データマネジメントに関するコンセプト・データ編

次の図は、データマネジメントの概要を表したものです。
ここでは、データマネジメントに関わるデータ、データモデル、データアーキテクチャ、メタデータ、データ品質、データセキュリティ、デーtあ管理基盤について説明します。
データ
まず、データについて説明します。
データとは、人や物、事象に関する事実を表したものです。
例えば、注文すると、その事実が注文データになります。
また、鉄塔があると、その事実が鉄塔データになります。
なので、データは、実体を表したもので、データそのものに実体があるわけではありません。
なので、データ同士の関係を表すデータモデルをつくる場合、データが表す実体をモデル化することになります。
ドイツの哲学者、ライプニッツは、「本当に存在している」ものを、集合体と要素という観点から考えたとき、集合的に構成されたものは当然に、一次的に存在しているとは言えず、その構成要素から、その存在を受け取っているものと考えるほかないと、いうことは、ものを要素へと分割していけば、いつかは、「本当に存在している」ものでかつ「まったく要素を持たない厳密に単純な」ものへとたどり着くはずである、
とし、「まったく要素を持たない厳密に単純な」要素を実体(エンティティ)と考えました。
この場合、集合のほうを実体タイプ(エンティティタイプ)といいます。
しかし、データマネジメンチ知識体系(DMBOK)では、
「ジェーンは、従業員である」
といった場合、さきほどのライプニッツの定義だと、ジェーンがエンティティ、従業員がエンティティタイプになりますが、
「今日では、従業員をエンティティと考える方が一般的なので、集合をエンティティと考えることを推奨する」としています。
この場合、ジェーンは、エンティティインスタンスとなります。
ここでは、DMBOKに従って、集合、タイプのほうをエンティティ、要素、インスタンスの方をエンティティインスタンスとします。
データモデル
上述したように、データモデルは、エンティティ同士の関係を描いた静的モデルとして記述します。
「DXとデータマネジメント」の「変化に強い構造」でMDA(Model-Driven Architecture:モデル駆動アーキテクチャ)について説明しました。
MDAでは、システムを構築するとき、モデルを、次の3つのモデルを分けて考え、CIM→PIM→PSMという流れで設計することで、より堅牢なシステムをつくることができるとしています。
CIM(Computation Independent Model)
計算機処理に依存しないモデル。PIM(Platform Independent Model)
IT基盤に依存しないモデル。PSM(Platform Specific Model)
IT基盤に特化したモデル。
データモデルも、次のように、MDAの3つのレイヤで分けて記述することができます。
概念データモデル
ビジネスを実現するために必要なデータ(業務活動で発生する事実)の構造を明確にするデータモデルです。
CIMに該当します。
情報システム開発の要件定義でデータ要件を明確にするときドメインモデルを記述します。
ドメインモデルと概念データモデルは同義で、通常、UMLのクラス図を使って記述します。論理データモデル
システムの機能要件やデータの品質要件(一意性・一貫性・参照整合性など)を満たすデータの構造を明確にするデータモデルです。
PIMに該当します。
論理データモデルは、ER図を使って記述します。物理データモデル
システムの非機能要件(特に効率性)を満たし、IT基盤(データベース製品など)に適応したデータの構造を明確にするデータモデルです。
PSMに該当します。
物理データモデルもER図を使って記述します。
なので、データベース製品が変わったら物理データモデルは作り直す必要がありますが、論理データモデルは再利用することができます。
また、概念データモデルは、システムに依存しないモデルなので、システムの機能要件が変わり論理データモデルが変更されても、業務の仕組が変わらない限り不変です。
なお、データモデルを作成するときは、データモデリングスキーム(データモデルの表現形式)を決める必要があります。
データモデリングスキームによって、どのようなデータモデルを作成するか、その型が決まります。
代表的なデータモデリングスキームには以下があります。
リレーショナルスキーム
行と列によって構成された表形式のデータ集合を、互いに関連付けた関係モデルによって表す方法。
リレーショナルスキームで表したデータモデルをリレーショナルモデルといいます。
データ管理基盤としてリレーショナルデータベースを使う場合、リレーショナルモデルを作成します。ディメンショナルスキーム
データを、時系列の数値を持つ「ファクト」と分析軸となる「ディメンション」によって表す方法。
ファクトを中心としてディメンションを周辺に配置することから 「スタースキーム」とも呼ばれます。
ディメンショナルスキームで表したデータモデルをディメンショナルモデルといいます。
データ管理基盤として多次元(マルチディメンショナル)データベースを使う場合、ディメンショナルモデルを作成します。
多次元データベースは、通常、データウェアハウス(データの倉庫)で管理されます。
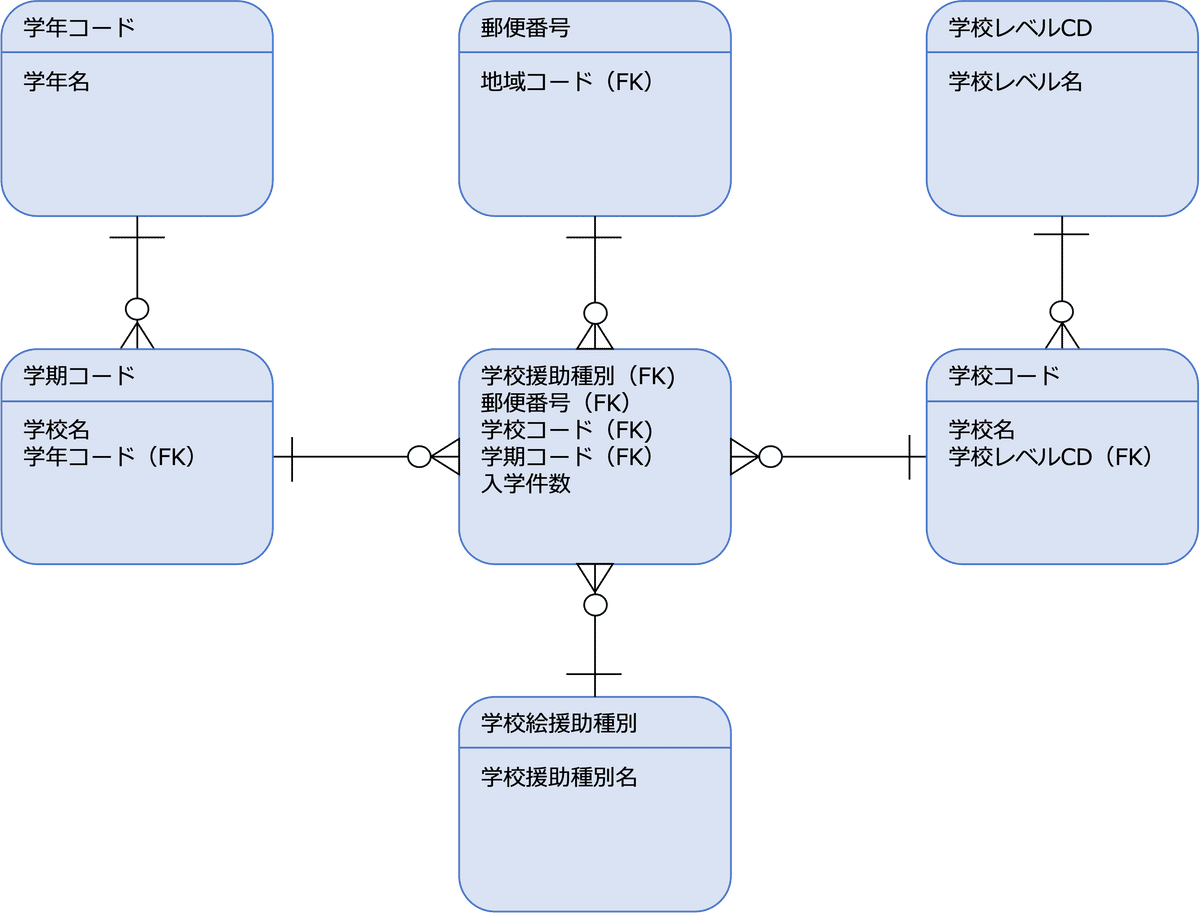
次の図は、学生が学校に入学申請することを表したリレーショナルモデル(概念データモデル)の例です。

次の図は、入学申請を地理、学校、学資支援、カレンダーという次元で分析するディメンショナルモデル(概念データモデル)の例です。

次の図は、スノーフレークモデル(正規化されたディメンショナルモデル)の論理データモデルの例です。
ここでは、リレーショナルモデルを使って各レベルのデータモデルについて説明します。
概念データモデル
下図は、受注と出荷の関連を表した概念データモデル(クラス図)です。

これを見ると次のことがわかります。
このビジネスでは、一つの注文の製品を複数に分けて出荷することがある(分納)
このビジネスでは、複数の注文をまとめて出荷することがある(一括納入)
これは、このビジネス固有の仕組を構成する実体の構造(上記CIM)を表していることを示しています。
詳細は、「【DMBOKで学ぶ】データモデリング」の「概念データモデリング」を参照してください。
論理データモデル
下図は、ER図で記述した論理データモデルです。

論理データモデルは、システムの機能要件やデータの品質要件(一意性・一貫性・参照整合性など)を満たすデータの構造を明確にします。
なので、画面にあるデータ項目や、システムの制御に必要なデータ項目がすべてエンティティに含まれている必要があります。
また、上記例の場合、論理的に、次のようなデータの生存制約が発生します。
エンティティのインスタンスを生成する時の制約
受注明細エンティティが受注エンティティに対して強く依存しているので、受注インスタンスを生成するとき、必ず受注明細インスタンスが1つ以上存在する必要がある(受注明細側が必須になっているため)
受注明細エンティティが受注エンティティに対して強く依存しているので、受注明細インスタンスを生成するときには、必ずそれに対応する受注インスタンスが存在する必要がある(受注側が必須になっているため)
受注明細エンティティと製品エンティティが非依存型リレーションシップになっているので、受注明細インスタンスを生成するときには、必ずそれに対応する製品インスタンスが存在する必要がある(製品側が必須になっているため)
受注明細エンティティと製品エンティティが非依存型リレーションシップになっているので、製品インスタンスを生成するとき、必ずしも受注明細インスタンスが1つ以上存在する必要はない(受注明細側が任意になっているため制約は発生しない)
店舗エンティティと受注エンティティが非依存型リレーションシップになっているので、受注インスタンスを生成するときには、必ずそれに対応する店舗インスタンスが存在する必要がある(店舗側が必須になっているため)
店舗エンティティと受注エンティティが非依存型リレーションシップになっているので、店舗インスタンスを生成するとき、必ずしも受注インスタンスが1つ以上存在する必要はない(受注が任意になっているため制約は発生しない)
エンティティのインスタンスを削除する時の制約
受注明細エンティティが受注エンティティに対して強く依存しているので、受注インスタンスを削除すると、それに対応する受注明細インスタンスはすべて削除される(受注側は必須になっているが、受注と受注明細の関係が依存型リレーションシップになっているため)
受注明細エンティティが受注エンティティに対して強く依存しているので、受注明細を削除するときには、そのインスタンスが対応する受注インスタンスの最後の明細であれば、受注インスタンスも削除される(受注明細側が必須になっているため)
受注明細エンティティと製品エンティティが非依存型リレーションシップになっているので、製品インスタンスを削除するとき、それに対応する受注明細インスタンスが存在している場合、製品インスタンスは削除できない(製品側が必須かつ、製品と受注明細の関係が非依存型リレーションシップになっているため)
受注明細エンティティと製品エンティティが非依存型リレーションシップになっているので、受注明細インスタンスを削除するとき、そのインスタンスが対応する製品インスタンスの最後の明細であっても、製品インスタンスを削除する必要はない(受注明細側が必任意になっているため制約は発生しない)
店舗エンティティと受注エンティティが非依存型リレーションシップになっているので、店舗インスタンスを削除するとき、それに対応する受注インスタンスが存在している場合、店舗インスタンスは削除できない(店舗側が必須かつ、店舗と受注の関係が非依存型リレーションシップになっているため)
店舗エンティティと受注エンティティが非依存型リレーションシップになっているので、受注インスタンスを削除するとき、店舗インスタンスを削除する必要はない(受注が必任意になっているため制約は発生しない)
詳細は、「【DMBOKで学ぶ】データモデリング」の「論理データモデリング」を参照してください。
物理データモデル
物理データモデルは、システムの非機能要件(特に効率性)を満たし、IT基盤(データベース製品など)に適応したデータの構造を明確にします。
次のような手順で論理データモデルを物理データモデルに変換します。
一般化の解消
参照データオブジェクトの追加
サロゲートキーの割り当て
非正規化
テーブルの定義
インデックスの定義
パーティション化
ビューの定義
詳細は、「【DMBOKで学ぶ】データモデリング」の「物理データモデリング」を参照してください。
データアーキテクチャ
次にデータアーキテクチャについて説明します。
エンタープライズアーキテクチャ(EA)を構成する一要素で、企業のデータの基本的な構造や振舞を表すものです。
データマネジメント知識体系(DMBOK)には、データアーキテクチャの定義が次のように記述されています。
企業のデータニーズを明確にし、ニーズに合う基本となる青写真を設計し維持する。
基本となる青写真を使ってデータ統合を手引きし、データ資産を統制し、事業戦略に合わせてデータへの投資を行うこと。
重要なのは、データアーキテクチャは、
どのデータを統合するのか
どのデータを統制するのか
どのデータ資産に投資をするか
など、データマネジメントに関する意思決定を導く青写真であるといいうことです。
なので、データアーキテクチャはデータマネジメントの一環として設計されるもので、その目的は
データという資産の価値を提供し、管理し、守り、高めること
です。
DMBOKでは、データアーキテクチャとして、以下の2つのモデルを作成すべきとしています。
エンタープライズデータモデル(EDM:Enterprise Data Model)
EDMは、全体的でエンタープライズレベルの実装に依存しない概念または論理データモデルであり、企業全体にわたるデータに関して一貫した共通のビューを提供します。
EDMには、企業の重要なデータ、それらの間の関係、重要な手引きとなるビジネスルール(ビジネスメタデータとして記録する)、いくつかの重要な属性が含まれます。
これらは、すべてのデータが関連するシステム開発プロジェクトの基礎を定めているので、どのプロジェクトのレベルのデータモデルもEDMに基づいている必要があります。データフロー
データがビジネスプロセスやシステムをどのように移動するかを示すものです。
これは、データリネージュ(データの系統)のドキュメントであり、データの発信元、格納場所、使用場所、さまざまなプロセスとシステムの内部や間を移動する際に、データがどのように変換されるかを示します。
重要なのは、戦略的に重要なデータがどの業務活動で生成・収集、変換・蓄積、利活用、破棄されるのか、業務活動とデータライフサイクルの関係を抑えるとです。
これによって、データ品質を維持・向上させるためには、どの業務活動をどう設計、あるいは、改善すべきかあたりをつけることができます。
エンタープライズデータモデルは、
全社単位の全体概念データモデル
活動領域単位の概念データモデルおよび論理データモデル
アプリケーション単位の論理データモデルおよび物理データモデル
から構成されます。

エンタープライズデータモデル(EDM:Enterprise Data Model)の構成
ここでは、EDMをスコープ(企業全体、ビジネスプロセス、アプリケーション)とレベル(概念レベル、論理レベル、物理レベル)で分けて次のように呼ぶようにします。

概念レベル、論理レベル、物理レベルのデータモデルは、上述した概念データモデル、論理データモデル、物理データモデルです。
企業全体の全体概念データモデルには次の種類があります。
全体概念マスターデータモデル
企業全体のマスターデータの概念データモデルです。全体概念分析データモデル
企業全体の分析データの概念データモデルです。
また、企業全体の全体論理データモデルには次の種類があります。
全体論理マスターデータモデル
企業全体のマスターデータの論理データモデルです。全体論理分析データモデル
企業全体の分析データの論理データモデルです。データドメイン
全体論理データモデルの一貫としてデータドメインを定義します。
同様に、企業全体の全体物理データモデルには次の種類があります。
全体物理マスターデータモデル
企業全体のマスターデータの物理データモデルです。全体論理分析データモデル
企業全体の分析データの物理データモデルです。
次に、データフローもスコープとレベルで分けて次のように呼ぶようにします。

アプリケーション、あるいは、情報システムのデータフローは、一つのアプリケーション内のデータフローを表し、通常、データフローダイアグラム(DFD)で記述します。
ビジネスプロセスのデータフローと企業全体のデータフローは、一つのビジネスプロセス内のデータフローを表し、ビジネスプロセスに関わるアプリケーション間のデータの流れを記述します。
企業全体のデータフローは、企業全体の活動(アクティビティ)と、エンティティの関係、つまり、どのビジネスプロセス、および、アプリケーションで、どのエンティティがどうされるのか(生成、参照、更新、削除)を記述することで表現することもできます。
活動(アクティビティ)と、エンティティの関係を表す表をCRUD表、あるいは、CRUD図といいます。CRUDは、Create(生成)、Read(参照)、Update(更新)、Delete(削除)の略です。
なお、概念レベル、論理レベルのデータフローは、上述した概念データモデル、論理データモデルのエンティティで考えます。
次の図は、CRUD表で表した全体概念データフローの例です。

次の図は、業務概念データフローの例です。

次の図は、概念データーフロー(DFD)の例です。

エンタプライズーデータモデルは、データアーキテクチャ(構造×振舞)の静的モデル(構造)で、データフローが動的モデル(振舞)です。
それでは、データアーキテクチャの設計思想(データの仕組を考えるときの要件)は何でしょうか。
概念データモデルと概念データフローの場合、ビジネスを実現するために必要なデータ、つまり、ビジネス活動の事実として記録すべきデータや、ビジネス活動で利活用できるデータの構造とデータのライフサイクルを表すフローを考えて設計します。
論理データモデルと論理データフローの場合、システムの機能要件やデータの品質要件(一意性・一貫性・参照整合性など)を満たすデータの構造とフローを考えて設計します。
物理データモデルの場合、システムの非機能要件(特に効率性)を満たし、IT基盤(データベース製品など)に適応したデータの構造を考えて設計します。
次の図は、記事「データマネジメントの導入」で紹介する山田産業の全体概念マスターデータモデルの例です。


次の図は、記事「データマネジメントの導入」で紹介する山田産業の全体概念分析データモデルの例です。

次のファイルは、記事「データマネジメントの導入」で紹介する山田産業の全体概念分析データフロー(CRUD表)の例です。
次の図は、記事「データマネジメントの導入」で紹介する山田産業の業務概念データモデルの例です。

次の図は、記事「データマネジメントの導入」で紹介する山田産業の業務概念データフローの例です。

次の図は、記事「データマネジメントの導入」で紹介する山田産業の全体論理マスターデータモデルの例です。

次の図は、記事「データマネジメントの導入」で紹介する山田産業の全体論理分析データモデルの例です。

次の図は、記事「データマネジメントの導入」で紹介する山田産業の業務論理データモデルの例です。

次の図は、記事「データマネジメントの導入」で紹介する山田産業の業務論理データフローの例です。

データアーキテクチャの詳細は、【実践!DX】データアーキテクチャの設計方法を参照してください。
メタデータ
次にメタデータとは何か説明します。
メタデータとは、データに関するデータのことです。
メタデータによって、
組織には、
どのようなデータが存在し
それが何を表し、どう分類され(データアーキテクチャ)
どこから来て、組織内をどう移動し活用されるか、またそれに伴いどう成長するか(データリネージュ)
誰が使えて、誰が使えないか(データセキュリティ)
どの程度の品質か(データ品質)
を把握することができます。
DMBOKには、メタデータの重要性を示すために以下のような記述があります。
データマネジメントにおけるメタデータの重要な役割を理解するために大きな図書館を想像してみよう。
そこには、数十万の書籍と雑誌があるのに、図書目録がない。
図書目録がなければ、利用者は特定の本や特定のトピックの検索を開始する方法さえわからないかもしれない。
図書目録は、必要な情報(図書館が所有する本と資料、保管場所)を提供するだけでなく、利用者が様々な着眼点(対象分野、著者、タイトル)から資料を見つけ出すことを可能にする。
メタデータを持たない組織は、図書目録のない図書館にようなものである。
メタデータは、データアーキテクチャを設計したタイミングで、各エンティティと、それを構成するデータ項目に対して記述します。
概念データモデルのメタデータをビジネスメタデータ、論理データモデルをテクニカルメタデータといいます。
以下、メタデータとして定義する項目について説明します。
エンティティのビジネスメタデータ
エンティティ番号
エンティティを一意に識別する番号を記載します。エンティティ名
概念データモデルを構成するエンティティの名前を記載します。説明
エンティティが表すビジネス上の概念、あるいは、意味を記載します。
用語集がある場合、該当するエンティティの用語の内容を記載します。データオーナー(部門)
エンティティ(データ)の管理と保守に責任を持つ部門を記載します。データオーナー(責任者)
エンティティ(データ)の管理と保守に責任を持つ個人を記載します。データオーナー(担当者)
エンティティ(データ)を管理する個人を記載します。データオーナー(連絡先)
データオーナー(担当者)の連絡先を記載します。データの用途
エンティティがどのように使用されるか、どのビジネスプロセスやアプリケーションで利用されるかに関する情報を記載します。データの価値
エンティティがどのようにビジネスの成功に貢献するか、データが組織の意思決定にどのように影響を与えるかを記載します。データソース
エンティティの情報源、データがどこから来たのか、どのシステムまたはプロセスの、どのエンティティから取得されたのかを記載します。
データソースを記載することでデータのリネージュ(来歴)が明確になります。データセキュリティ要件
データ機密レベル
データ機密レベルを記載します。
データ機密レベルに関しては、「データ機密レベル」を参照ください。データ規制対象カテゴリ
データ規制対象カテゴリを記載します。
データ規制対象カテゴリに関しては、「データ規制対象カテゴリ」を参照ください。アクセスできるジョブ
このビジネスエンティティ(データ)にアクセスできるジョブ(職務)を記載します。アクセス権限
上記ジョブのビジネスエンティティに対するアクセス権限を、C(生成)、R(参照)、U(更新)、D(削除)の組み合わせで記載します。
例えば、ジョブがビジネスエンティティの読み取りしかできない場合、Rと記載します。
ジョブがビジネスエンティティの生成、読み取り、更新、削除すべてできる場合、C/R/U/Dと記載します。データ暗号化の必要性
データ転送やデータ保管時の暗号化が必要かどうかを、必要、不要で記載します。データ暗号化の方法
ハッシュや秘密鍵、公開鍵(RSA)などデータ暗号化の方法を記載します。難読化・マスキングの必要性
画面に表示するなどデータを開示する際、難読化・マスキングが必要かどうかを、必要、不要で記載します。難読化・マスキングの方法
置換やシャッフルなど難読化・マスキングの方法を記載します。ロギングの必要性
データアクセスのログを取得する必要があるかどうかを、必要、不要で記載します。ロギングの方法
トランザクションログの取得などロギングの方法を記載します。データ保管に関する要件
データの保管要件やデータの寿命管理に関する情報を記載します。
特定のデータは一定期間後に破棄される必要がある場合があります。セキュリティ監査結果
セキュリティ監査結果を記録します。
データ項目のビジネスメタデータ
エンティティ番号
データ項目が属するエンティティのエンティティ番号を記載します。エンティティ名(日本語)
データ項目が属するエンティティのエンティティ名(日本語)を記載します。データ項目番号
データ項目を一意に識別する番号を記載します。データ項目名
データ項目の名称を記載します。説明
データ項目の意味を記載します。データの用途
データ項目がどのように使用されるかを記載します。データソース
データ項目の情報源、データがどのエンティティのどのデータ項目から来たのかを記載します。
データソースを記載することでデータのリネージュ(来歴)が明確になります。
次のファイルは、記事「データマネジメントの導入」で紹介する山田産業のビジネスメタデータの例です。
エンティティのテクニカルメタデータ
エンティティ番号
エンティティを一意に識別する番号を記載します。エンティティ名
エンティティの名称を記載します。説明
エンティティの意味を記載します。対応するビジネスメタデータのエンティティ番号
対応するビジネスメタデータのエンティティ番号を記載します。対応するビジネスメタデータのエンティティ名(日本語)
対応するビジネスメタデータのエンティティ名(日本語)を記載します。対応するテーブルのテーブル定義書、あるいは、DDLの参照
エンティティに対応するテーブルのテーブル定義書、あるいは、DDLの参照を記載します。ファイルフォーマットのスキーマ定義の参照
エンティティがファイルの場合、ファイルフォーマットのスキーマ定義の参照を記載します。ETLジョブの参照
エンティティのデータに対するETL(Extract, Transform, Load)に関するジョブを定義したドキュメントに対する参照を記載します。データリネージュの参照
上流および下流への変更情報を含むデータリネージュ(データの来歴)を記述するドキュメントに対する参照を記載します。データ管理時期
エンティティの作成時期、更新時期および破棄時期を記載します。集計ロジック
集約エンティティの場合は、元となるエンティティと集約ロジックを記載します。データ量
新規発生、変更発生それぞれのデータ量を記載します。データ品質要件
データ品質評価指標
「データ品質評価指標」から選択して記載します。ビジネスルール
データ品質に関するビジネスルールを記載します。
ビジネスルールに関しては、「データ品質基準」を参照ください。品質測定方法
データ品質を測定する方法を記載します。
品質測定方法に関しては、「データ品質基準」を参照ください。品質評価基準
データ品質を評価する基準を記載します。
品質評価基準に関しては、「データ品質基準」を参照ください。品質測定結果
データの品質を測定した結果(データプロファイリングの結果)を記載します。
データ項目のテクニカルメタデータ
エンティティ番号*
データ項目が属するエンティティのシステムエンティティ番号を記載します。エンティティ名(日本語)*
データ項目が属するエンティティのエンティティ名(日本語)を記載します。データ項目番号*
データ項目を一意に識別する番号を記載します。データ項目名*
データ項目の名称を記載します。説明*
データ項目の意味を記載します。対応するビジネスメタデータのデータ項目番号*
対応するビジネスメタデータのデータ項目番号を記載します。対応するビジネスメタデータのデータ項目名(日本語)*
対応するビジネスメタデータのデータ項目名(日本語)を記載します。対応するカラムのカラム定義書、あるいは、DDLの参照
データ項目が対応するカラムのカラム定義書、あるいは、DDLの参照を記載します。データ型
データ項目のデータ型を記載します。桁数
データ項目の桁数を記載します。主キー/外部キー区分
主キー/外部キーの場合はどちらかを区分する値(主キーか外部キー)を記載します。データドメイン番号
データ項目に対応するデータドメインが別途定義されている場合は、その識別番号を記載します。データドメイン名
データ項目に対応するデータドメインが別途定義されている場合は、その名称を記載します。参照先システムデータ項目番号
外部キーの場合は、参照先データのシステムデータ項目番号を記載します。データ品質要件
データ品質評価指標
「データ品質評価指標」から選択して記載します。ビジネスルール
データ品質に関するビジネスルールを記載します。
ビジネスルールに関しては、「データ品質基準」を参照ください。品質測定方法
データ品質を測定する方法を記載します。
品質測定方法に関しては、「データ品質基準」を参照ください。品質評価基準
データ品質を評価する基準を記載します。
品質評価基準に関しては、「データ品質基準」を参照ください。品質測定結果
データの品質を測定した結果(データプロファイリングの結果)を記載します。
データ品質指標の中の、データの一貫性についてですが、次の3つの制約がに分けることができます。
データ項目の一貫性制約
データ項目間の一貫制約
エンティティ間の一貫制約
次のファイルは、記事「データマネジメントの導入」で紹介する山田産業のテクニカルメタデータの例です。
それから、論理データモデルのエンティティに対する、バッチジョブのログやデータ抽出の履歴などデータ処理とアクセスの詳細を表すメタデータをオペレーショナルメタデータといいます。
DMBOKでは、オペレーショナルメタデータとして次のような例を示しています。
バッチプログラムのジョブ実行ログ
データの抽出とその結果などの履歴
運用スケジュールの異常
オーディット、バランス、コントロールなどの結果
エラーログ
レポートとクエリのアクセスパターン、頻度、および実行時間
バッチとバージョン管理の計画と実行、現在のバッチ適用レベル
バックアップ、保存、実行日付、災害復旧などの規定
SLAの要件と規定
容量の増減と利用パターン
データのアーカイブと保持ルール、関連するアーカイブ
廃棄基準
データ共有ルールや合意事項
IT側の役割と責任、連絡先
データ品質
ビジネスインテリジェンスやデータサイエンスでデータを利活用しようとしても、元となるデータの品質が悪いと、データ解析の信頼性が担保できません。
データ品質とは、データがどれだけ信頼できるかを表すもので、DMBOKには、主に次のような指標で評価することができると説明されています。
正確性
データが現実の実体を正しく表している程度を表す。
完全性
必要なデータが全て存在しているかどうか、その程度を表す。
一貫性
データが、特定のデータベースなどデータセット内で一貫して(正しいルールに貫かれて)表現されているか、あるいは、データセット間で一貫して関連付けられ、一貫して表現されているか、その程度を表す。
一貫性は、1レコード内にある属性値と別の属性値との間(レコードレベルの一貫性)、あるレコードの属性値と別のレコードの属性値の間(クロスレコードの一貫性)、あるレコードの属性値と異なる時点における同じレコードの属性値との間(経時的一貫性)において定義される。
参照キーを介したデータセット間の一貫性(例えば参照先のデータだけがないという欠落がない)を参照整合性という。
一意性
同じ実体を表すデータが同じデータセット内に複数存在していないか、その程度を表す。
適時性
データが適切な時点のものであるか、その程度を表す。
データが発生して利用可能になるまで遅延する場合、遅延の程度によってデータの可用性を定義することによって、データの適時性を判断することができる。
有効性
データが定義域に準拠しているか、その程度表す。
データの定義域とはデータドメインといい、データの型、形式、範囲、ルールなどで定義された、データがとり得る全体を表す。
データ品質の設計
データ品質は、ビジネスのライフサイクルの戦略サイクルの設計フェーズ、あるいは、DXの企業情報基盤(論理基盤)の設計で、データ品質の方針(ポリシー)、基準(スタンダード)、手順(プロシージャ)としてまとめます。

データ品質の方針(ポリシー)
組織や企業の代表者による「なぜデータ品質の維持・向上が必要であるのか」「どのような方針でデータ品質を考えるのか」といった宣言を記述します。
データ品質の基準(スタンダード)
データの品質評価指標、ビジネスルール、品質測定方法、品質評価基準をメタデータのデータ品質要件として定義します。
データのビジネスルールとは、組織内でデータが有用で利用できるためにはどうあるべきかを表すもので、データの品質評価指標と整合させて定義します。
データのビジネスルールのタイプは次のようになります。
定義の適合性
データの定義に対する理解と実装が統一されるべきだというルール。
例えば、計算フィールドのアルゴリズムや親子ステータスの相互依存性のルールなど。値の存在とレコードの完全性
欠損値が許容される許容されないかの条件を定義するルール。書式遵守
データに指定される書式に関するルール。
電話番号書式の標準など。値ドメインに含まれる項目
データに指定される列挙された値(列挙型)のルール。範囲の適合性
データの指定される範囲のルール。
0より大きく100より小さいなど。マッピングの適合性
データが異なるデータドメインで表現できる場合、そのマッピングが適切であるためのルール。一貫性ルール
データがデータセット内で一貫して(正しいルールに貫かれて)表現される、、あるいは、データセット間で一貫して関連付けられるためのルール。
データの一貫性制約は、次の3つに分けることができます。データ項目の一貫性制約
データ項目の値にに関する一貫性制約は、データドメインによって定義することができます。
これを、ここではドメイン制約と呼びます。
例えば、概念データモデル(クラス図)では、次の図のように、値オブジェクトでデータドメインを定義し、エンティティから依存関係で参照させるという関係でドメイン制約を表すことができます。データ項目間の一貫制約
データ項目間の制約を、ここでは関連制約と呼びます。
次のような例があります。
受注日当日の出荷はできないので、受注エンティティの出荷予定日は注文日付より後になるようにする。
概念データモデルでは、受注エンティティの注文日付に以下のような制約を定義することができます。
{出荷予定日>注文日付}
論理データモデルの場合、データ項目定義の関連制約で定義するようにします。エンティティ間の一貫制約
代表的なエンティティ間の一貫制約には次の2つがあります。
存在制約
あるインスタンスが存在するには、他のインスタンスの存在が必要であるという制約です。
概念データモデルの場合、クラス図の関連や多重度で存在制約を表現することができます。
上記論理データモデルに存在制約の例があります。
参照整合性制約
外部キーの値が主キーの値として存在することを保証する制約です。
上記、存在制約が発生します。
正確性の検証
データが正式記録システム(SoR)や他の検証済みソースデータに一致することを検証するルール。一意性の検証
どのエンティティが一意性を満たさなければならないか指定し検証するルール。適時性の検証
データが適時アクセス可能であることを検証するルール。
データ利用者がデータのレイテンシをどの程度許容できるのかデータニーズとして把握し、それを品質評価基準(許容値)として設定する。データのレイテンシ
ソースシステムでデータが生成されてからターゲットシステムでデータが利用可能になるまでの時間差。
データ品質基準を定義した例を以下に示します。

データ品質の管理手順(プロシージャ)
それぞれのデータ品質基準ごとに、実施すべきデータ品質対策の内容を具体的に手順として記載します。
ビジネスのライフサイクルの戦略サイクルの設計フェーズ、あるいは、DXの企業情報基盤(論理基盤)の設計で、データマネジメントプロセスを定義しますが、データマネジメントプロセスを構成する活動に、プロシージャを対応づけます。
データ品質の管理
データのプロファイリング
データプロファイリングは、データを検査し、品質を評価するために行われるデータ分析の一形式です。
データプロファイリングは、統計的手法を活用して、収集したデータの真の構造、コンテンツ、品質を洗い出します。
以下に例を示します。
NULL数
NULLが存在することを検出し、許容可能かどうかを検査できるようにする。最大値・最小値
マイナス値などの異常値を検出する。最大長・最小長
特定の桁数要件を持つフィールドの外れ値や異常値を検出する。個々のカラムに存在する値の度数分布
トランザクション内の国コード分布、値の発生頻度検査、初期値が設定されているレコードの割合など値の妥当性を評価する。データタイプとフォーマット
小数点以下の桁数、スペースの混入などフォーマット要件への不適合レベル。
データのプロファイリングは情報システムの運用テストのタイミングで継続的に実施されます。
データ品質の改善
ここでは、データ品質管理のPDCAのAct(改善)で行う方法について説明します。
データクレンジング
データクレンジングとは、データの誤記や未入力・重複などの不備を修正し、データの正確性を高める作業のことです。
データクレンジング(データの洗浄)やスクラブ(データエラーを取り除くこと)は、データをデータ標準や対象のビジネスルールに準拠させるためにデータを変換します。
データクレンジングは、コストがかかる上、修正による問題の発生などリスクも伴います。
なので、次のような対策を行い、できるだけデータクレンジングの必要性を減らす必要があります。データ入力エラーを防止する制御の実装
ソースシステムのデータ修正
データを生成するビジネスプロセスの改善
データの強化
次の例のようにデータを強化することで品質を上げることができます。
データの強化はビジネスメタデータとして設定することができます。時間・日付スタンプ
データ品質に問題が発生した場合、問題が発生した時間帯を分離できるため、データの生成、更新、破棄された日時を履歴として記録するようにします。データ監査
監査により履歴の追跡と検証のために重要なデータリネージュを記録することができます。参照用語
業界固有の用語も含めた用語集を整備することにより、データに対する理解と統制が強化されます。コンテキスト情報
データに対するレビューと分析をするために、場所、環境、アクセス方法、データのタグなどコンテキスト情報をデータに付加します。地理情報
住所の標準化と位置座標化によって地理情報を強化することができます。人口統計情報
顧客データは、年齢など人口統計情報によって強化することができます。心理学的情報
商品やブランドの嗜好など心理学的情報で顧客データを強化することで市場をセグメント化することができます。評価情報
資産評価、在庫管理、販売促進には、この種の属性を拡張することで強化することができます。
データの構文解析と書式設定
データ構文解析とは事前定義されたルールを利用して、データの内容や価値を定義するためのプロセスです。
これにより、データアナリストは、一連のパターンを定義でき、有効値と無効値を区別するために利用可能なルールエンジン(特定のパターンに一致すると処理が自動的に起動される)にそれを設定することができます。データ変換と標準化
データを、読み取り可能な標準フォーマットに変化します。
データ品質についての詳細は【DMBOKで学ぶ】データ品質を参照してください。
データセキュリティ
DMBOKではデータセキュリティを次のように定義しています。
セキュリティポリシーや手順を立案、開発、実行し、データ資産に対して適切な承認と権限付与を行、アクセスを制御し、監督すること
また、DMBOKでは、データセキュリティの活動目標を次のように定義しています。
全社データ資産に対して適切なアクセスを許可し不適切なアクセスを防止できるようになることプライバシー、保護、機密性に関する規則とポリシーを遵守できるようになることプライバシーと機密性に関するステークホルダーの要件が満たされていることを担保できるようになること
また、DMBOKであげているデータセキュリティに関する主な概念は以下です。
脆弱性
脆弱性とは攻撃や侵略を成功させてしまうシステム上の弱点や欠陥のことである。
脅威
脅威とは組織に対して起こり得る潜在的な攻撃的行動のことである。
リスク
リスクは損失の危険性と潜在的な損失をもたらす物事や状況の双方を指す。
データセキュリティ組織
データセキュリティ機能の全体については、通常、IT部門に属する専門のデータセキュリティグループが責任を負う。
大企業では、CIOやCEOの配下に最高情報セキュリティ責任者が置かれる。
セキュリティプロセス
データセキュリティのプロセスは、アクセス(Access)、監査(Audit)、認証(Authentication)、認可(Authorization)という4つに分類される。
これを4つのAという。
データセキュリティにおけるデータ完全性
不適切な変更、削除、追加から完全に保護された状態を表す。
暗号化
暗号化とは平文を複雑なコードに変換して社外機密情報を隠したり、送受信の完全性を検証したり、送信者の身元を確認したりする処理のことである。
主な方法には、ハッシュ、秘密鍵、公開鍵がある。
難読化またはマスキング
データの意味やデータと他のデータセットの関係を失うことなく、難読化(曖昧または不明瞭にする)やマスキングによってデータを利用できないようにする。
難読化は、参照用にセンシティブデータを画面に表示するときや、想定されるアプリケーションロジックに準拠した本番データからテスト用データセットを作成するときに役立つ。
ネットワークセキュリティ
データのセキュリティには保存状態のデータと移動状態のデータの双方が含まれる。
移動状態のデータではシステム間を移動するためネットワークが必要である。
ネットワークを介したデータセキュリティの概念には、バックドア、ボットやゾンビ、クッキー、ファイアウォール、境界、DMZ、スーパユーザーアカウント、キーロガー、ペネとレーションテスト、VPNなどがある。
データセキュリティの種類
データセキュリティは不適切なアクセスを防止するだけでなく、データへの適切なアクセスを可能にすることも含む。
データセキュリティの種類には、ファシリティセキュリティ(物理的セキュリティ)、デバイスセキュリティ、認証情報のセキュリティ、アイデンティティ管理システム、電子メールシステムのユーザーID標準、パスワード標準、多要素認証、電子通信セキュリティなどがある。
データセキュリティ制限の種類
データの機密性レベルとデータ関連規制の2つの概念からデータセキュリティ制限が設定される。
システムセキュリティのリスク
システムセキュリティのリスクにはネットワークやデータベースに損害を与える要素が含まれる。
このような脅威を放っておくと正当な従業員が意図的か偶発的に情報を誤用してしまったり悪意のあるハッカーに侵入を許してしまう。
ハッキングやフィッシング
コンピュータータスクを実行する巧妙な方法を見つけることや、受信者を騙すメッセージを送ること。
マルウェア
マルウェアとはコンピュータやネットワークに損傷、変更、不適切なアクセスをする目的で作成された悪意のあるソフトウェアを指す。
アドウェア、スパイウェア、トロイの木馬、ウィルス、ワーム、スパムなどがある。
さて、一般的に知られている言葉に情報セキュリティがあります。
情報セキュリティとは、一般的には、情報の機密性、完全性、可用性を確保することと定義されています。
機密性(Confidentiality)
ある情報へのアクセスを認められた人だけが、その情報にアクセスできる状態を確保すること。完全性(Integrity)
情報が破壊、改ざん又は消去されていない状態を確保すること。可用性(Availability)
情報へのアクセスを認められた人が、必要時に中断することなく、情報にアクセスできる状態を確保することをいいます。
それでは、情報セキュリティとデータセキュリティは何が違うのでしょうか。
DMBOKでは、セキュリティポリシーを次の3つに分類しています。
全社セキュリティポリシー
施設やその他資産への従業員のアクセス、電子メールの基準とポリシー、地位や肩書きに基づくセキュリティアクセスレベル、セキュリティ違反報告ポリシーなどグローバルポリシーITセキュリティポリシー
ディレクトリ構造の基準、パスワードポリシー、アイデンティティ管理フレームワークデータセキュリティポリシー
個々のアプリケーション、データベースのロール、ユーザーグループ、情報のセンシティビティに関するカテゴリ
そこで、ここでは、情報セキュリティを、次のように全社セキュリティ、ITセキュリティ、データセキュリティに分けて考え、ここでは、データセキュリティの部分を取り上げたいと思います。
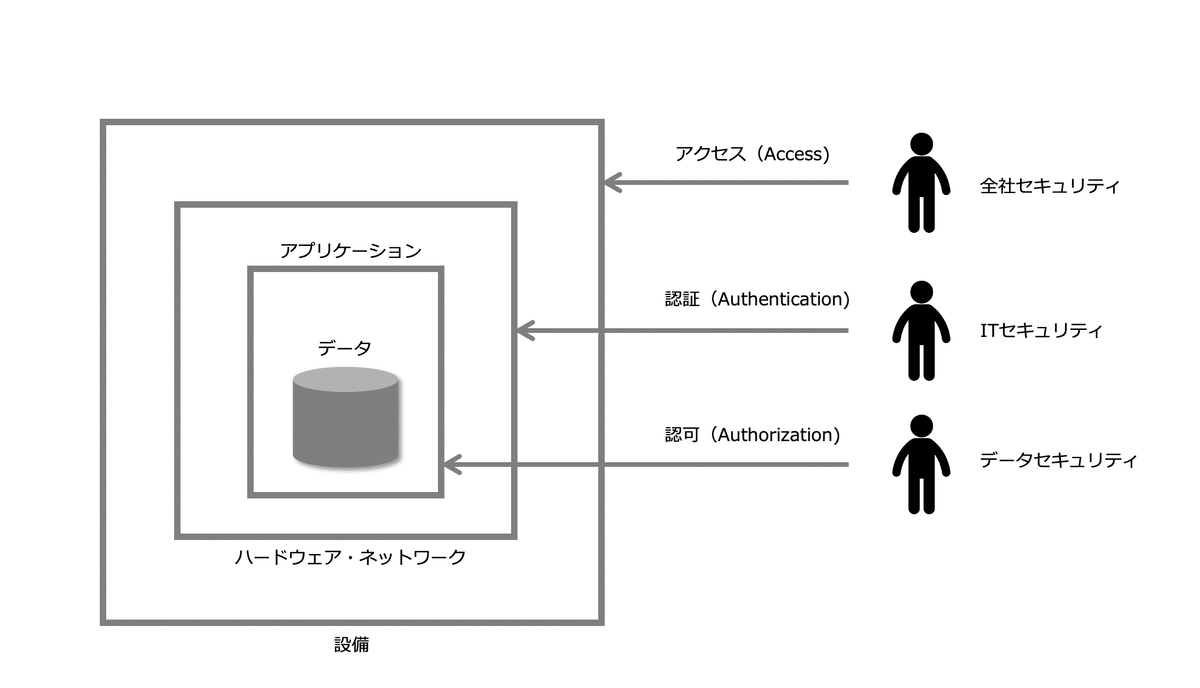
全社セキュリティ
物理的な設備に対する人のアクセスも含めて、企業全体の最も広い範囲のセキュリティを扱う。ITセキュリティ
ハードウェア、ネットワークの内部にアクセスするための認証(Authentication)などハードウェア、ネットワークレベルのセキュリティを扱う。
ITセキュリティは、全社セキュリティを継承する。データセキュリティ
個々のアプリケーションがアクセスするデータも含めてデータにアクセスするための認可(Authorization)などデータレベルのセキュリティを扱う。
データセキュリティは、ITセキュリティを継承する。
データセキュリティの設計
データセキュリティは、ビジネスのライフサイクルの戦略サイクルの設計フェーズ、あるいは、DXの企業情報基盤(論理基盤)の設計で、データセキュリティの方針(ポリシー)、基準(スタンダード)、手順(プロシージャ)としてまとめます。
データセキュリティの方針(ポリシー)
組織や企業の代表者による「なぜ情報セキュリティが必要であるのか」や「どのような方針で情報セキュリティを考えるのか」、「顧客情報はどのような方針で取り扱うのか」といった宣言を定義します。
データセキュリティの基準(スタンダード)
DMBOKでは、データセキュリティ基準として、データ機密レベル、および、データ規制対象カテゴリを定義し、メタデータとして設定することで、企業の全部門がセンシティブなデータに必要とされる保護レベルを正確に把握できるようにする必要があると説明しています。
データ機密レベル
組織は、組織の外部や組織の特定の部門内においてでさえ知られてはならい機密データの機密レベルを決定します。
機密レベルは次の例のように「知る必要がある」かどうかという基準で設定します。
公開用
公衆を含む誰でも利用できる情報。社内向け
情報は社内のメンバーに限定されるが、共有した場合のリスクは最小限である情報。
組織外部に向けて表示したり、説明することはできるがコピーすることはできない。社外秘
適切に結ばれた機密保持契約や、それに類するものがない場合は、組織外で共有することができない情報。制限付機密
「知る必要がある」一定のロールを持つ個人に限定された情報。
制限付機密データにアクセスするには、個人が権限付与手続を踏む必要がある。登録者限定機密
非常に機密レベルが高い情報で、データにアクセスするためには、情報にアクセスするすべての人が法的な合意に署名し、秘密のための責任を負わなければならない。
データ規制対象カテゴリ
特定の種類のデータは、外部の法律、業界標準、契約によって規制されます。
組織は、次の例のように、業務上のニーズを満たす規制対象グループを定義する必要があります。
法律上の規制
個人識別情報(PII:Personal Identification Information)
個人の私的情報で、氏名、住所、電話番号、スケジュール、政府のID番号、年齢、人種、宗教、民族性、誕生日、家族の氏名や仲間の名前、雇用情報(人事データ)、報酬など、個人一人一人を識別できる情報が含まれるもの。
日本の個人情報保護法、EUのプライバシー指令、PCI基準、米国FTC要件など。財務上のセンシティブデータ
インサイダーデータと呼ばれるもので、また、公表されていない現在の財務情報を含む、すべての財務情報を指す。
さらに、未公開の将来事業計画、計画中の合弁、買収、分割、非公開の重要な企業問題、突発的な上級管理職の変更、包括的な売上、注文、請求データも含まれる。
米国ではインサイダー取引法、SOX法、GLBAの対象となっている。医療上のデータ/個人健康情報(PHI:Personal Health Information)
個人の健康や医療に関するすべての情報。
米国では、HIPAAの対象。教育記録
個人の教育に関するすべての情報。
米国ではFERPAの対象。
業界、契約に基づく規制
PCIデータセキュリティ基準(PCI-DSS:Payment Card Industry Data Security Standard)
名前、クレジットカード番号、銀行口座番号、アカウントの有効期限など、金融機関のアカウントで個人を識別できる情報を対象としている。競争上の優位性、企業秘密
企業は競争上の優位性を達成するために独自の方法、混合物、数式、ソース、デザイン、ツール、レシピ、運用技術を利用する場合、業界の規制や知的財産法によって保護される。契約上の制限
ベンダーやパートナーとの契約において、組織は特定の情報の一部がどう利用できるかできなか、どの情報が共有できるかできないかを規定することがある。
環境レコード、有害物質報告、バッチ番号、調理時間、原産地、顧客パスワード、口座番号など。
セキュリティロール
それから、データの機密レベル、データ規制対象カテゴリ、ユーザー機能に基づいて、データセキュリティロールを定義し、それに個々のユーザーを割り当てます。
企業で定義された職務(ジョブ)をデータセキュリティロールとして用いても構いません。
セキュリティロールを定義するときは、該当データにどのようにアクセスできるか、許可されるアクセスも含めて定義するようにします。
例えば、許可されるアクセセス(Permission)を、CRUD(Create,Read,Update,Delete)で定義します。

データセキュリティの管理手順(プロシージャ)
それぞれの対策基準ごとに、実施すべき情報セキュリティ対策の内容を具体的に手順として記載します。
ビジネスのライフサイクルの戦略サイクルの設計フェーズ、あるいは、DXの企業情報基盤(論理基盤)の設計で、データマネジメントプロセスを定義しますが、データマネジメントプロセスを構成する活動に、プロシージャを対応づけます。
データセキュリティの監査
データセキュリティの検証では、定期的に、上記データセキュリティ実施手順で定義された手順に従ってデータセキュリティが機能しているか監査します。
例えば、トランザクションログなどを使って、実際にどのユーザーがどのシステムのどのデータにどのようにアクセスしたか(CRUD)調査し、アクセス権限が有効になっているか、正しい方法でアクセスされたか(SQLなど)確認します。
これによって、データ資産にアクセスしているユーザーに関する情報やアクセス方法に関する情報が獲得でき、異常で突発的で不審な処理を検出できるようになります。
アクセスの挙動の監視と異常の検出をシステムで自動化することもできます。
もしアクセスの異常がインシデントとして検出されたら、問題解決のプロセス(PDCA)を実行するようにします。
データセキュリティについての詳細は【DMBOKで学ぶ】データセキュリティを参照してください。
データ管理基盤
全社のデータの保管や連携を一元的に管理するデータベースやESBなどの物理的なIT基盤をデータ管理基盤と呼びます。
なお、各情報システムのデータベースも含めた物理的なIT基盤を広義のデータ管理基盤と呼びます。

データ管理基盤は、データ基盤、データ分析環境、データ連携基盤から構成されます。
データ基盤
データ基盤は、データ管理基盤の中核になるもので次の要素から構成されます。
マスターデータ管理(MDM)
企業のマスターデータを一元管理する基盤です。
マスターデータ管理(MDM)のソリューションの一つにマスター共有ハブがあります。非正規化データ(生データ)
企業の記録システム(SoR)のデータは、正規化されています。
データが正規化されると効率的に更新することができますが、データがばらばらになっているため検索にコストがかかります。
データを分析するときは様々な視点でデータを検索します。
データを非正規化することで、効率的に検索できるようにしたデータを、非正規化データ(生データ)といいます。
非正規化データ(生データ)は、更新されることがなく、データウェアハウス(データの倉庫)に蓄積されていきます。
また、非正規化データ(生データ)は、ブロックチェーンで管理される場合もあります。非構造化データ
画像、動画、音声、文書、AIモデルなど、データの形式や内容に決まりを設けず管理されるデータのことです。半構造化データ
半構造化データとは、表形式で構造化されたリレーショナル・データベースのテーブルのような厳密な構造を持たないが(例えば、データの値の長さや形式がバラバラ)、一定の構造や規則性があるデータの形式を指します。
半構造化データは、通常、NoSQLデータベースで管理されます。メタデータ
各情報システムのデータベースのデータ、マスター共有ハブのデータ、生データ、非構造化データ、半構造化データのメタデータをデータカタログとして管理することで、必要なデータの有無や所在、使うときの制約を知ることができます。
データ分析環境
データ分析環境は、企業の非正規化データ(生データ)を一元管理するセントラルデータウェアハウスのデータを部門別、目的別に分けたデータマートを構築し、必要な役割の人が必要なデータのみにアクセスすることができるようにした環境のことです。
データ分析環境を構築することで、データの安全性(セキュリティ)を確保することができます。
データ連携基盤
データを連携するEAIやESBなどの基盤のことで、アプリケーション連携基盤と同義です。
次の図は、データ基盤をAWSのサービスで実現する場合のイメージです。

データ統合と相互運用性
データ統合と相互運用性は、DII(Data Integration and Interoperability)といいます。
データ統合
データ統合は、異なるデータソースからのデータを結合または統合するプロセスです。
異なるデータソースから取得されたデータは、異なる形式や構造を持っていることがあります。データ統合の目的は、これらの異なるデータを一貫性のある形式に変換し、統合することです。
データ統合は、データウェアハウスの構築、データマートの統合、マスターデータの統合などに関連しています。
データ相互運用性
データ相互運用性は、異なるシステムやプラットフォーム間でデータを共有し、効果的に連携させることを指します。
異なる組織、アプリケーション、データベースが互いにデータを理解し、共有できるようにするための標準やプロトコルが必要です。
データ相互運用の主な目的は、異なる環境で生成されたデータを効果的に共有し、利用することで、情報の流れをスムーズにし、意思決定をサポートします。
データ統合
データ統合に関連する概念を整理します。
ETL
ETLは、抽出(Extract)・変換(Transform)・取込(Load)の略です。
異なるデータソースから取得されたデータは、異なる形式や構造を持っていることがあります。データ統合の目的は、これらの異なるデータをETLによって一貫性のある形式に変換し、統合します。
ETLは、データ統合の要件によって、定期的に予定が組まれたイベント(バッチ)として、または新しいデータや更新されたデータが利用可能となった時点(リアルタイムやイベント駆動)で実行されます。
組織が日々の業務遂行に使用するオペレーショナルデータ(トランザクションデータ)は、リアルタイムや準リアルタイムで行われる傾向にありますが、データウェアハウスやデータマート上の分析やレポート作成に必要なデータはバッチジョブとして組み込まれることが多いです。
なお、変換(Transform)の例には以下があります。
フォーマットの変換
例えばEBCDICからASCIIなど技術的なフォマットを変換します。構造の変換
例えば正規化データを非正規化データにするなどデータの構造を変換します。意味的変換
例えばソースデータの性別コードの値0,1,2を、ターゲットデータの性別コードの値FEMAILE、MAILE、NOT PROVIDEDに変えるなど、データの値を変換します。重複排除
データをユニークにする必要がある場合、重複データを排除します。並べ替え
データの順序を変更します。
ビッグデータを扱う場合、データを、一旦、データレイク(様々な種類や構造を持つ膨大な量のデータをインジェストして保存し評価、分析できる環境)にロードしてで変換するELTが一般的です。

レイテンシ
レイテンシとは、ソースシステムでデータが生成されてからターゲットシステムでデータが利用可能になるまでの時間差のことです。
データ統合を考える場合、レイテンシが高い(バッチ)か、低い(イベント駆動)か、非常に低い(リアルタイム同期)か考慮して処理の方法を考える必要があります。
バッチ
データウェアハウスやデータマート上の分析やレポート作成に必要なデータのように、レイテンシが低い場合、定期的に一定量のデータをまとめて処理するバッチ処理がとられます。イベント駆動
ソースシステム側に起きたイベントをターゲットシステム側に通知することで、ターゲットシステム側の処理が駆動される形態です。
この場合、ソースシステム側は、ターゲットシステム側の更新を待たずに処理を続行することができます(非同期処理)。
非同期処理によって、ターゲットシステムが利用できない場合でも、ソースシステムが止まったり利用できなることはなく、システム間を疎結合にすることができます。リアルタイム
例えば、システム間でトランザクション整合性を保持する必要があるなど、ソースシステムとターゲットシステムのデータ間の時間の遅れや相違が許容されない場合は、リアルタイムにデータを同期させる必要があります(同期処理)。
同期処理の場合、ソースシステムが利用できない場合、ターゲットシステムが利用できなる可能性があり、システム間を密結合にします。
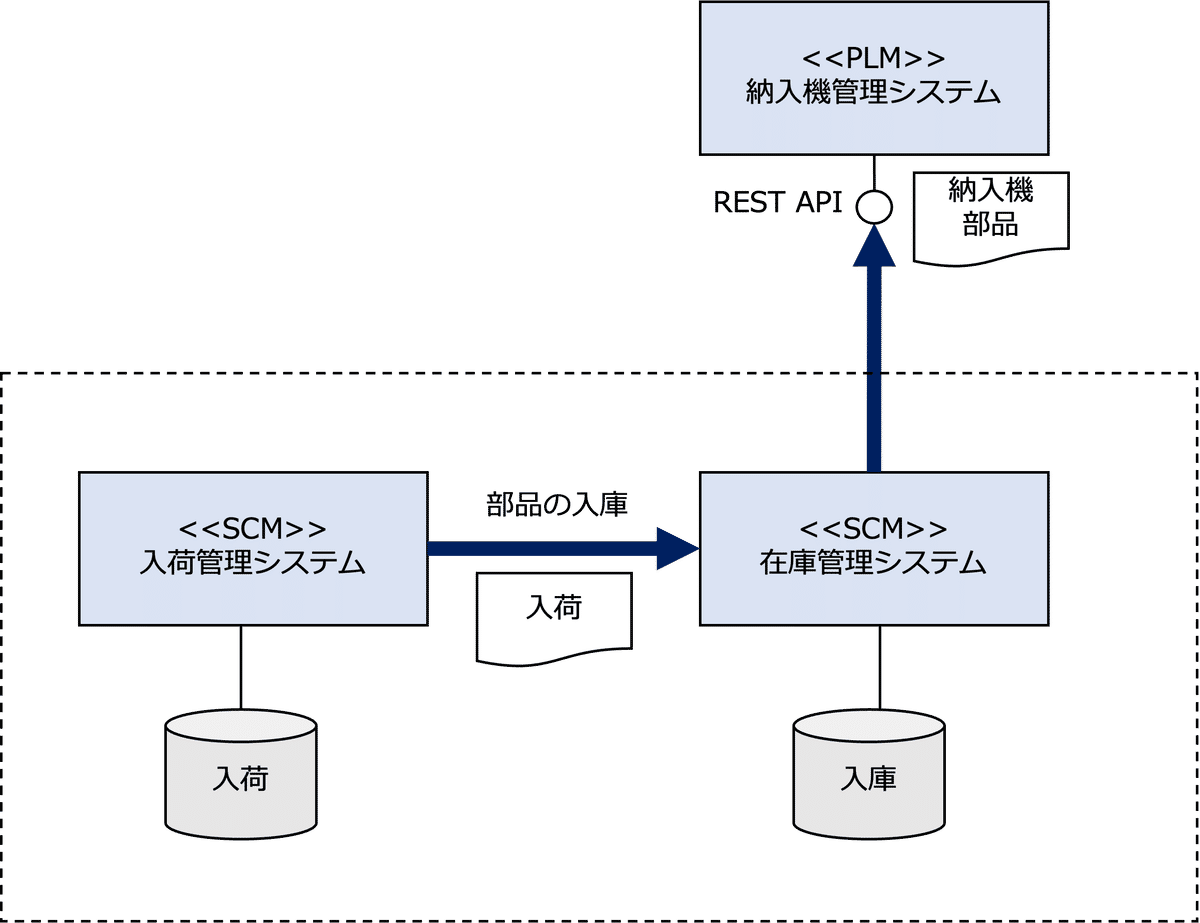
下図は、顧客情報が変更されたイベントを受けて、ソースシステムがTopicを介してターゲットシステムに非同期で顧客データをブロードキャストしている例です。

下図は、必要に応じてターゲットシステムがソースシステムからAPIを介して顧客データを取得する例です。

データ相互運用性
データ連携モデル
データ転送のためにシステム間を接続する方法にはポイント・ツー・ポイント(下図左)とハブ&スポーク(下図右)があります。

ポイント・ツー・ポイントの場合、比較的小さなシステム群を対象にする場合は問題がありませんが、多数のシステムが同じソースから同じデータを必要とする場合、管理も複雑になるとともに、ネットワーク効率も急速に低下します。
データの共有に3つ以上のシステムが関与する場合、ハブ&スポークを考える方が管理を簡素化できます。
データ連携アーキテクチャ
ここでは、データ連携アーキテクチャとしてEAIとESBを紹介します。
EAI(Enterprise Application Integration)
企業内における多種多様なコンピュータシステム群や各種ビジネスパッケージ群を有機的に連携する方式や技術のことです。ESB(Enterprise Service Bus)
企業内の異なるソフトウェアアプリケーションやサービス間での通信とデータ転送を管理・仲介するための方式や技術のことです。
EAIはハブ・アンド・スポーク型アーキテクチャによるモノリシックな構成であり、ESB ではその構成要素を機能単位に分割し、必要に応じて協調動作するよう分散配置することができます。
次の図は、ESB/EAIを介して各情報システムがデータを連携しているイメージです。

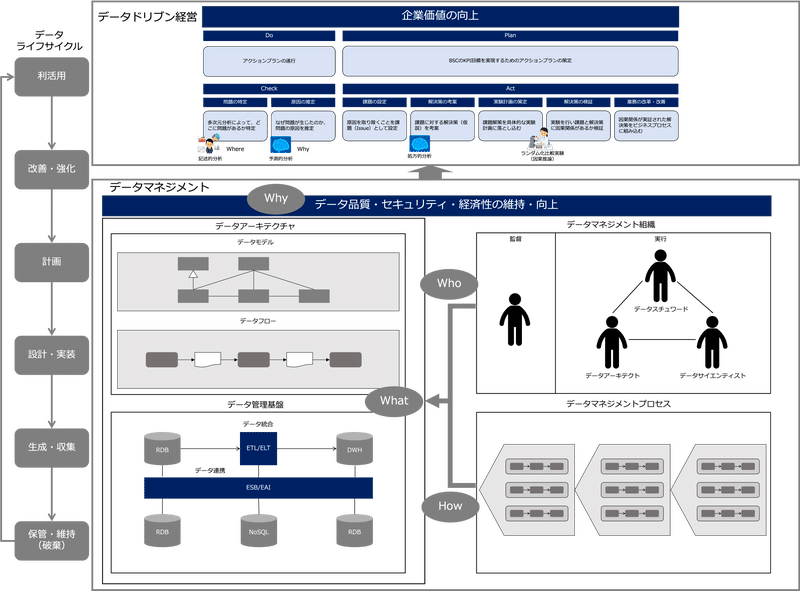
データドリブン経営
事業ライフサイクル
次の図は、ビジネスのライフサイクルを表しています。

ビジネスには、その存在意義になる事業パーパスがあります。
「ビジョナリーカンパニーZERO」という書籍では、事業パーパスを
組織が存在する根本理由
とし、組織の行方を照らす星のように、常に努力すべき目標ではあるが、完全に達成されることはない(100年間に渡って会社の指針となる)と明記しています。
それに対して、ビジョン(書籍ではミッション)は、
大胆で説得力のある野心的目標
とし、明確なゴールと具体的期限がある、達成されると、新たなビジョンが設定される(理想的な時間軸は10年から25年)と明記しています。
以下、ビジョナリーカンパニーZEROからの引用です。
…
山岳地帯で案内星を追いかけるたとえ話を思い出してほしい。
パーパスはこの案内星で、常に地平線上に浮かんでいる。
決して手の届かないものだが、常に前へ前へと導いてくれる。
一方、ミッションはあなたがその時々に登っている山だ。
頂上に着いたら、再び案内星に視線を戻し、次に登るべき山を選ぶ。
ビジネスがビジョンを設定して、それを実現するための事業戦略を策定し、実行するサイクルを、ここでは「戦略サイクル」と呼びます。
戦略サイクルは、次のフェーズから構成されます。
設計フェーズ
ビジネスの本質的な型(ビジネスモデル)を設計するとともに、事業戦略の本質である戦略マップを策定し、戦略目標に対するリスクとコントロールを設計するフェーズです。戦略フェーズ
事業パーパスを具体化したビジョンを設定し、それを実現するための事業戦略を、戦略マップを具体化することで、策定します。
事業戦略は、BSCとアクションプランに展開されます。
※BSCのKPI目標値にはリスクの許容度を反映します。構築フェーズ
戦略フェーズのアクションプランに基づいて、ビジネスシステムを構築します。運用フェーズ
構築されたビジネスシステムを、会計期間ごとのマネジメントサイクル(PDCA)を通して運用します。
データドリブン経営とマネジメントサイクル
データドリブン経営ですが、一般的には、経営判断やビジネス戦略の決定に、データや分析結果を活用することを指しますが、ここでは、
社員一人ひとりがデータを利活用して自律的に業務課題を解決することができる状態に変革すること
を目指します。
具体的には、データマネジメントが導入された後、上記戦略サイクルの構築、運用フェーズで、社員一人ひとりがデータを活用して仮説を検証するマネジメントサイクル(PDCA)を遂行します。

計画(Plan)
バランススコアカード(BSC)のKPI目標を実現するためのアクションプランを策定します。実行(Do)
アクションプランを実行します。検証(Check)
検証は「問題の特定」「原因の推定」の順で行います。問題の特定
まず、KPI目標値と実績のGapである問題を発見します。
次に、ドリルダウン・アップやスライシングによる多次元分析によって、どこに問題があるか特定します。
データ分析は、記述的分析、予測的分析、処方的分析に分けることができますが、多次元分析は、記述的分析(Descriptive Analytics)になります。原因の推定
多次元分析によって、どこに(Where)問題があるか特定できたら、次に、なぜ(Why)問題が生じたのか、仮説推論(Abduction)で問題の原因を推定します。
そして、回帰分析など機械学習を通して原因の確からしさを検証します。
回帰分析は主に帰納(Induction)的な手法であり、与えられたデータから一般的な法則になる変数間の関係性を導きます。
なお、回帰分析は、予測的分析(Predictive Analytics)になります。
改善(Act)
改善は、「課題の設定」「解決策の考案」「実験計画の策定」「解決策の検証」「業務の改革・改善」課題の設定
まず、原因を取り除くことを課題(Issue)として設定します。解決策の考案
次に、仮説推論(Abduction)で、課題に対する解決策(仮説)を考えます。
解決策ですが、レベルの違いによって、次のように分類することができます。計画レベルの見直し
計画レベルの見直しとは、同じ戦略サイクルの、アクションプランの見直しです。
例えば、やり方、アプローチを変えてみるなどです。
その中には、AIを活用した解決策(レコメンド、最適な治療法の提案、最適な学習経路の提案など)も含みます。
AIを活用した解決策は、処方的分析(Prescriptive Analytics)になります。
生物で言えば、ホメオスタシス(恒常性)のように、環境の変化に適応するために組織の状態を最適にするレベルと似ています。戦略レベルの見直し
戦略レベルの見直しとは、事業戦略を見直すということです。
なので、新しい戦略サイクルを設け、戦略フェーズから始める必要があります。
例えば、アプリケーションアーキテクチャは同じだけど、新しいパッケージ製品を導入するのは戦略レベルの見直しになります。設計レベルの見直し
設計レベルの見直しとは、エンタープライズアーキテクチャ(型)そのものを見直すということです。
なので、新しい戦略サイクルを設け、設計フェーズから始める必要があります。
例えば、IoTやAI、ブロックチェーンなど最新の技術を活用した変革アプリケーションの創出などアプリケーションアーキテクチャを再設計するのは設計レベルの見直しになります。
生物で言えば、「種」が変化(遺伝子レベルの変化)するように、環境の変化に適応するために、新しく構造そのものを変えるレベルに似ています。
解決策の検証
ランダム化比較実験を行い課題と解決策に、因果関係(一般的法則)があるか統計的に検証します。
すべての解決策(仮説)に統計的な有意性がない場合、課題も見直します。
PoC(Proof of Concept:概念実証)も解決策の検証に入ります。業務の改革・改善
因果関係が実証された解決策をビジネスプロセスに組み込みます(実験から実践へ)。
ここでは、例えば、これまで人が行っていた活動をAIに置き換えたり、業務の流れそのものを変えるなど大幅なビジネスプロセスの変更を伴うものを業務改革と位置づけ、ある活動のビジネスルールの変更など、従来のビジネスプロセスの大幅な変更を伴わないものを業務改善と位置づけます。
そして、解決策が組み込まれたビジネスプロセスをベースにPlan(アクションプラン)を策定します。
実証された解決策を適用してアクションを実行し結論を導くのは演繹(Deduction)的アプローチです。
以上のように、データドリブン経営は、仮説検証を繰り返す科学的アプローチです。
PDCAの結果をすべて記録しノウハウとして蓄積することで学習し進化する組織が実現します。