比を維持したままResizeし、右側の最後の1列(32×1)を横幅320になるまで行方向に繰り返す。

グレースケールに変換
バッチサイズ: 32
学習率: 1
Optimizer: Adam
これで学習してみました。
ColabのV100で精度が収束するまで2日弱かかりました。
Validationの精度
完全一致に対する精度は、検証用のデータセットで86%でした。
大文字小文字の判定ミス、濁点・半濁点のミス、複雑な漢字の読み取りミスなどはありましたが、簡単な文字列はほとんど読み取れていました。
実際に撮影した画像を通してみる
学習に用いた画像はアルゴリズムにより生成したものだったので、実際に撮影した画像で精度が出るか試してみます。
色々なドメインから画像を撮影し、既存の物体検出モデルに通して矩形の文字列画像を生成させました。文字列画像500枚ほどのテスト用データセットを作成し、評価を行いました。
結果
上記で作成したテストデータでは、完全一致精度が37%ほどでした。
読みやすい条件としては、サイズが大きく、ぼやけも少なく、背景色と文字色のコントラストが大きいことが挙げられました。

難しかったものは以下のような画像です。
フォントが違ったり、斜体や太字があるだけでもほとんど読み取れない。
データセットに入れていないフォントだと読めなくなりました。

大文字小文字、似ている字の間違い
隣の字の大きさなどはあまり考慮できていないようです。

重複ミス
これはCTC Lossに由来するミスであると考えられます。

劣化が強い画像
高さが15pixel以内かつぼやけなどが存在する画像は難易度が高め。

改善
いくつか改善策を実施し、実際の画像に対して効果を検証しました。特に効果があったものは以下のものです。
フォントの種類、斜体のデータセットを増やす。
汎用的なモデルを作るには斜体やフォントは多めに加えておく必要がありました。
画像の特徴量抽出器をVGGNetからResNetに変更。
STN (Spatial Transformer Networks)をCRNNの前に付け加える。
簡単に言うと、入力画像から空間的補正のためのパラメータを予測し、歪みを修正するネットワーク。

https://arxiv.org/abs/1506.02025
既存のデータセットを加える。
TextZoomや上記で紹介したデータセットを加えてファインチューニングしました。実際に撮影された画像を使うことでかなり精度が良くなりました。

https://arxiv.org/abs/2005.03341
逆に効果が薄かったものは以下。
画像の特徴量抽出器をVGGNetからEfficientNetに。
自分の環境ではResNetの方が精度が高かったです。
予測器をCTC LossからAttentionに変更。
学習はうまく進みますが、実画像にはあまり良い精度を示さなかったです。学習に工夫が足りなかったかもしれませんが、CTC Lossで満足いく結果が出たので今回はCTC Lossを使用することにしました。
改善後の結果
これらの工夫を施し、最終的には500枚の手元の実画像テストデータに対し 37% ⇒ 85% まで精度改善することができました。
精度改善の一番の要因は既存のデータセットを加えることでした。

精度は上がりましたが、それでもボケやジャギーが多かったり、解像度がかなり低い画像など、人間でも読み取りづらい文字に関して文字認識モデル自体を改善させるのは難しいように感じました。

こういった認識しづらい低解像度の画像に対して、有効的な前処理の一つとしてここ最近使われている技術が超解像になります。
超解像に関しても同じように実験をおこなったので、次の記事で紹介したいと思います。
まとめ
今回は文字認識モデルの作成実験をメインに行いました。個人的にかなり納得のいく精度が出せるようにはなりましたが、読み取りづらい文字もいくつか見受けられたので、超解像を駆使してさらに精度向上を目指したいところです。
読んでいただきありがとうございました。次の記事もお楽しみに。