
いきなりステーキの肉マイル上位ランカーになるにはいくら課金が必要か?

TL;DR
冪乗分布の性質を利用して、いきなりステーキの会員ランキングで上位帯に入るための肉マイル数と、その達成のための課金額を推定した。約8万円の課金で上位5%、約24万円の課金で上位1%の上位帯に入れることがわかった。
はじめに
先々月に咳が長引くタイプの軽い風邪をひいていたのだが[1]、ふとしたきっかけで「風邪にヒレステーキが効く」という風説を目にし、いきなりステーキのヒレステーキを初めて頂いた。ヒレステーキは低脂質で胃腸への負担が少ない割に栄養価が高いので、体調をよくするのに打ってつけとのことらしい。確かに食後の胃の負担感がなく、柔らかくて食べやすい。一般的にヒレステーキは高級食材として知られるが、いきなりステーキのカットヒレステーキ [2] は意外とコスパがよい。

以前からなんとなく存在は知っていたが、いきなりステーキには肉マイルというポイントシステムがある。アプリをいれて実際に肉マイルを貯めてみると、全会員の中での順位が表示されるというゲーム性のある仕組みがあることがわかった。食べた量に応じて特典ランクが上がるような仕組みはよくあるが、ランキング形式で競えるのは他ではあまり見かけない。また、現在のポイント計算は支払い金額に基づくが、以前は食べたグラム数で計算されていたため、単位がg (グラム) である点もおもしろい。
ゆる筋トレ勢としてはタンパク質補給としてもうってつけであること、通いまくってみたらRTA的にどこまで順位を上げられるのか試したくなり、いきなりステーキ通いを始めるに至った。
さて、1ヶ月ほど通って上位10%以内(約148万人中の約14万位)には入ったのだが、上位10%帯に近づくにつれてかなり順位の伸びが悪くなっていっていることに気づいた。順位に対する必要肉マイル数は、おそらく指数関数的に増えている。順位と肉マイル数の回帰モデルを推定できれば、5%の上位帯、さらに1%の上位帯を目指す場合に、どれくらいの肉マイルが必要かを予測できるようになる。
本記事では簡易的にいきなりステーキの会員ランキングの順位とその達成に必要な肉マイル数を、冪乗分布関数へのフィッティングによりモデル化し、ランキング上位帯に食い込むために必要な肉マイル数、ひいては必要な課金額を推定する。
プロット可視化によるデータの理解
公式ホームページで公開されている上位300位のデータの可視化
公式ホームページにて、上位300位までの順位と肉マイル数が公開されている。

2024/12/13時点のデータを取得し、順位と肉マイル数をプロットした結果、次のグラフのようになった。

上位300位に関しては、データ分析としては出来過ぎなくらいの、かなり綺麗な冪乗分布に従っていそうだ。
ランキング下位帯のデータ収集と可視化
上位帯は全体の0.1%にも満たないサンプルのため、上位帯のみで回帰モデルを組んでも下位帯ではかなり誤差が乗ってしまう可能性がある。そこで、いきなりステーキに通う際に、都度ランキング順位と肉マイル数を記録し、ランキング下位帯のデータを収集した。会員数が増えるなど前提条件の変化をなるべく抑えるため、2024年11月12日から12月13日の約一ヶ月間で短期集中的に実施した。
順位と肉マイル数をプロットした結果、下図のようになった。

上位300位と同様に、下位帯でも冪乗分布に従っているように見える。
収集したデータ全体の可視化
上位300位のデータと筆者のデータを同じグラフ上にプロットすると、次の図のようになった。

データの見やすさのためにX軸を対数スケールにしている点に注意すべきだが、統合したデータであっても冪乗分布に従う曲線を引けそうである。回帰曲線を推定できれば、データを収集できていない空白の順位であっても肉マイル数を推定できるようになる。
会員ランキングの順位数と肉マイル数のモデル化
冪乗分布の推定にあたり、Pyhon関数で表現される以下の関数のパラメータを推定することにした。
def power_law(x, a, b, c):
return a * np.power(x, b) + cPythonライブラリの SciPyに含まれるcurve_fit関数を使うことで、収集したデータから冪乗分布のパラメータ a , b , c を推定した。
フィッティングの試行錯誤にあたり、データ数が上位帯に偏っていることに起因して、下位帯の誤差が大きくなってしまうという問題が発生した。データ分析や機械学習でありがちな「不均衡データ (Imbalanced Data)」問題である。今回は不均衡データへの対処方法で取られがちな「データ拡張 (Data Augumentation)」アプローチに基づいて、簡易的に下位帯のデータを水増しすることで対処した。具体的には、曲線がうまくフィッティングするよう、実験的に下位帯のデータを増やし、最終的には10000倍に複製した。
試行錯誤してフィッティングして回帰モデルを組んだ結果、下図の結果が得られた。
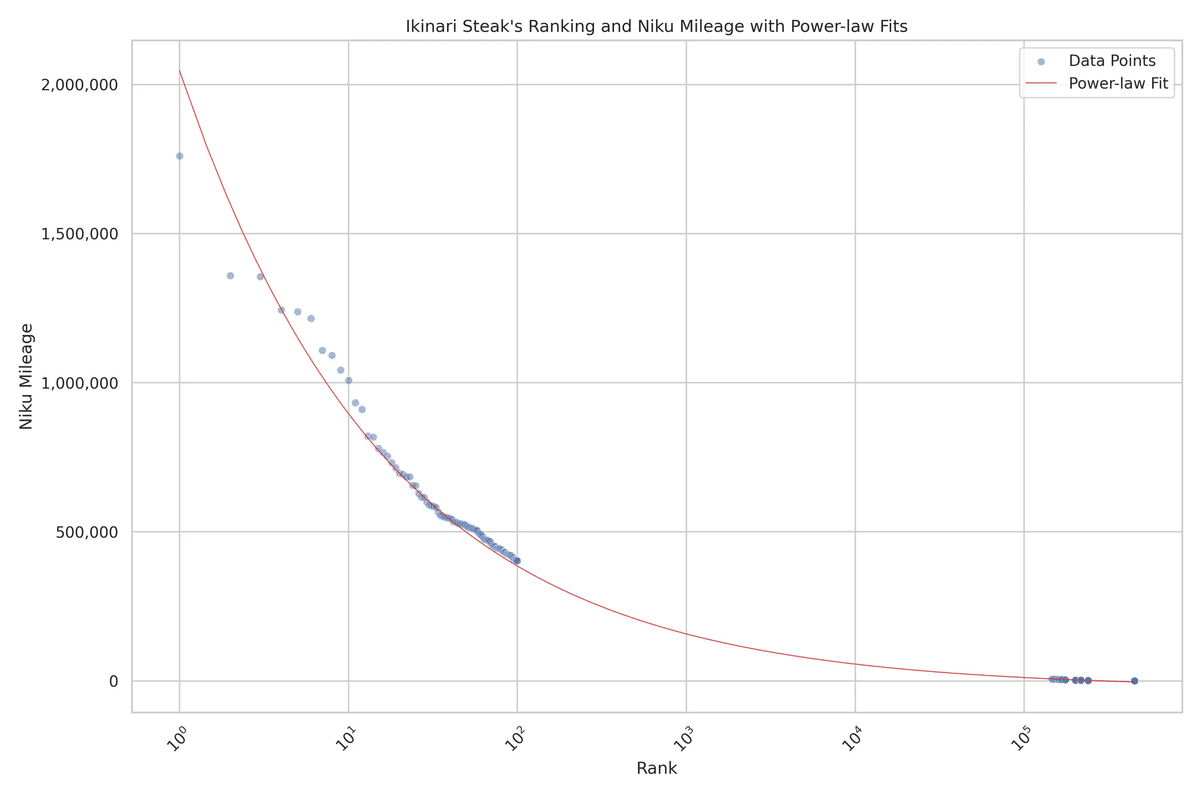
回帰モデルによる予測と実際のデータを300位、146314位の誤差を計測したところ、それぞれ3.13%、0.44%であり、簡易的なフィッティングにしてはよくできていそうなことがわかった。
ランキング上位帯に食い込むために必要な肉マイル数の推定
計算の簡単のために会員数を140万人とし、70000位 (上位5%) と14000位 (上位1%) の時の必要マイル数を推定した。


上記の結果から、5%、1%のランキング上位帯に入るために必要な肉マイル数はそれぞれ 16164g、47352g と推定された。これは現在の20g=100円の計算方法に照らし合わせると、それぞれ約8万円、24万円の課金が必要だということになる。ただし、この推定は今後、他の会員の肉マイル数が増えていくことを考慮していないため、一気に課金しない限り、目標順位を達成するための課金額は増えそうだ。
おわりに
公開されているランキングデータ(いわゆる「オープンデータ」)と、自分の足(腹?)を使って集めたデータを使って、自身の目標達成のための現実的な予測をすることができた。現状のペースで通えば遅くとも半年以内には上位5%に食い込めそうである。参考までに、読者の中に今回予測した14000位、70000位付近のデータを持っている方がいたら、ぜひコメントで教えてほしい。
[1] 医者にはかかっており、コロナもインフルも陰性は出ている
[2] 店舗限定なせいか、ウェブ上のメニューにはない。塩、胡椒、特製スパイス、ワサビでいただくのが至高