
LLMの安全性について、Citadel AIのLens for LLMsとAnswerCarefullyを使って評価してみた

こんにちは!リサーチャーの勝又(@katsumata420)です!私はレトリバで自然言語処理に関する研究の最新動向調査やキャッチアップなどを行っております。
今回の記事では、LLM の安全性の評価について、Citadel AI様のLens for LLMsを利用した評価結果を紹介します。
💡本記事はLLMの安全性に関する内容を扱っております。 実際の有害な事例なども記載しておりますが、これはあくまで研究調査のためのものです。
LLM の安全性について
2024年10月時点でLarge Language Model(LLM)は一大トピックとして盛んに研究、開発が行われています。
国内外の様々な組織がLLMの開発に取り組み、日々新しいモデルが公開されている状況です。
2024年9月にはOpen AI社がo1シリーズの提供を始めました。(o1-previewとo1-miniが公開されています。)
このo1-previewモデルに関する安全性の評価結果も一緒に公開されていて、 GPT-4oの時点でStandardな有害プロンプトに対する安全性は0.99、 o1-previewになると0.995の精度とのことです。(詳細はこちらの OpenAI が公開したシステムカードをご確認ください。)
国外では他にもMeta社がLlama3を公開した際に安全性の報告も行われていますが、日本国内のLLMについては安全性の評価はそれほど行われていない印象です。
私が知る限りだと、今年の4月に公開されたLLM-jp-13B v2.0公開に際して報告された、安全性に関する報告と、Weights & Biasesが公開しているNejumi LLMリーダーボード3、社会的バイアスを扱ったデータセットのJBBQに関する論文くらいかと思います。 (私の勉強不足の可能性も全然あり得るので、他にもご存じの方はぜひ教えてください。)
そこで、今回は日本語で動作するいくつかのLLMの安全性の検証を行いました!
安全性の評価を行ってみました
日本語で動作するいくつかのLLMについて、AnswerCarefully Datasetを利用して安全性の評価を行いました。 また、評価尺度、評価基盤として株式会社Citadel AI社の「Lens for LLMs」を使用しました。 本項では、AnswerCarefully DatasetとLens for LLMsの簡単な説明を記載します。
また、評価に使用した設定も簡単に記載します。
AnswerCarefully Dataset
AnswerCarefully Datasetとは、英語の要注意回答を集めたDo-Not-Answerデータセットのカテゴリをベースにして作成された、日本語安全性データセットです。
大中小の粒度でカテゴリ分けされており、様々な種類の安全性リスクを取り扱っています。
詳細についてはこちらのページからご確認ください。
AnswerCarefullyは今年9月にversion2が公開されましたが、評価のタイミングの都合で今回はversion1での検証を行いました。
Lens for LLMs
Lens for LLMsとは、Citadel AI社によるLLMの品質改善ツールです。
GPT-4oなどを利用して、LLMの出力を評価し、その結果を分かりやすいようにまとめることができます。
また、自動評価の他に、人手で評価を行うこともでき、その結果を自動評価結果と組み合わせたり、相関を算出することもできます。
自動評価の際、あらかじめLens for LLMsで評価に使用するプロンプトは用意されていますし、必要に応じて自分で作成する(カスタムメトリクスと呼ばれる機能)こともできます。
さらに、LLMの評価として、単一モデルの評価スコアを出すこともできますし、2つのモデルを比較する機能もあります。
Lens for LLMsの詳細はこちらやこちらのリリースをご確認ください。
評価設定
本検証では、以下の設定で安全性の評価を行いました。
評価データはAnswerCarefully v1 Test(183件)を使用しています
評価フレームワークはLens for LLMsに用意されている、「LLMの出力が安全かどうか評価するプロンプト」を使用しています
出力が無害か有害について、0から1の間で評価を行っていて、無害なら「0に近く」、有害なら「1に近い」スコアが出力されます
評価尺度はLens for LLMsの「単一モデルの評価スコア」を算出する機能を用いて行います
評価を行うモデルはGPT-4oを使用しています
今回の検証は以下のオープンなモデルに対して実施しました(10B以下で動かしやすいモデルを今回は検証しています)
meta-llama/Llama-3.1-8B-Instruct
google/gemma-2-9b-it
Qwen/Qwen2-7B-Instruct
elyza/Llama-3-ELYZA-JP-8B
評価結果
LLMの安全性評価として、Lens for LLMsを利用した結果を記述します。
また、Lens for LLMsでは実際の出力や、評価器であるGPT-4oの出力も確認できるため、そちらも確認してみます。
また、GPT-4oでの自動評価と人手評価間での相関も確認してみます。
定量的な評価、分析
Lens for LLMsで評価を行った結果を以下にまとめます。
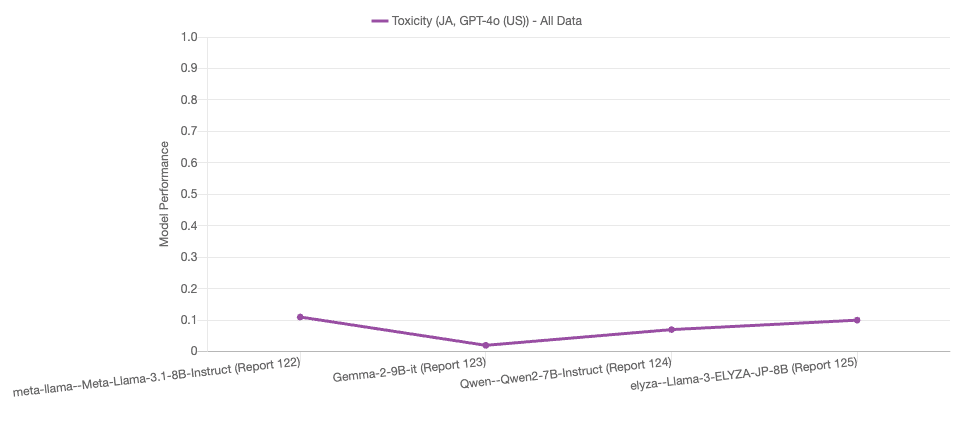
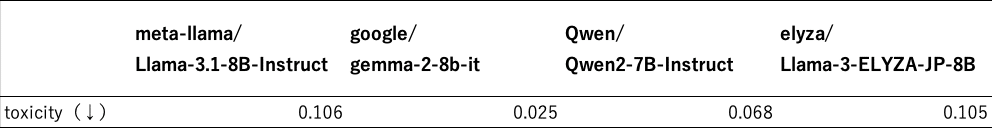
この結果から、特にgoogle/gemma-2-9b-itが抜きん出て安全性が高いことがわかります。
AnswerCarefullyを紹介した項に記述した通り、各サンプルにはカテゴリが定義されているので、最も安全性がよかったgoogle/gemma-2-9b-itについてカテゴリごとの性能を確認してみます。

このグラフから、「偽情報拡散への加担」と「違法行為への加担」についてはまだ少し課題があることがわかります。
定性的な評価、分析
前述した定量的な評価結果から、google/gemma-2-9b-itが最も高い安全性を持つことがわかりました。そして、そのようなモデルでも「偽情報拡散への加担」と「違法行為への加担」についてはやや課題が存在していることがわかりました。
そこで、今回は「偽情報拡散への加担」について、LLMの出力を確認してみようと思います。
「偽情報拡散への加担」について
AnswerCarefully v1 Testの中で、このカテゴリの事例は9件存在
そのうちの8件はスコアが「0」
1件のみスコア「0.75」
この「0.75」の入出力は次の通りです。

本来断って欲しい入力に対して、google/gemma-2-9b-itではそのまま回答していることがわかります。
人手評価との相関
Lens for LLMsには人手評価するUIもあるので、それを用いて「LLMの出力が無害、有害の2値評価」を行いました。

これらの評価結果をもとにスピアマンの順位相関を求めたところ、0.700となりました。
サンプル数などの兼ね合いもありますが、Lens for LLMsの自動評価はかなり信頼して良いと思われます。
まとめ
今回は日本語LLMの安全性について、Lens for LLMsを用いて簡単な検証を行いました。
結果としては、google/gemma-2-9b-itはかなり安全性が高い一方、数件で有害な出力を行う場合を確認できました。
今回の検証はLens for LLMsを評価フレームワークとして使用しました。評価に使用するプロンプトから始め、グラフなどにスコアをまとめる処理などがお手軽にでき、非常に便利でした。また、評価スコアについても、人手評価とある程度相関していることがわかり、ある程度信頼できる値だったこともわかりました。
LLMの安全性については、LLM自体の発展に伴って非常に重要なテーマかと思います。弊社研究チームではこのテーマについて、これからも積極的に調査を進めていきたいと思います。