
AIが進歩したらUIはなくなるのか?

これはdesigning plus nine Advent Calendar 11日目の記事です。
こんにちは。ritarと申します。
今年はAI会話デバイスの年でしたね!
年初に出たRabbit R1を皮切りに、Humane AI Pin, Open Interpreter O1, さらにRay-Ban Meta Glassesを筆頭とするAIと会話しながら操作できるメガネなど、様々なデバイスが発売されました。

これらの端末は通常のタッチパネルやキーボードを持たず、全ての操作をAIとの会話を通して行うことになっています。
これを見ていると、将来はすべての作業をチャットや会話によって完了させられるようになるので、いつも使っているボタンやメニューなどの画面上のUI(GUI、グラフィカルユーザーインターフェイス)は不要になるのでは?と思えてきます。

星新一の有名なショートショートでも、日常のコミュニケーションをすべて会話型AIが肩代わりしてくれる未来が描かれていますね。
「こんにちは」 と、ゼーム氏は、口のなかで小さくつぶやいた。すると、つづいて肩の上のインコがはっきりした口調でしゃべりはじめた。 「おいそがしいところを、突然おじゃまして、申し訳ございません。お許しいただきたいと思います」このインコはロボットなのだ。なかには精巧な電子装置と、発声器と、スピーカーをそなえている。
でもコミュニケーションに限らず、そのうち全てのタスクは話すだけでAIがすべて代わりにやってくれるようになるし、情報もただ話すだけで目の前に出てくるようになるので、チャット以外のUIは全ていらなくなり、日常が会話型インターフェイスのみで構成されるようになるのではないかと思えます。
でも本当でしょうか。本当に会話するだけで何もかも済むようになるのでしょうか?
「全てが会話型にはならず、GUIも残り続ける」と言っている他の記事も確かにあるのですが、いずれも「AI時代への過渡期には残る」とか「文字入力が面倒だから残る」などといった表面的な説明に終始している印象です。もし視線や脳波で意図を入力してAIに伝えられるようになったら、最終的にはすべて会話型インターフェイスに置き換わるのでは……?
この記事では、すべてが会話するだけで済むようにはならないという仮説、そしてそれが上記の理由よりもっと根本的な、GUIの性質に起因するということをお話しします。しばしお付き合いください!
GUIは教育システム
早速結論なのですが、すべてを会話型インターフェイスに置き換えることが難しい一番の理由は、GUIが教育システムだからです。
ここで「教育システム」とは、ユーザーに新しい道具の仕組みを教えてくれるものという意味です。我々は、新しいツール・ソフトウェアを学習するとき「とりあえず触ってみる」という挙動を取ります。表示されたUIに、気軽に、試しにいろいろ触ってみることで、そのシステムが何のためのものか・何ができるのかを無意識のうちに把握しています。
そもそもGUIは、その起源からすでにコンピュータという得体の知れない道具の仕組みを、何も知らないユーザーに伝えることを目的としたものでした。
そのため黎明期には、そもそもパソコンに全く馴染みのないユーザーにどうにか概念を伝えようと、画面の中の世界を一生懸命現実世界のモノに似せたりしていました。


これらは紛れもなく、ユーザーへの教育です。
最近はユーザーも習熟してきているので、上記のような現実物体への比喩(メタファ)による説明はなりをひそめていますが、各アプリの中では、何も知らないユーザーに使い方を伝えなければならないという苦労は変わっていません。
そのためUIデザイナーは趣向を凝らして、オンボーディングと呼ばれるサービス紹介・チュートリアル画面を作っています。
↑各サービスのオンボーディングがまとまっている素晴らしい記事です。

ただ、こうしたメタファやオンボーディングフローは、あくまで事前知識を補うためのものです。
実際にユーザーが新しいツールを学習するときに一番大切なのは、間違いなくユーザー自身によるUI内の自由な探索でしょう。上述のnoteでも、「ユーザーの自主的な行動・探検」の重要さは繰り返し強調されています。
Spotifyを入れたら、とりあえずUIに触ってみる。それによって「音楽を流せる」「キューというものがある」「音楽はプレイリストにまとめられる」「それを共有できる」など、そのサービスの仕組み(情報モデル)を徐々に学んでいきます。
AIとの会話で、我々は何ができるようになっているのか
視覚的に情報モデルを伝えるGUIが発展する一方、AIと話すことでコンピュータを操作しよう・デジタルタスクを遂行しようという発想も非常に古くからありました。1960年代のELIZAに始まり、Siri, Alexa, そしてChatGPTと、着々と進化してきた系譜があります。
その中でも、多くの人の生活に馴染んだ最初の会話型インターフェイスがAlexaでした。自分も家でお世話になっています。
ただここで思い返してほしいのですが、Alexaを使い始めて初めてできるようになったことはあるでしょうか?
音楽をかけることも、電気をつけることも、メッセージを送ることも、すべて普通のスマホでもできることをAlexaにお願いしているだけです。
これはAlexaが特別なわけではなく、最近流行りのHumaneやRabbit含め、今出ているどの会話型インターフェイスも同じです。スマホで我々がすでにできる・知っていることを、AIにお願いしている。「このデバイスを使い始めて新しくできるようになったこと」がほとんどありません。
チャット型のAIはGUIと違って、それ単体では新しい概念・ツールをユーザーに学習させるための教育システムになりきれていないと感じます。
GUIは積み木遊び
これは、子どもへの教育の仕組みになぞらえることができます。
チャット型AIを通して新しいことを学ぶのは、教科書を読んでみたり先生に質問したりするのに近いといえます。
一方、GUIではユーザー自身が自由にソフトウェアを探索して実験できる。これは、積み木で自由に遊ぶことで重力や摩擦の仕組みを理解したり、学校の実験で豆電球をつけてみて電気の振る舞いを学ぶようなものです。
現実世界でもソフトウェアでも、世界の仕組みを自分で本当に「体得」するには、自ら実験したり触ってみたり、課題に取り組んでみなければなりません。
会話のみによって新しい概念を体得するのには、困難を伴います。
例えばSpotifyを知らない人がいたとして、AIとの会話のみを通してSpotifyを使えるようになるでしょうか?

Spotifyは一見シンプルな音楽再生サービスに見えますが、使いこなすには以下のような独自概念を学習する必要があります。
プレイリストの概念
追加できる、並び替えできる、同じ曲を何度も追加できる、名前をつけられる
URLを発行して共有できる
フレンドと共同編集できる
キューの概念
追加できる、並び替えできる
「次に再生」という仕組みがあり、曲はその下側に順番に追加されていく
再生デバイスの概念
複数デバイスで同時には再生できないが、その代わり別のデバイスでの再生状況をリモコンとして制御できる
近くにいる友だちを検出し、Jamを開始できる
……などなど。これらは、GUIにおいてはオンボーディング・文言・何よりユーザーの自由な探索によって自然に学習されます。しかし、実際のUIに触れることなく、会話のみを通してこれらを正しく理解しようと思うと至難の業です。
ユーザーイリュージョン
GUIで新しい概念を体得できるのは、GUIを触るユーザーが「実際にシステムに触れている」感覚を持てるからです。そのような性質を表すユーザーイリュージョンという言葉があります。
ソフトウェアというのは、実際にはメモリ内にある0と1の羅列です。しかしユーザーは、自分に見えているこのGUIこそが、システムそのものだと感じます。裏側でどれだけ複雑な0と1の処理がされていようと、GUIが正しくその結果を表示してくれている限り、ユーザーがそれ以上のことを知る必要はありません。
ユーザーインターフェイスが最重要のものと見なされているのは、素人にとっても、プロにとっても、目のまえにある知覚できるものが、その人にとってのコンピュータである、という理由からだ。われわれゼロックス社パロ・アルト研究所の所員は、これを “ユーザーイリュージョン” と呼んでいた。
ユーザーイリュージョンがあることで、ユーザーはそのアプリに「実際に触って」試すことができます。一方AIとの会話を通した操作では、どこまでいっても「他人に触ってもらっている」体験にしかなりません。それは、言葉という曖昧なものを通して指示しているからです。言葉を通すとそれは必ず「他人」になり、自分で触るという感覚ではなくなってしまいます。
(※注)
一方、曖昧な言葉ではなく確実なプログラミング言語を使っているときには、この問題は起きません。自分もプログラミングをしているときには「実際に」システムを触っている感覚になります。
エンジニアの方なら、AIとの会話のみでgitを完璧に使えるようになれるかを想像していただくとこの記事の趣旨がわかりやすいかもしれません。誰だって無理だと思います!実際にシステムを触ってみることこそが、教育として最大の効果を持っています。
GUIによる情報モデル + AIによるショートカット
ここまで「AIとの会話だけでは新しい概念を学習するのが難しいから、GUIはなくならないのではないか」という話をしてきました。では我々が今後使うデジタルサービスは、どんな操作体系になるのでしょうか?
自分が一つの解だと思っているのが、「情報モデルを提供するGUI + ショートカットのためのAI」というコンボです。
いくつか例をお見せします。

例えば最近リリースされたkapa.aiは、開発者向けドキュメントにAIチャットボットを統合できるサービスです。
画像からも分かる通り、あくまで通常の記事が後ろに表示されていて、「このサイトが何か」「どんなことができるのか」については、普通のヘッダーやナビゲーションで全体像を把握することができます。その上で、わからない事項があった場合にはAIに聞くことで探すのを助けてくれる。GUIが基盤となる情報モデルを提供し、そのショートカットとしてAIがある状態です。
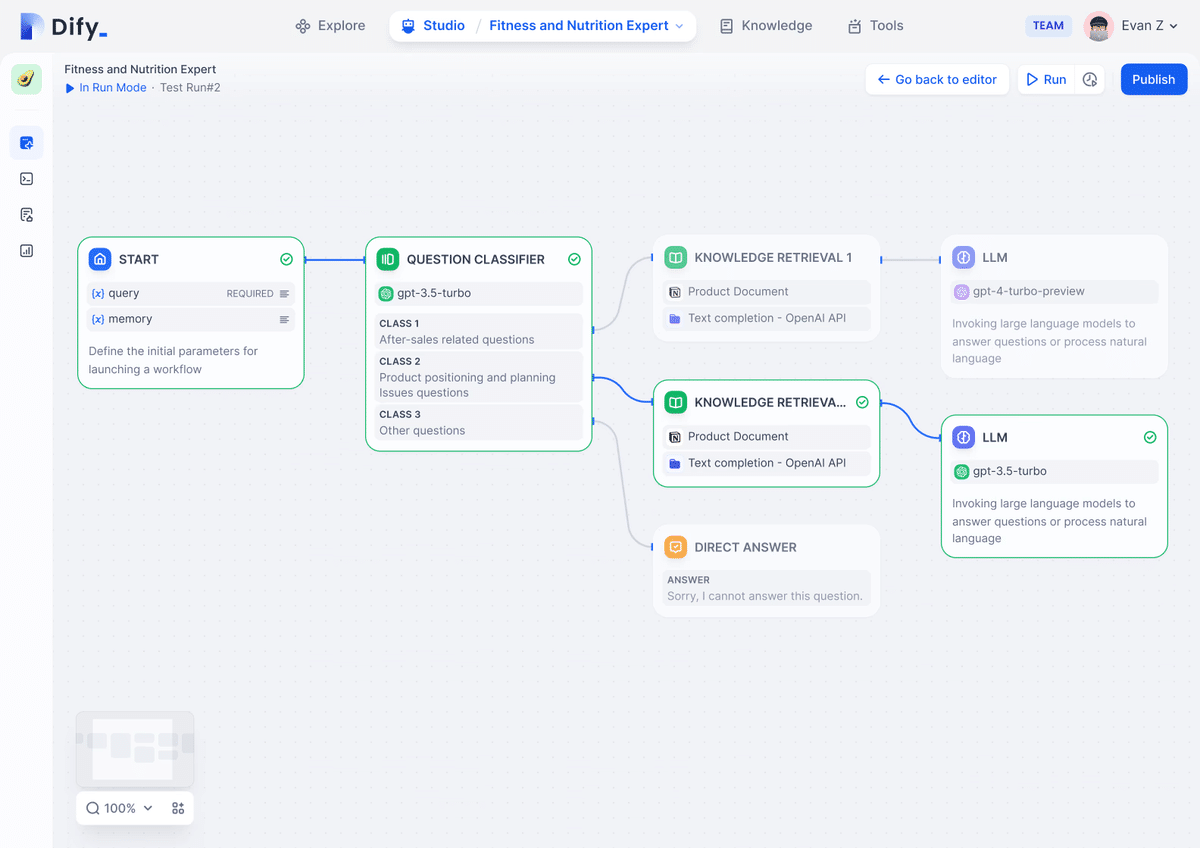
最近話題のDifyは、AIを使ったタスク自動化ツールです。これも、「タスク自動化のワークフロー作成」というGUIとしての基盤がある上で、その中にAIブロックを組み入れることで複雑な作業を肩代わりさせられるという構造になっています。

リリースされたばかりのApple Intelligenceも、テキストボックスというGUI基盤がありつつ、その中で書く・推敲するのをショートカットするためのAIです。
同様にGitHub Copilotも、コードエディタというGUIの基盤の上で、コードを書いたりファイル操作をするのをショートカットしてくれるAIです。
また手前味噌にはなりますが、先日Celboというデータ解析ツールをリリースしました。
【βリリースのお知らせ】
— ritar (@rtr_dnd) November 4, 2024
データ解析のための、Jupyter + Figmaのようなツールを友人と作ってます!
・Pythonをフローチャートのようにブラウザ内で実行
・AIと一緒に書けるから文法暗記いらず
・解析プロセスが視覚的に残る
Google Colab/RStudioに疲弊してるリサーチャー・開発者集まれ!!(続く) pic.twitter.com/d07KwiJBfD
Celboを見せると、AIが勝手にデータ解析をしてくれるツールだと受け取られることが多いのですが、実際には先ほどの考えを踏まえたものとして作っています。
つまり、体験価値の芯は「データ解析のプロセスをフローチャート的に見られる」というGUIの基盤にあります。その上で、各ブロックにコードを書く作業をAIによってショートカットさせられる、という仕組みです。
これらの例のように、情報モデルはあくまでGUIで表現することで、ユーザーにそのサービスの概念を教育する。その上で、いちいち煩雑にボタンを押したり複雑な文章を書いたりしなくていいようなショートカット用AIを導入する、というパターンがこれからも増えていくと考えています。
一方HumaneやRabbitにはGUI部分がなく、それ単体でユーザーに情報モデルの学習を促せないデバイスです。だからあくまでスマホで各サービスの情報モデルを学習した人が、ショートカットのために使うためのもの、と捉えることができます。
AIが置き換えられる範囲
ここまで、会話だけでは複雑な情報モデルの学習をさせられないから、会話型AIとGUIが共存するのではないかという話をしてきました。でもそうでない分野に関しては、GUIが消えていく可能性は十分ありそうです。
例1:ECサイト
例えば「1万円以下の赤いスニーカーをおすすめ順に表示する」というタスクには、UIを実際に触らないと学習できない情報モデルが一つもありません。これは普通に生きていれば想像がつくことです。
こういうことはわざわざGUIによって学習する必要がないため、会話型インターフェイスに置き換えられるかもしれません。
ただし同じECサイトでも「出品者にお礼を送る」や「価格交渉をする」など、他人が絡む行為やそのサイト特有の制度が入ってくると、会話のみで伝えるのは難しくなってきそうです。
例2:スマートホーム
他に生きていれば当たり前に思いつくタスクといえばスマートホーム系があります。「電気をつけて」には複雑な概念は一切登場しません。
しかしこちらも、「ルーティン」や「ショートカット」など自動化に関わる概念や、各デバイスへのアクセス権に関する概念を導入した途端に、説明や学習が必要になりそうです。実際、現在のAlexaやGoogle Homeでもこのあたりはアプリに任せられていますよね。
アクセス権や共同編集など他人が絡んでくるサービスでは、自分・AI・別ユーザーの三者間で情報モデルや考え方を共有しないといけなくなるので、必然的にサービス側の考え方をユーザーに教育していく必要が生じ、GUIの必要性が高まります。
そう考えてみると、最近「ChatGPTで何もかもできるじゃん」となっているのは、上記のように当たり前の概念しか使っておらず、自動化やアクセス権に関する複雑な概念が登場しないタスクの範囲内だけです。そこから外れると、GUIによる教育が必要になってきます。
もちろんそういうタスクは身の周りにたくさん登場します!なので会話型AIはすごい技術なのですが、それだけでスマホの役割が全て代替されるようなことにはならなさそうです。
もう一つ申し添えておきたいのは、学習によって一度AIとの間に共通言語ができてしまえば、結構なことを任せられるはずということです。Spotifyも、キューやプレイリストの仕組みを理解している今なら、何のためらいもなく会話で指示できます。
会話型AIは、ユーザーが新しいことをできるようになるためのものではなく、ユーザーが原理的にはすでに可能なことを楽にするためのものです。ここまで情報モデルの話をしてくると、この言葉の意味も違って聞こえるかもしれません。
おわりに
ここまで長々と、GUIと会話型AIの共存についてお話ししてきました。積み残した問いをいくつか書いておきます。
新しい情報モデルの学習プロセスすらもAIとの会話が担うようになる未来はあるのか?
「Airbnbというのを使ってみたいんだけどどうすればいい?」「Twitterというのを使ってみたいんだけどどうすればいい?」から可能なオンボーディングがあるのか?
もしかしたら、GUIをその場で生成できるAIが、個人に合わせた学習用GUIを動的に作ってくれる、などの可能性はあるかもしれません。
新しいツール・仕組みの学習にGUIが必要ということだったが、デジタルサービスが飽和した結果、新しく学習すること自体がなくなる未来はあるのか?
これは難しいですが、歴史的にはどんどん新しいツール・新しいモデルが登場しているし、個人的には当分はそういう未来は来ないと予想しています。そう考える理由は人間のやりたいことはどんどん複雑になっていくのに、人間の認知資源は有限だからなのですが、もうだいぶこの記事も長くなってきているのでこれ以上はまた次回に……
10年後、もし本当にGUIが全部なくなって、日常の全てを会話型インターフェイスが担っていたら、ぜひ笑いながら読み返してください!タイムカプセルとして未来から振り返るのが、今から楽しみです。
万能のAIが全てを終わらせるかと思いきや、逆に再構築が進むインターフェイスの世界。これからも楽しく温かく見守っていこうと思います。
いいなと思ったら応援しよう!
