
DatastreamでサクッとCloudSQLのデータをBigQueryにレプリケーションしてみた

どうも、サーバエンジニアでデータエンジニアリングチームのうすぎぬです。この記事はREALITY Advent Calendar 2024の13日目の記事です。

Google CloudのDatastreamを利用して、CloudSQL for MySQLからBigQueryへのデータのレプリケーションを簡単に試してみました。本記事では、その手順や注意点について詳しくご紹介します。
背景
REALITYでは、主に CloudSQL for MySQL と Cloud Spanner をデータストアとして利用しています。Cloud Spanner に関しては、Spanner Data Boost を活用することで、データアナリストが分析目的で Spanner 内のデータを参照できます。一方、CloudSQL for MySQL に格納されたデータについては、サービス運用に支障をきたすことなくデータアナリストが容易にアクセスする手段が、現状存在していません。
CloudSQL for MySQL には、主要なユーザーデータが保存されています。このデータを直接分析に活用できるようになれば、データアナリストが記述する SQL はよりシンプルになり、分析結果の信頼性向上にも期待できます。
そこで今回、CloudSQL for MySQL のデータを BigQuery へレプリケートすることで、上記の課題を解決できるかどうかを検証してみることにしました。
Datastreamとは
Datastreamは、Google Cloudが提供するリアルタイムデータストリーミングサービスです。データベースやアプリケーションから変更データをキャプチャし、BigQueryなどのターゲットにリアルタイムで送信できます。特に、CloudSQLにおける変更データキャプチャ(CDC)の設定が容易な点に注目し、REALITYの分析基盤への適用可能性を探るため、簡単な検証を行いました。
なお、DatastreamはBigQueryやCloudSQL以外にも多くのサービスとの接続・レプリケーションをサポートしています。詳細は公式ドキュメントをご確認ください。
ストリームを作成する
今回は、検証用にCloudSQL for MySQLインスタンスを用意しました。まずは公式ドキュメントの通りの前準備をしましょう。特に、検証するインスタンスにdatastream用のuserを作成するのを忘れずに。
CREATE USER 'datastream'@'%' IDENTIFIED BY 'YOUR_PASSWORD';
GRANT REPLICATION SLAVE, SELECT, REPLICATION CLIENT ON *.* TO 'datastream'@'%';
FLUSH PRIVILEGES;CloudSQL for MySQLインスタンスの準備が整いましたら、DatastreamのWebコンソールから「ストリームの作成」を選択し、目的のストリームを作成していきましょう。

ここからは次のステップでストリームを作成できます。
始める
ソースの定義とテスト
ソースの構成
宛先の定義
宛先の構成
確認と作成
1. 始める
まず、ストリームの名前を設定します。ここでは「datastream-cloudsql-to-bigquery」とします。ソースには「MySQL」、宛先には「BigQuery」を指定しましょう。暗号化は特段の理由がなければ、デフォルトの「Googleが管理する暗号鍵」を利用して問題ないでしょう。「Cloud KMS 鍵」については、詳細を公式ドキュメントでご確認ください。

2. ソースの定義とテスト
MySQL接続プロファイルを作成します。プロファイル名は「datastream-cloudsql」としました。CloudSQL for MySQLインスタンスのパブリックIPアドレスおよびポート番号、そして作成済みのMySQLユーザー情報を設定します。

続いて、通信暗号化のために「ソースCA証明書」「ソースのクライアント証明書」「ソースの秘密鍵」を用意しましょう。これらはCloudSQLのコンソールからクライアント証明書を作成しダウンロードできます。今回は分かりやすく「datastream」という名前で作成しました。
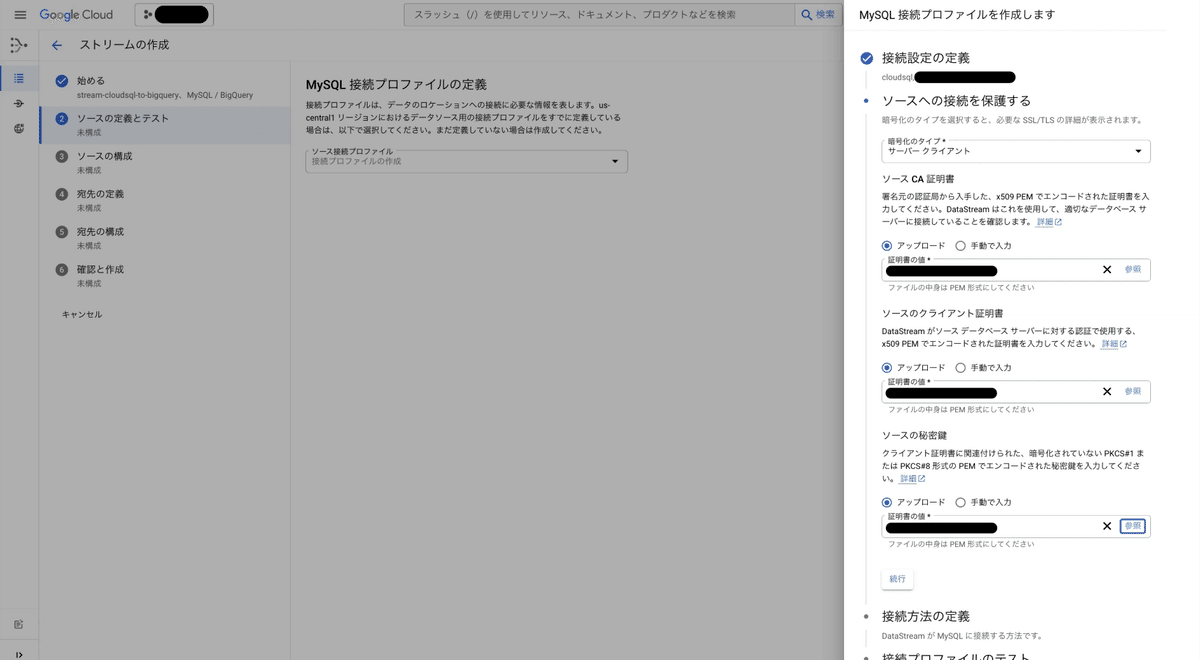

DatastreamからCloudSQL for MySQLへの接続方法として、「IP許可リスト」「フォワードSSHトンネル」「プライベート接続(VPCピアリング)」を選択可能です。今回は検証目的のため、最も手軽な「IP許可リスト」を選択します。本番利用時はセキュリティ面を考慮して適切な方式を選択してください。詳細は公式ドキュメントをご確認ください。

「IP許可リスト」を選ぶと5つのIPアドレスが表示されるため、これらをCloudSQL for MySQLインスタンスの「編集 > 接続」画面にある承認済みネットワークとして設定します。

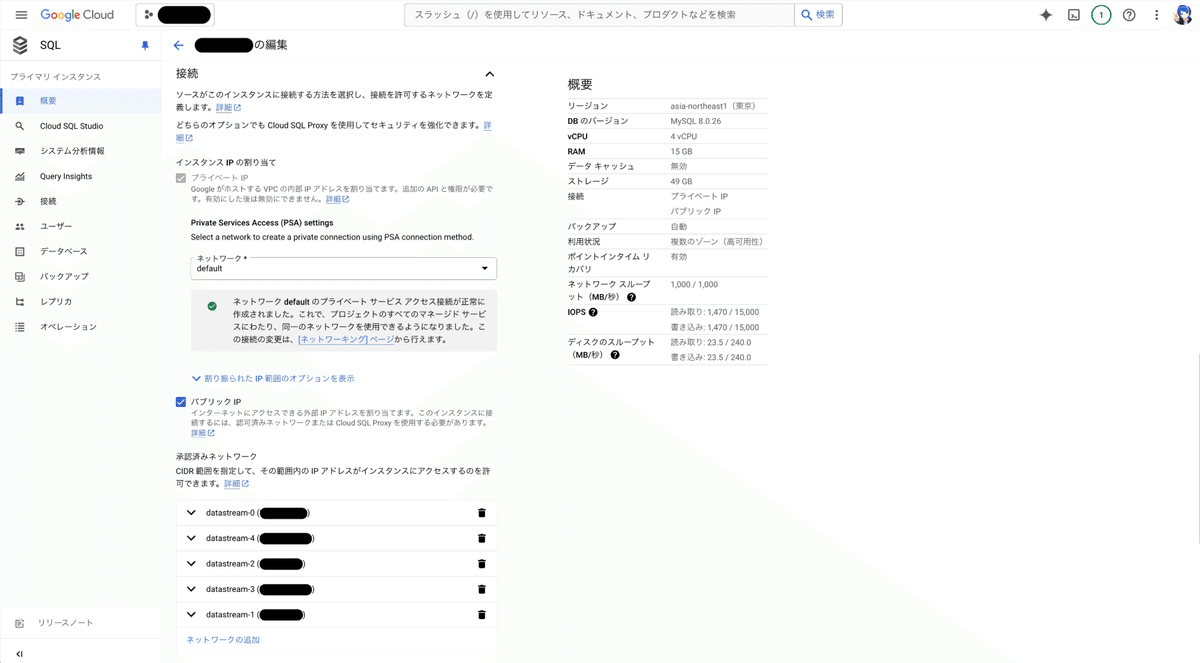
正しく設定できていれば、接続プロファイルのテストが成功します。

3. ソースの構成
BigQueryへレプリケーションする元データベースやテーブルを選択します。また、この段階でCDCメソッドを選択します。今回は「バイナリログの位置」を利用しました。現時点ではプレビュー機能のため見送りましたが、「GTIDベースのレプリケーション」も興味深い選択肢です。
バイナリログの位置
MySQLのバイナリログ(binlog)は、データベース内部での変更(INSERT、UPDATE、DELETEなど)を記録するログファイルです。バイナリログにはイベント単位で変更情報が格納され、各イベントには「Position」が割り当てられます。Datastreamはこの「Position(log_position)」を用いて、変更点を把握し取得します。
https://dev.mysql.com/doc/refman/8.0/ja/binary-log.html
GTIDベースのレプリケーション
GTID(Global Transaction ID)は、MySQL内の各トランザクションを一意に識別するIDで、mysql.gtid_executedテーブルに格納されます。GTIDを利用することで、レプリケーションの同期ポイントをGTIDで一元的に管理できるため、binlogファイル名や位置に依存せず、フェイルオーバーやリカバリ時にも高い信頼性で状態を復元できます。
https://dev.mysql.com/doc/refman/8.0/ja/replication-gtids-concepts.html

4. 宛先の定義
BigQuery接続プロファイルを作成します。プロファイル名は「datastream-bigquery」としました。特に難しい設定はありません。
5. 宛先の構成
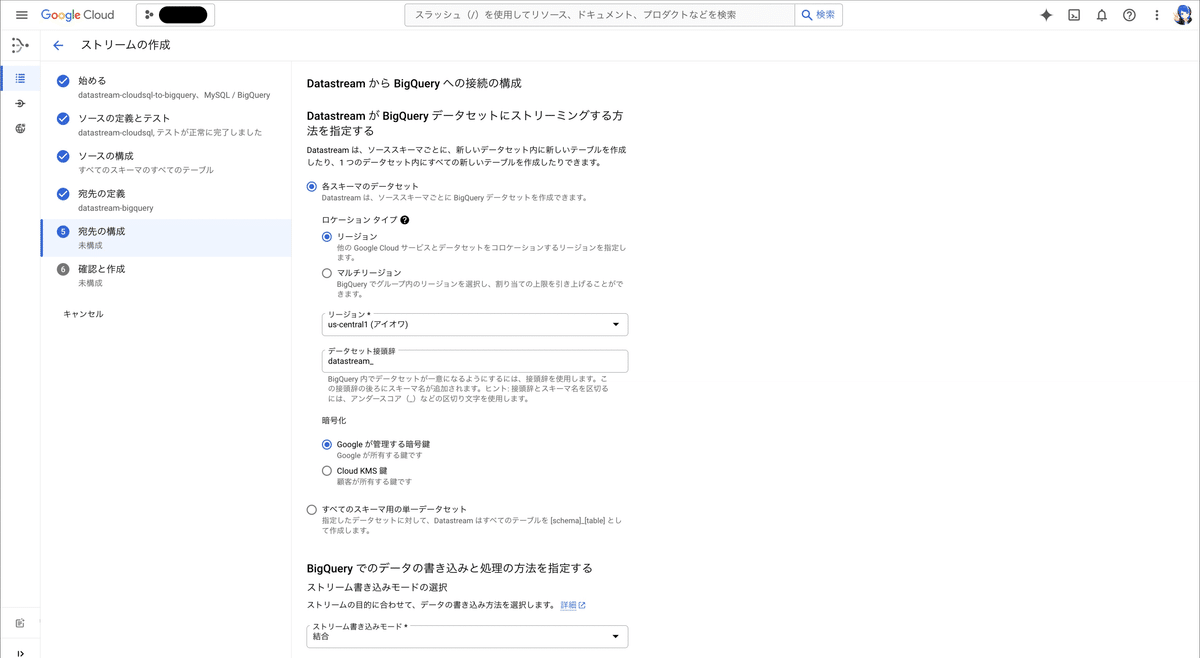
CloudSQL for MySQLから流し込むデータを格納するBigQueryデータセットを構成します。環境に合わせて設定してください。ストリーム開始後、データセットは自動生成され、その名前に「データセット接頭辞」が付与されます。ソース側で選択したMySQLのデータベース名と組み合わせて「{データセット接頭辞}{MySQLのデータベース名}」の形式でデータセットが作成されます。例えば、データセット接頭辞を「datastream_」、DB名を「example_db」とした場合、データセット名は「datastream_example_db」となります。
ストリーム書き込みモードとして「結合」または「追加のみ」を選択可能です。今回はMySQLのデータをそのまま同期したいので「結合」を選択しました。「結合」を選択すると、「データ未更新期間の上限指定」オプションを設定できます。データ更新頻度が高い場合、BigQueryでの処理コストが増すようなので、環境に合わせて適切な値を設定してください。詳細は公式ドキュメントをご覧ください。
6. 確認と作成
さて、設定は終了です。設定内容を確認し、検証に問題なければ、ストリームを実行しましょう!

レプリケーションを試してみる
ストリームを見ると「datastream-cloudsql-to-bigquery」が作成されていました。

接続プロファイルを確認すると、手順「2. ソースの定義とテスト」で作成した「datastream-cloudsql」と、「4. 宛先の定義」で作成した「datastream-bigquery」も確認できました。

ストリームの詳細画面にある「概要」タブを開くと、ステータスやデータの鮮度を確認できます。「データの鮮度」とは、送信元と送信先の間に生じている時間差を指すようです。モニタリングタブには次の説明がありました。
DataStream が送信元の新しいデータを最後に確認してから経過した時間として計算されます(新しいデータが検出されたかどうかは関係ありません)。
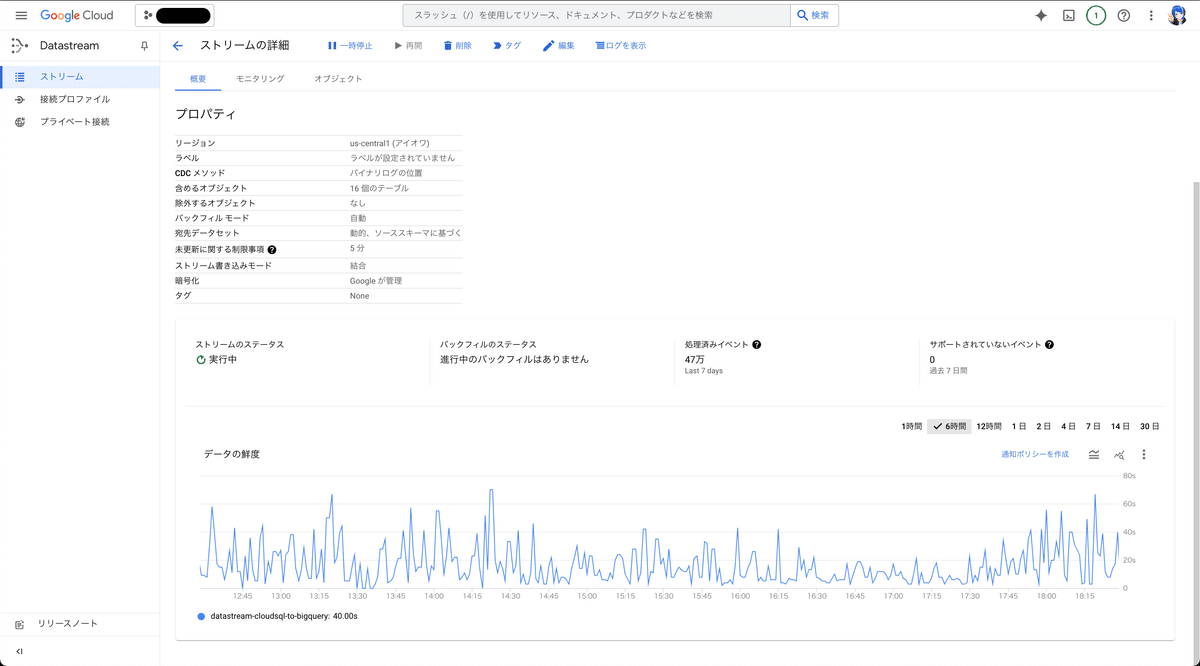
BigQuery側には、「5. 宛先の構成」で設定したデータセットが自動的に作成され、データセット内にはMySQL上のテーブルごとにテーブルが生成されています。ストリームの開始後、約10~20分ほど待つとデータが同期され始めました。

バックフィル処理による一時的なデータベース負荷の増加も確認できました。そのため、本番環境でストリームを開始する際は、サービス稼働状況やテーブルレコード数に配慮し、慎重に行うことをお勧めします。Query Insightsで状況を確認すると、指定したテーブルに対して全レコードをSELECTするSQLが実行されていることを確認できました。

今回簡易的に試した範囲では、MySQLのデータスキーマは概ねBigQuery側で互換性があるように見えました。主キー(PK)もBigQueryに引き継がれているようです。気になったのは、MySQLのtinyintがBigQueryではINTEGERになったり、すべてのカラムがNULLABLEとして作成されたりすることくらいでしょうか。全てのtypeを確認したわけでは無いので、ご利用の環境に合わせてご確認ください。
スキーマに関するその他の注意点や詳細については、公式ドキュメントを参照してください。
また、「テーブルの中央に列を追加する」操作時にデータ破損の可能性があるとの記述があったため、軽く検証してみました。BigQuery側では新たな列がテーブル末尾に追加されましたが、同期自体には問題はありませんでした。また、「列をドロップする」操作も試したところ、BigQuery側の列はドロップされず、ドロップ対象だった列にはNULLが格納されるようになりました。今回はテスト用のインスタンスでデータ変更が限定的だったため、問題が起こらなかった可能性もあります。

まとめ
今回は、Datastreamを利用してCloudSQL for MySQLからBigQueryへのリアルタイムでのデータのレプリケーションを簡易的に試してみました。Datastreamの設定はGUI上で直感的に行え、バックフィル後はMySQL側の変更データが自動的かつ継続的にBigQueryへ反映されることが確認できました。
スキーマ変化への対応や、実運用におけるセキュリティやパフォーマンス面での検討はまだ必要ですが、Datastreamは分析用データパイプライン構築の有力な選択肢になり得ると感じました。今後は、より複雑なユースケースやスキーマ変更を踏まえた検証を行い、実利用に向けた知見を深めていきたいと思います。