
esa.ioで記事とコメントをExport/Import

こんにちは、ラボ型開発チームのジョージです。
「esa.io」というチームの情報共有のために作られたサービスを使って、記事とコメントをExport/Importする方法を書いていきたいと思います。
背景
「esa.io」の記事を別アカウントへ移行したいという理由です。
(ポエム駆動開発にとても役立ちそうなesa.io、先行で使ってたアカウントの記事を楽に移動したい)
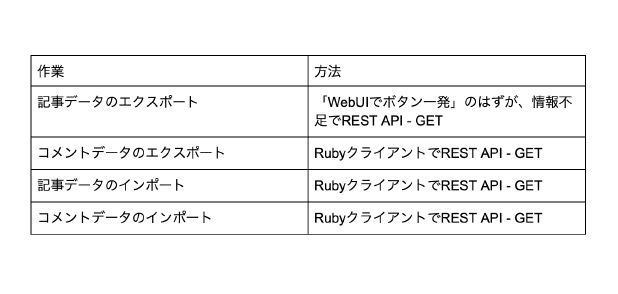
やらなきゃいけない事リスト
REST APIを使用する必要があります。
WebUIで準備してもらえたら嬉しいなぁ・・・と感じつつ。
そんなにニーズは無いのかなとも感じます。
準備

Ruby実行環境を作成します。
[Rubyのインストール]
https://www.rubylang.org/ja/documentation/installation/
じょーじは手っ取り早くUbuntu(Lubuntu)派なので、以下のコマンドでRubyやgemをインストールです。
sudo apt-get install ruby
sudo gem install bundler
sudo gem install esa
実装

仕様やライブラリ
・API仕様:API V1 - docs.esa.io
・REST APIクライアントライブラリ:GitHub - esaio/esa-ruby: esa API v1 client library, written in Ruby
今回使ったAPI
認証と認可 - docs.esa.io
今回、 OAuth は使いません。頻繁に使うツールでもないので、アクセストークンを発行して一時的に使います。
ソースコード
体調不良気味で作ってたので、整理されてなくてすみません。。
(もっと綺麗に作れると思いますが、力尽きました)
定数
ruby
module Auth
def self.token_from
'トークン'
end
def self.token_to
'トークン'
end
TEAM_FROM = 'from-domain'
TEAM_TO = 'to-domain'
end
REST APIのラッパー: Import
ruby
class Importer
def initialize(client)
@client = client
end
def article(post)
params = {
name: post['name'],
body_md: post['body_md'],
tags: post['tags'],
category: post['category'],
wip: post['wip'],
message: post['message'],
user: post['created_by']['screen_name'] || 'esa_bot'
}
response = @client.create_post(params)
p response.status
case response.status
when 201
return response.body
else
p response
end
end
def comment(post_number, body_md, user)
response = @client.create_comment(post_number, body_md: body_md, user: user)
p response.status
case response.status
when 201
return response.body
else
p response
end
end
end
REST APIのラッパー: Export
ruby
class Exporter
def initialize(client)
@client = client
end
def articles(page, per_page)
params = {
page: page,
per_page: per_page
}
response = @client.posts(params)
p response.status
case response.status
when 200
return response.body
else
p response.error
p response.message
end
end
def article
end
def comments(post_number, page, per_page)
params = {
page: page,
per_page: per_page
}
response = @client.comments(post_number, params)
p response.status
case response.status
when 200
return response.body
else
p response.error
p response.message
end
end
def comment(article_number)
response = @client.comments(article_number)
p response.status
case response.status
when 200
return response.body
end
end
end
コマンドライン用
※Mockのコードは省略しました。
ruby
require 'esa'
require 'json'
require './mocks'
class CLI
attr_accessor :exporter, :importer
def initialize(dry_run: true)
@dry_run = dry_run
end
def exporter
return @exporter if @exporter
if @dry_run
@exporter = MockExporter.new()
else
exporter_client = Esa::Client.new(
access_token: Auth::token_from,
current_team: Auth::TEAM_FROM
)
@exporter = Exporter.new(exporter_client)
end
end
def importer
return @importer if @importer
if @dry_run
@importer = MockImporter.new()
else
importer_client = Esa::Client.new(
access_token: Auth::token_to,
current_team: Auth::TEAM_TO
)
@importer = Importer.new(importer_client)
end
end
def setExporter(token, team)
exporter_client = Esa::Client.new(
access_token: token,
current_team: team
)
@exporter = Exporter.new(exporter_client)
end
def export_all(request, output_file_path, start_page, per_page, interval_sec, token, team)
setExporter token, team
index = start_page
begin
response = request.call(index, per_page)
p response
if response
File.open("#{index}_#{output_file_path}", "w", 0644) { |file| file.write(response.to_json) }
end
if response['next_page']
p '****************************'
p "waiting #{interval_sec}sec next [#{response['next_page']}] request"
p '****************************'
interval_sec.times { |sec|
print '.'
sleep sec
}
end
index += 1
end while response['next_page']
end
# 記事を全てエクスポート(esa.ioから抽出)
def export_article_all(output_file_path, start_page: 1, per_page: 50, interval_sec: 5, token: Auth::token_from, team: Auth::TEAM_FROM)
request = lambda { |i, pp| exporter.articles(i, pp) }
export_all(request, output_file_path, start_page, per_page, interval_sec, token, team)
end
# 記事のコメントを全てエクスポート(esa.ioから抽出)
def export_comment_all(output_file_path, from_article_file_path, start_page: 1, per_page: 50, interval_sec: 5, token: Auth::token_from, team: Auth::TEAM_FROM)
json_article = JSON.parse(File.read(from_article_file_path))
json_article['posts'].each { |post|
request = lambda { |i, pp| exporter.comments(post['number'], i, pp) }
each_output_file_path = "#{post['number']}_#{output_file_path}"
export_all(request, each_output_file_path, start_page, per_page, interval_sec, token, team)
}
end
# 記事を全てインポート(esa.ioへ入力)
def import_article_all(input_file_path, start: 1, limit: 1000, interval_sec: 1)
p input_file_path
return if !File.exist?(input_file_path)
# ファイルからesa.ioへ逐次インポート
json_data = JSON.parse(File.read(input_file_path))
filtered_data = json_data['posts'].select { |post| (post['number'] >= start && post['number'] < (limit + start)) }
sorted_data = filtered_data.sort { |a,b| a['number'] <=> b['number'] }
sorted_data.each { |post| p "#{post['name']}, #{post['created_by']}" }
sorted_data.each { |post|
result = importer.article(post)
if !result
p "Failed article_from_file #{file_path} name:#{post['name']} name:#{post['number']}"
break
end
sleep interval_sec
}
end
# コメントを記事へ全てインポート(esa.ioへ入力)
def import_comment_all(comments_file_paths, interval_sec: 3, post_file_path: './to_post_numbers_on_comments.json', user_map: [])
time = lambda { |s|
{
'Y' => s.gsub(/-.*/, ''),
'M' => s.gsub(/^.*-(.+-)/, '\1').gsub(/-.*/, ''),
'D' => s.gsub(/^.*-/, '').gsub(/T.*/, ''),
'h' => s.gsub(/.*T/, '').gsub(/:.*/, ''),
'm' => s.gsub(/.*T..:/, '').gsub(/:.*/, ''),
's' => s.gsub(/.*T..:..:/, '').gsub(/\+.*/, ''),
}
}
json_post_map = JSON.parse(File.read(post_file_path))
comments_file_paths.each { |comments_file_path|
json_comments = JSON.parse(File.read(comments_file_path))
# p json_comments
p comments_file_path
# コメントの投稿日時順で整列する
comments = json_comments['comments']
comments.sort! { |ca,cb|
a = time.call(ca['created_at'])
b = time.call(cb['created_at'])
Time.utc(a['Y'], a['M'], a['D'], a['h'], a['m'], a['s']) <=> Time.utc(b['Y'], b['M'], b['D'], b['h'], b['m'], b['s'])
}
# 対象記事の番号を得る
old_number = comments[0]['url'].gsub(/.*posts\//, '').gsub(/#.*/, '')
index = json_post_map.index { |map| map['old_number'] == old_number }
post_number = json_post_map[index]['number']
# esa.ioへ逐次インポート
comments.each { |comment|
print post_number
user_index = user_map.index { |user| user[comment['created_by']['screen_name']] }
user = (user_index != nil && user_index >= 0) ? user_map[user_index][comment['created_by']['screen_name']] : comment['created_by']['screen_name']
p user
result = importer.comment(post_number, comment['body_md'], user)
if !result
p "Failed import_comment_all number: #{post_number}"
break
end
sleep interval_sec
}
}
end
# コメントのpost_numberから記事のpost_numberを出力します
# 用途:記事エクスポート後、記事インポート後では記事の番号が変わってしまうため、
# 記事インポート用にコメントを結び付ける
def print_post_numbers(comment_file_paths, from_article_file_path, to_article_file_path, print_file_path: './post_numbers.json')
json_article_from = JSON.parse(File.read(from_article_file_path))
json_article_to = JSON.parse(File.read(to_article_file_path))
posts = []
comment_file_paths.each { |comment_file_path|
json_comment = JSON.parse(File.read(comment_file_path))
one_post = json_comment['comments'].map! { |comment|
post_number = comments[0]['url'].gsub(/.*posts\//, '').gsub(/#.*/, '')
target_article = json_article_from['posts'].select { |post|
post['number'].to_s == post_number.to_s
}
# print post_number
if target_article.size >= 1
# { post_number: post_number, name: target_article[0]['name'], category: target_article[0]['category'] }
{ number: post_number, full_name: target_article[0]['full_name'] }
end
}
posts.push(one_post) if one_post
# posts = posts.select { |post| post != nil }
p one_post
}
posts.flatten!
p posts
File.open(print_file_path, 'w', 0644) { |file|
file.write posts.to_json
}
end
def map_post_to_post(from_post_file_path, to_post_file_path, print_file_path: './to_post_numbers_on_comments.json' )
json_from = JSON.parse(File.read(from_post_file_path))
# json_from.each { |post| p "#{post['number']}: #{post['full_name']}" }
json_to = JSON.parse(File.read(to_post_file_path))
# json_to['posts'].each { |post| p "#{post['number']}: #{post['full_name']}" }
match = []
json_to['posts'].each { |post|
index = json_from.index { |from|
from['full_name'] == post['full_name']
}
if index
match.push({
old_number: json_from[index]['number'],
number: post['number'],
full_name: post['full_name']
})
end
}
# match.each { |post| p "#{post['number']}: #{post['full_name']}" }
File.open(print_file_path, 'w', 0644) { |file|
file.write match.to_json
}
end
end
使用コード
ruby
require './cli'
cli = CLI.new dry_run:false
cli.export_article_all('articles.json', per_page:100)
cli.export_comment_all('comments.json', '1_articles.json', interval_sec:1)
cli.export_article_all('articles_to.json', per_page:100, token: Auth::token_to, team: Auth::TEAM_TO)
cli.import_article_all('1_articles.json')
comments_file_paths = []
Dir.open('./') { |d|
begin
file_name = d.read
comments_file_paths.push(file_name) if (file_name && file_name.match(/1.*comments.json/))
end while file_name
}
# comments_file_paths.each { |path| p path }
cli.print_post_numbers(comments_file_paths, '1_articles.json', '1_articles_to.json')
cli.map_post_to_post('post_numbers.json', '1_articles_to.json')
user_map = [
{ 'from_user' => 'to_user' }
]
cli.import_comment_all(comments_file_paths, user_map: user_map, interval_sec: 0)
留意点
”REST APIでコメントを取得しても、メタデータは更新できない。”
⇒ コメントのPOST仕様
更に、記事につけたコメントを、記事と一緒に投稿は出来ず、
新規コメント として登録しないとダメみたいです。。
"コメントを一括取得するのは20件、1ページだけ"
ページネーションの仕様に合わせて client.comments() を呼び出すと、:post_number を指定する必要があるらしいです。
1発やるだけでリクエスト数上限にひっかかりそうです。。
"記事番号`post_number`は`1`から開始"
ですが、 per_page 単位で返す記事番号は連番とは限らないようです。
"Joinしてないユーザ名で記事投稿できない(`400`)"
Joinしてもらってから、記事投稿しましょう。後、 user を動的に変更してREST APIを呼び出す事を忘れずに。
API要求の注意点
> 現時点では、ユーザ毎に15分間に75リクエストまで受け付けます。
記事が多い場合は、一括インポートを複数回に分ける必要があります。
インポートスクリプトは記事やコメントを一括登録可能なように作るので、
テスト時は上限2個に制限しておくのが無難です。(制限に到達してしまうので・・。)
終わりに
結局スクリプト作成完了、記事とコメントの移行完了に数日要してしまいました。。
JavaScriptに慣れていると、Rubyのお作法に慣れるのが難しかったです。
(過去にRubyでスクリプト書いた事あったのですが、もう忘れてしまったため。)
あと、思っていたよりもRubyクライアントの仕様とAPI仕様書の差異があったり、思い込みがあったので時間がかかりました。
「esa.io」まだ社内では試用状況ですが、皆で使っていけるといいなと考えてます!
以上です。
◆───-- - - -
ラフアンドレディでの採用はこちら
↓ ↓ ↓
目黒オフィスでお待ちしています。

SESでの開発、受託での社内開発。ラフアンドレディでは、みんなのびのびと仕事をしています!エンジニアが長く幸せに活躍できる環境で、仲間と楽しく働いてみませんか?
◆───-- - - -