神テーブル分割ガイド

※SQLServer 2012 11.0.5058.0 のみ確認済みです。
対象読者
今時あまりないと思いますが以下のような困りごとを抱えている方。
・SQLがどうにも遅くて困っている。
・なんならタイムアウトまで発生することも。
・INDEX作れない。"分からない"でなくてvarchar(max)だからムリ、とか。
・SQLを直しても改善されない。
要するにテーブル構造が根本的な原因になっているのをどうにかしたい方。
神テーブルとは
正規化されておらず、1テーブルに100カラム以上定義されているような超巨大テーブルのこと。
神テーブルの問題点
バグ
100カラム以上なんて、性質や発生タイミングが違うデータをごちゃ混ぜにしている証。整合性を取れずに破綻するもの想像に難くない。
→でも今回は対象外。
パフォーマンス
稼働から数年経ってレコード数が増えてきたときにSELECTでタイムアウトになるような致命的な障害になることが多い。
カラムが多すぎてINDEXを作れない。
改善策
理想
正規化するのがベスト。間違いない。
現実
既に何年も稼働しているしアプリ側のコード量も肥大化しているし正規化してCRUD全部直してデータ移行なんてリスクも工数も膨大で(ヾノ・∀・`)ムリムリ
っていう手詰まり感のある状況で、少なからず改善効果が得られて、かつ現実的な手段はないかと考えたのが今回の対策方法です。
その方法はというと、1つの神テーブルを複数の子テーブルに分割し、全てをINNER JOINしたVIEWを作る!!です。
分割の動機
・分割したそれぞれのテーブルにINDEXを作れる。
- カラムが減っているのでINDEXを作りやすい。
- VIEWへのSELECTで各テーブルのINDEXが働く。
・SELECT文を直さなくて済む。
- VIEWをテーブルとほぼ同じ扱いで操作できるので修正不要。
・単純分割なので単純データ移行が可能。
神テーブルに劣る点
・INSERT、UPDATE、DELETEの修正は避けられない。
※VIEWをUPDATEできるケースもある。
・主キーでのSELECTは少し遅くなる。= JOIN分のコストは当然増える。
・デッドロックに注意が必要。
・同じ主キーを複数テーブルに持たせるのでデータサイズが増える。
使用上の注意
-INSERTは必ず分割した全テーブルに対して行うこと。
- INNER JOINなのでINSERTしていないテーブルがあると拾えなくなる。
- 例え主キー以外の全カラムがNULLでも必ずINSERTする。
- DELETEもゴミデータを残す意味はないので全テーブル消す。
- UPDATEは対象を絞り込むためにJOINが必要になる場合も。
手順
1. 正規化のことは完全に忘れる。
2. 分割したテーブルを作る。
- 1テーブルあたり5~10カラムを目安に分割する。
- もとのテーブルの主キーを各テーブルに持たせる。
- 可能な限り更新タイミングが同じカラムでまとめる。
- NOT NULL制約なども全部もとのテーブルと同じまま引き継ぐ。
3. 分割したテーブルにデータをINSERTする。
INSERT INTO [分割後テーブル] SELECT [分割後カラムs] FROM [分割前テーブル];4. もとのテーブルをリネームして退避する。
5. 分割したテーブル全てを主キーでINNER JOINしたVIEWを作る。
- VIEWの名前は分割前のテーブル名にする。
実例
過去に実際に降臨された神を例に、分割の具体的手順と効果を見てみます。(テーブル名、列名は多少マスクします。)
その神テーブルがこちら

長っ!!その数なんと205列!!!これだけ列がありvarchar(max)まであると、もうまともにINDEXが作れません。
これをどう分割していくかというと、(以下、4テーブルのみ抜粋します)

このように、列名や実際の用途をもとにデータのまとまりを判断し、分割していきます。この時に必要なINDEXも作ってしまうのが良いと思います。
次は分割したテーブルにデータを移していきます。
INSERT INTO t_god_base SELECT UniqueIndex, UniqueBlock ,RevisionCnt ,IsDel ,UniqueCode ,TitleName ,RelationIndex FROM t_god;
INSERT INTO t_god_ord SELECT UniqueIndex, UniqueBlock ,OrdDate ,OrdNo ,OrdComment1 ,OrdComment2 ,OrdParts ,OrdHeight ,OrdWeight ,OrdSickName ,OrdFree1 ,OrdFree2 FROM t_god;
INSERT INTO t_god_cause SELECT UniqueIndex, UniqueBlock ,CauseOrderNo ,CauseInst ,CauseInstName ,CauseSect ,CauseSectName ,CauseUser ,CauseUserName ,CauseMail ,CauseTelNo FROM t_god;
INSERT INTO t_god_rely SELECT UniqueIndex, UniqueBlock ,RelyOrderNo ,RelyInst ,RelyInstName ,RelySect ,RelySectName ,RelyUser ,RelyUserName FROM t_god;最終的に23テーブルに分割し、レコード数は約800万件ありましたので、トータルの所要時間が約1時間かかりました。
次はもとのテーブルをリネームします。(SQLServer)
EXEC sp_rename 't_god', 'escaped_t_god';この構文はDBの製品ごとに違います。例えばMySqlならばこうです。
RENAME TABLE tbl_name TO new_tbl_name;
レガシーな人が好みそうなのでリネームしていますがドロップしてしまって構いません。全ての工程をトラブルなく終えることができたらドロップしましょう。容量の圧迫も無視できません。
次にVIEWを作ります。
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE VIEW [dbo].[t_god] AS
SELECT
dbo.t_god_base.UniqueIndex,
dbo.t_god_base.UniqueBlock,
RevisionCnt,
IsDel,
UniqueCode,
TitleName,
RelationIndex,
OrdDate,
OrdNo,
OrdComment1,
OrdComment2,
OrdParts,
OrdHeight,
OrdWeight,
OrdSickName,
OrdFree1,
OrdFree2,
CauseOrderNo,
CauseInst,
CauseInstName,
CauseSect,
CauseSectName,
CauseUser,
CauseUserName,
CauseMail,
CauseTelNo,
RelyOrderNo,
RelyInst,
RelyInstName,
RelySect,
RelySectName,
RelyUser,
RelyUserName
FROM
dbo.t_god_base
INNER JOIN
dbo.t_god_ord
ON dbo.t_god_base.UniqueIndex = dbo.t_god_ord.UniqueIndex
AND dbo.t_god_base.UniqueBlock = dbo.t_god_ord.UniqueBlock
INNER JOIN
dbo.t_god_cause
ON dbo.t_god_base.UniqueIndex = dbo.t_god_cause.UniqueIndex
AND dbo.t_god_base.UniqueBlock = dbo.t_god_cause.UniqueBlock
INNER JOIN
dbo.t_god_rely
ON dbo.t_god_base.UniqueIndex = dbo.t_god_rely.UniqueIndex
AND dbo.t_god_base.UniqueBlock = dbo.t_god_rely.UniqueBlock
GO例として4テーブルのみ扱っていますが、実際には全てのテーブルをこの要領でJOINして1つのVIEWにします。
これで完了です。
雑に実測
効果が明らかなのであまり計測に意欲が湧かないのですが(ォィ
計測は3パターンで行いました。
1.もとのままのテーブル
2.VIEWにしたもの(23テーブル全部JOIN)
3.2にINDEXを追加したもの
SQLがこちら。
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
SELECT * FROM t_god T1 WHERE T1.CauseUser = 4;毎回キャッシュをクリアしてからSELECTを投げます。
総レコード数:8,447,787 件、抽出件数:4 件 のデータで試行しました。
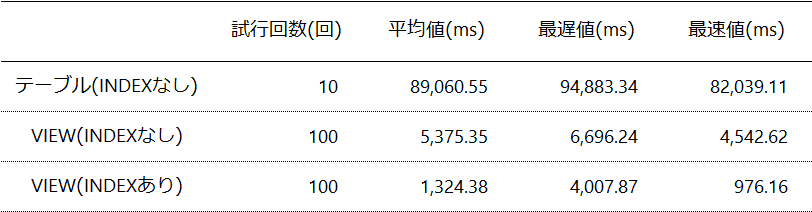
いやぁ……もとのままのテーブルではSELECT 1回につき1分半もかかるので、ちょっと試行回数を増やせませんでした。まぁ90秒だろうが80秒だろうが実用に堪えないことには変わりありませんのでご容赦ください。
ちなみにキャッシュクリアせずに実行した場合、VIEWならば
・INDEXなし:140ms~150ms
・INDEXあり:30ms~40ms
という程度におさまるようになりますので実運用を考えれば妥協できるラインだと思います。INDEXのメンテまでできなくても許容範囲と判断できるケースもありそうです。
※テーブルはキャッシュクリアしなくても1分前後かかります。
※というかその問題がこの案の発端なので。
まとめ
・とにかくテーブルを分割して小さくする。
・分割したら全部JOINしたVIEWにする。
・INDEX使えないSELECTの所要時間が90%くらい削減できる。
・INDEXのメンテまでできれば更に80%くらい削減できる。
・パフォーマンスをns、μs、msでなく"秒"で語る現場はヤバい。