
【論文】Eval Drivenなアプローチで行うLLMエージェントの設計

「An Evaluation-Driven Approach to Designing LLM Agents: Process and Architecture」という論文についてのメモ・感想です。
LLMを基盤としたAIエージェント、LLMエージェントは、高レベルな目標を与えられると、自律的にタスクを実行し、外部ツールを活用しながら目標達成を目指します。
しかし、このような自律性の高いLLMエージェントには、複雑なタスクや曖昧な状況に直面した際の予測不可能な振る舞いや、意図しない結果をもたらす可能性も存在します。
本論文は、テスト駆動開発(TDD)の考え方を応用し、LLMエージェントの開発プロセスに評価を組み込むアプローチを提案した内容です。
背景と課題
従来のソフトウェアテスト手法は、事前に定義された要件に基づいてテストケースを作成し、デプロイ前の検証に重点を置いていました。
しかし、LLMエージェントにおいては、以下のような新たな考慮が必要になってきます。
システムレベルの評価(System-Level Evaluation)
既存の評価フレームワークはモデルレベルの評価に留まっていることが多い
LLMエージェントはプロンプト、ナレッジベース、ガードレールなど多数のコンポーネントで構成されるコンパウンドAIシステムである
システム全体をスコープとした評価が必要
評価駆動型設計(Evaluation-Driven Design)
高レベルで事前に定まらない目標に基づく動的な適応が求められる
導入前のオフライン評価や実行時モニタリングだけでなく、継続的な評価と実行時の適応も含めたイテレーティブな開発サイクルが必要
エージェントの動作を品質、安全性、運用目標に体系的に整合させる評価主導の設計アプローチ
評価結果の活用(Use of Evaluation Results)
ソフトウェア開発の手法ではエラー発生ポイントの特定とコード更新トリガーに留まっていた
より広範な影響と活用(プロンプト最適化、エージェント計画の改善など)が必要
要点
LLMエージェントの評価は、単なるパフォーマンス測定を超え、エージェントのライフサイクル全体にわたる継続的なプロセスとして組み込む必要があります。
本論文では、LLMエージェントの評価を体系化し、開発ライフサイクル全体に組み込むフレームワークを確立し、下記二つの課題に貢献することを目的としていると言及されています。
LLMエージェントをどのように体系的に評価できるか
継続的な評価をエージェント設計のアーキテクチャにどのように統合できるか
ここからは、論文内で主張されているLLMエージェント評価のためのプロセスモデル、評価駆動設計、リファレンスアーキテクチャについてです。
主な成果・知見
評価駆動設計(Evaluation-Driven Design)
3つの主要な原則に基づいた評価駆動設計を主張しています。
後述するプロセスモデルとリファレンスアーキテクチャーが評価駆動設計を支える・機能させるためのものになります。
ライフサイクル統合
設計・開発(デプロイメント前)と実行時・保守開発(デプロイメント後)の両方で評価を組み込み、全体のライフサイクルを統合する
有意義なフィードバックループ
オフライン評価とオンライン評価の両方からの洞察をフィードバックし、オンライン・オフラインでの改善に役立てる。
継続的な学習と改善
評価結果に基づいて、モデルとシステムレベルの両方で適応的な調整を可能にすることで、継続的な改善を実現
LLMエージェント評価のためのプロセスモデル
エージェントの開発、デプロイ、運用段階全体にわたって一貫したライフサイクルにわたる評価を実施するためのアプローチです。
以下の4つの主要なステップで構成されています
評価計画の定義
ユーザーの目標、ガバナンス要件、初期アーキテクチャを元に、エージェントの「あるべき姿」を定義
単なるテスト計画ではなく、評価の目的や範囲、シナリオまで含めた計画を立てる
テストケースの生成
評価計画に基づいて、一般的なベンチマークとシナリオ固有のテストケースを作成
ドメイン知識やエキスパートの意見を活用
必要に応じてLLMを使用して合成データを生成
標準的なケースとエッジケースの両方をカバー
オフライン・オンライン評価の実施
オフライン評価:制御された環境での基本的な性能評価
オンライン評価:実世界での継続的なモニタリングと安全性確認
最終結果と中間プロセスの両方を評価
最終結果の評価(成功率、正確性、ユーザー満足度など)
中間プロセスとアーティファクトの評価(プロンプト、中間結果、ツール出力など)
ユーザーフィードバックや実運用データを収集
分析と改善
オンライン、オフライン両面での改善
運用中のリアルタイムな調整と、システム全体の改善・修正という2つのアプローチで改善
評価結果に基づいて安全性要件を更新

プロセスモデルのファーストステップは評価計画を立てることです。
ユーザーの目標、法的要件、エージェントの設計を考慮した上で、評価をアップフロントに据えて、単なるテスト計画ではなく、エージェントの「あるべき姿」を定義するステップとなります。
次にテストケースの開発では、一般的なベンチマークに加えて、特定のシナリオに基づくテストを作成します。
専門家の知識やLLMを活用して、通常のケースだけでなく想定外の状況にも対応できるテストケースを準備します。
第3ステップの評価実施では、まず制御された環境でのオフライン評価を行い、
その後実環境でのオンライン評価へと移行します。ここでは最終出力だけでなく、中間プロセスも評価の対象とします。
最後の分析・改善では、評価結果を基に2つのアプローチで改善を行います。1つは運用中のリアルタイムな調整、もう1つはシステム全体の改善・修正です。
これら4つのステップを1つのサイクルとして機能させ、継続的な改善を通じてエージェントの品質と安全性を高めていくことが主張されています。
特筆すべき点として、「解釈的フィードバック(interpretative feedback)」の重要性を強調しています。
単純なメトリクスや数値評価を超えて、エラーの具体的な原因(なぜユーザーが不満を感じたのか等)、フィードバックの提供者(エンドユーザー、ドメイン専門家、AI)、そして評価の文脈(なぜその出力が「改善の余地あり」と判断されたのか)を体系的に捉える評価手法です。
リファレンスアーキテクチャ
継続的な評価をエージェント設計の中心要素として組み込む、評価ドリブンを実現するためのアーキテクチャも提案されています。
サプライチェーンレイヤー
計画・設計の実施
データの収集・処理
モデルの選択と評価
システム構築と評価
テストケースや安全性要件の作成
エージェントレイヤー
外部環境(ユーザー、他のエージェント、ツール、知識ベース)との相互作用
内部コンポーネント(コンテキストエンジン、推論・計画モジュール、ガードレールなど)の管理
オペレーションレイヤー
評価コンポーネント:人間とAIによる継続的な評価
AgentOpsインフラ:ログ収集、性能診断、分析支援
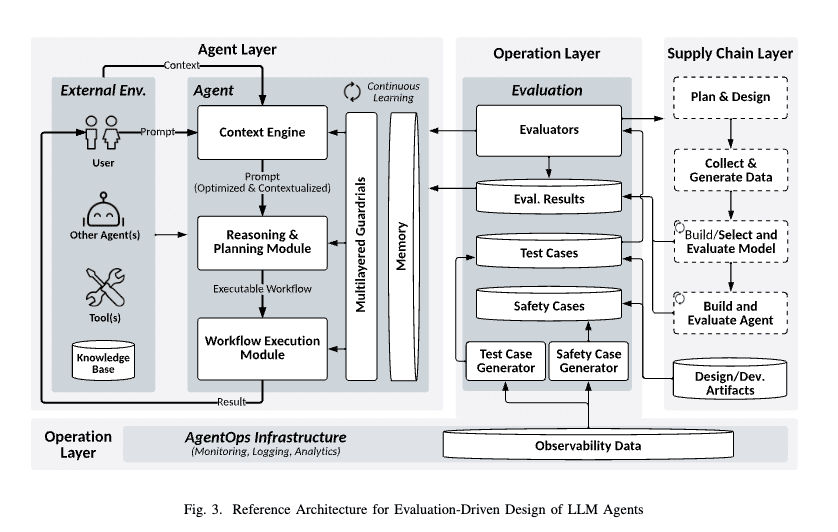
上記アーキテクチャが目指すところは、下記3点です。
ライフサイクル全体での評価の統合
意味のあるフィードバックループの構築
継続的な学習と改善の実現
各レイヤーは密接に連携して機能します。例えば、エージェントレイヤーでの実行結果はオペレーションレイヤーによって継続的に評価され、その結果はサプライチェーンレイヤーにフィードバックされて設計の改善に活用されます。
オペレーションレイヤーの評価コンポーネントには、EvaluatorsやTest Case Repository、Evaluation Results Repository、Safety Case Generatorなどが定義されています。
例えば、オンライン評価で発見された新しいエッジケースは、Test Case Generatorを通じて新しいテストケースとなり、それが次のオフライン評価に活用されます。
また、Safety Case Generatorは評価結果を基に安全性要件を更新し、それが次の評価計画に反映されるという具合です。
Test Case Generator
評価結果や運用ログから新しいテストケースを動的に生成・更新
例えば、実運用で発見されたエッジケースや繰り返し発生するエラーに基づいて、より適切なテストケースを自動的に作成
実装等の詳細は不明なのでコメントし難いところはありますが、このアーキテクチャの主目的である「評価を中心にライフサイクル全体でフィードバックループを回す」、「オフラインおよびオンライン評価の双方の活用」、「モデルとシステムの両レベルで適応的なチューニング」という主要原則は重要です。
AgentOpsというワードも登場しています。
LLMOpsの名前をよく聞くようになった昨今ですが、今後はより広範な「AIエージェント」という文脈で評価を捉えて、付き合っていくことになるだろうと感じます。
一方で、シンプルに「実世界での大規模な実証実験がまだ行われていない」、「ドメイン特有の要件への適応が必要」、「スケーラビリティの検証が必要」という実用上の課題は未検証であり、あくまでもリファレンス的なアーキテクチャであることは注意です。
所感
Eval-driven developmentについて、詳細に検討して頂き参考になります!という論文でした。
LLMエージェントに閉じた話ではありませんが、VercelもEval-driven developmentについてテックブログで言及している通り、LLMアプリ・エージェント開発において評価を前提にサイクルを回すことを重要視しています。
活用するにあたっては、評価だけをとっても、マクロ・ミクロに多様に存在しうる評価指標をシステムレベルでどう定めて、どこまで自動化・リアルタイムの動作のチューニングに使うのか?など論点は大量にあるように感じます。
このアーキテクチャ、プロセスモデルをそのまま採用するかはさておき、自分たちのドメイン・システムで評価駆動な開発サイクルを志す際の参考になるのではないでしょうか。
他にも今回紹介しきれない様々な概念・コンポーネントを定義してくれており、こちらも参照するには便利そうだなーと感じています。
評価ドリブンを謳う通り、プロセスモデル上はファーストステップで評価計画を立てることになりますが、この評価も継続的に育てるものに実際にはなるでしょう。
継続的にLLMアプリケーションの評価基準や自動評価をアップデートする仕組みであるEvalGenについて書かれた論文「Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences」も参考になりそうです。
オンライン評価とオフライン評価についても説明されていたりと、評価全般の概要を押さえる意味でも便利かもしれません。
他にも色々書かれているので、関心がある方はご覧になってください!
参考
蛇足: 評価の時間的スケール
Claudeにお願いしたら評価の時間的スケールについても考えてくれました。
継続的なフィードバックループといえども、フィードバックにかかる時間軸が異なるというのは確かにですね。
マイクロスケール(リアルタイム〜数時間)
プロンプトの即時最適化
ガードレールの動的調整
リソース配分の最適化
ユーザーフィードバックへの即時対応
メゾスケール(日次〜週次)
パターン分析に基づく改善
ワークフロー最適化
性能トレンド分析
A/Bテストの実施と評価
マクロスケール(月次〜四半期)
アーキテクチャの見直し
長期的な学習効果の分析
コスト効率の最適化
戦略的な改善計画の立案