
Google ColaboratoryでPythonを始める-9 統計関数とexcelデータの利用


Pandasの統計関数
今回使用するDataFrameは スライドのようになります。
最初に インポート メソッドでpandasモジュールを取り込み、dfにDataFrameとしてc1からc3列まで 辞書形式でデータを設定しています。
DataFrameは 右の図のように インデックス0行から 2行までのデータとなります。

Pandasで統計関数を使用する場合、左のような 関数が用意されています。
平均値はmean、標準偏差はstd、 最大値はmax、 最小値はmin、分散はvar、中央値はmedianとなります。
列ごとに これらの統計量を求める場合は括弧の中は省略してかまいません。
正式に列指定をする場合は axis=indexのように指定します。

行ごとにこれらの統計量を求める場合には、カッコの中は「axis=‘columns’」 と 文字列により指定します。

まとめて統計量を求めたい場合には データフレーム名.describe() と書きます。

「パーセンタイル値」とは、全体を100%として小さい方から数えて何番目になるのかを示す数値です。
65パーセンタイルであれば、最小値から数えて65%に位置する値を指します。
また第一四分位数は25パーセンタイル、中央値は50パーセンタイル、第三四分位数は75%パーセンタイルです。

ExcelデータをColaboratoryにアップロードする方法
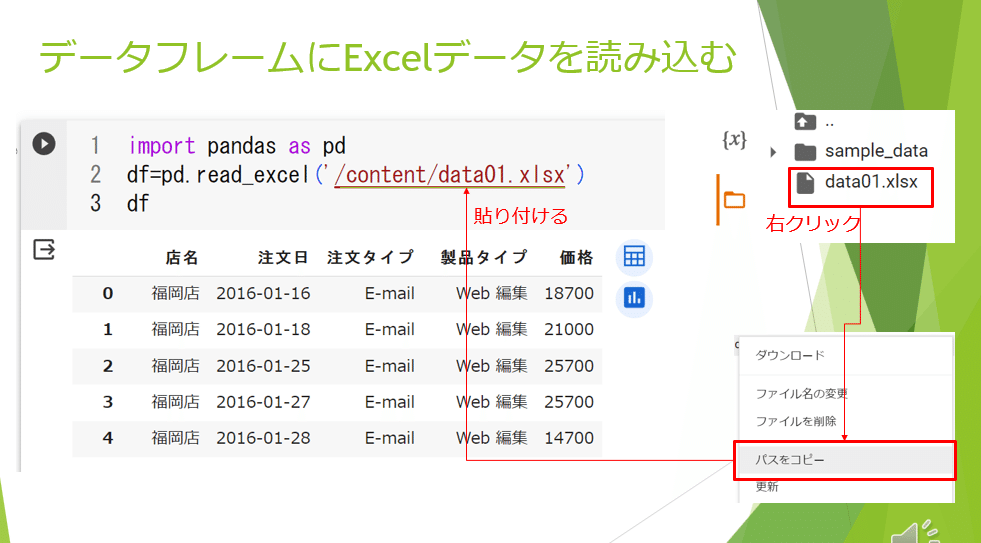
Google Colaboにアップロードされたエクセルデータを読み込むにはpandasの関数を使用します。
pt.read_excelとしてカッコの中に アップロードされたエクセルファイルの アドレスを文字列として書きます。
そして 変数df用意しその中に取り込んでいきます。
この時 アドレスを 正確に読み込むには アップロードされた excelファイルを右クリックし 「パスをコピー」でアドレスを取得し
read_excelの括弧の中に貼り付けます。このとき「’」を付けることに注意してください。
データフレームの表示方法と統計量の計算
DataFrameの表示行数を設定する方法について示します。
pd.set_optionの中に’display.max_rows’ カンマ の後に表示行数を設定します。
この例では8を設定していますので はじめの四行と終わりの四行が表示されています。
ここで 十以上の数を設定しても 合計十行以上に表示することはできません。

こちらは エクセルより読み込まれたDataframeをdescribe関数を使用して表示した例です。
このとき先程の行数設定で 少ない行数を設定した場合には全体が表示されないことがありますので注意してください。

ランダムサンプリング
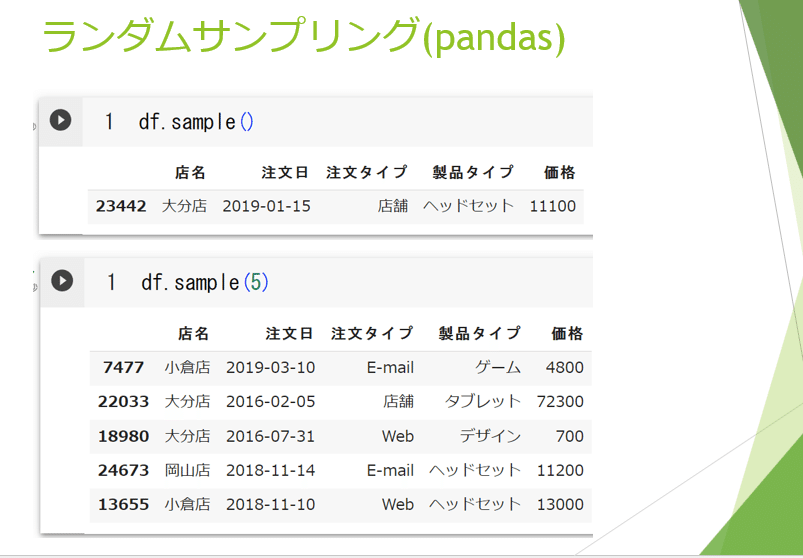
こちらはランダムサンプリングの方法を示しています。
df.sampleの後に何も入れないと一行のみのサンプリングとなります。
この括弧の中に行数を指定すると その行数に対応した データが無作為抽出されます。
今回はPandasの統計関数、excelデータの取り込み、DataFrameの表示方法、ランダムサンプリングについて解説しました。
次回は条件を設定したデータ抽出についてお送りします。
ご視聴ありがとうございました。