
社内Slack Botを改善するためにRagasでRAGを評価する

はじめに
はじめましてQunaSys、CRSチームの山口です。
みなさん、業務でRAGを使用していますか?
論文探し効率化のためのSlack BotであるPaperBotくんではRAGを使用しています。
PaperBotくんの要約機能であまりいい回答が返ってこなくて、いくつかのテクニックを使ってRAGの精度を上げようとしました。が、いまいち良くなったのかどうかいまいち評価できませんでした。
この課題を解決するために、今回の記事では「論文探し効率化のためのBotであるPaperBotくん」の評価を、RAGを評価するためのフレームワークであるRagasで実施したいと思います。
RagasでTest early and oftenができるようになりましょう!
最後には評価がきちんとできているかを確認するためにgpt-3.5-turboとgpt-4-turbo-previewでの比較を見ていきたいと思います。
※ Ragasの表記は、ドキュメントに合わせてRagasで統一します。
社内SlackBot「 PaperBotくん」は何ができるの?
まず、評価対象であるSlackBotであるPaperBotくんを紹介させてください。
弊社では多くのResearcherが在籍しており、頻繁にSlackの論文チャンネルに量子コンピュータ関連の論文の共有が行われています。
PaperBotくんはその論文共有を効率化するために試験的に運用しているSlackBotです。
機能は簡単に二つあります。
機能1. arXivに投稿されている論文のRSS FeedをSlackに投稿する。
以下RSSフィードをSlackに投稿している様子です。
主に投稿する時にやっているのは以下の3つです。
arXivフィードの内容+サマリーから抽出したキーワードで投稿
フィード内のサマリーを日本語化してスレッド内に投稿
投稿する順序は、投稿時間とScirateの両方を加味して独自でスコアリングしてソート
日本語サマリーはすごいコミカルですね!

機能2. 要約コマンドを使うと「落合陽一先生フォーマット」で論文を要約する。
落合陽一先生フォーマットに関してはこちらを読んでください。
基本的には以下の項目ごとに要約するようなフォーマットです。
- どんなもの?
- 先行研究と比べてどこが優れているか?
- 技術や手法の核心は何か?
- どのようにしてその効果を検証したか?
- 議論されている点はあるか?
- 次に読むべき論文は何か?
以下落合陽一先生フォーマットで要約してもらっている様子です。

Ragasとは?
Ragasは、Retrieval Augmented Generation Assessmentsの略でRAGを評価するためのフレームワークです。
評価のためのフレームワークなので、Ragasは評価に関わる幾つかの機能が使用できます!
Ragasのドキュメントのコアコンセプトをみると何ができるかわかるのでいくつか引用しておきます。
(日本語訳)
1. アプリの評価に使用できる多様なテストデータセットを合成的に生成します。
2. アプリケーションのパフォーマンスを客観的に測定できるように設計されたLLM支援評価メトリクスを使用します。
3. 実用的な洞察を与えることができる、より小さく、より安価なモデルを使用して、運用中のアプリの品質を監視します。例えば、生成された回答における幻覚の数などです。
4. これらの洞察を使用して、アプリケーションを反復し、改善します。
(原文まま)
1. Synthetically generate a diverse test dataset that you can use to evaluate your app.
2. Use LLM-assisted evaluation metrics designed to help you objectively measure the performance of your application.
3. Monitor the quality of your apps in production using smaller, cheaper models that can give actionable insights. For example, the number of hallucinations in the generated answer.
4. Use these insights to iterate and improve your application.
Ragas/Core Concepts
簡単にまとめるとRagasでは
1. データセットを作って、
2. RAGを評価
3. モニタリング
4. 1 ~ 3を元に改善に繋げられるようにする
ことができそうですね。
Ragasの思想として、Metrics-Driven DevelopmentをRAGの開発に取り入れてLLMとRAGアプリケーションの継続的な改善を促進していくことを目的としているみたいです。
Ragas面白いですね。
Ragasの評価指標
Ragasで使用できる指標はいくつかあります。
Answer correctness etc …
今回は、この中でもRAGを評価する時に重要だとされる4つの指標について紹介します。
RAGはRetrievalとGenerationの二つのプロセスに分かれます。
Ragasの評価指標はそれぞれのプロセスを評価することができます。
Generation → faithfulness , answer relevancy
Retrieval → context precision , context recall

これらの評価指標は以下のデータに基づいて評価されます。
- Question : LLMに投げる質問
- Answer : LLMが生成する回答
- Context : Retrieverが取得してきた文献情報など
- Ground Truth : 参考となる正確な回答
これらのデータと評価指標の全体像を図のような形になっています。

では実際に、それぞれの指標を見ていきましょう。
Answer Relevance

どんなメトリクス?
生成された解答が与えられたプロンプトにどれだけ適切であるかを評価します。
不完全な回答や冗長な回答はスコアが低くなるのが特徴です。
必要なデータ
Question, Answer
スコアの計算方法は?
LLMは生成された回答から質問を複数回生成する→生成された質問と元の質問の間の平均コサイン類似度が測定する。
コンセプトは?
基本的には、生成された回答が質問に正確に対応しているなら、LLMは生成した回答から元の質問に沿った質問を生成できるよね?
Faithfulness

どんなメトリクス?
与えられたコンテキストに対して、生成された回答が忠実かどうかを測定し評価します。
必要なデータ
Context, Answer
コンセプトは?
生成された回答が忠実であることは、生成された主張は与えられたコンテキストから推測できるよね?
スコアの計算方法は?
$$
\text{Faithfulness score} = {|\text{Number of claims in the generated answer that can be inferred from given context}| \over |\text{Total number of claims in the generated answer}|}
$$
Context Precision

どんなメトリクス?
質問の根拠となるような関連アイテムが上位にランクされているかを評価します。
必要なデータ
Question, Context
コンセプトは?
質問の根拠となるような関連アイテムが上位にランクされていないとコンテキストとしてはおかしいよね?
スコアの計算方法は?
$$
\text{Context Precision@k} = {\sum {\text{precision@k}} \over \text{total number of relevant items in the top K results}}
$$
$$
\text{Precision@k} = {\text{true positives@k} \over (\text{true positives@k} + \text{false positives@k})}
$$
Context Recall

どんなメトリクス?
生成された回答と用意されている正確な回答を比べてどれぐらい一致しているかを評価する。
必要なデータ
Context, Ground Truth
スコアの計算方法は?
$$
\text{context recall} = {|\text{GT sentences that can be attributed to context}| \over |\text{Number of sentences in GT}|}
$$
今回の評価ではGround Truthを用意しないので、以下の三つの指標で評価をします。
Answer Relevance
Faithfulness
Context Precision
今回のRAGの評価フロー
評価されるまでのフローは以下の図のようになります。
1. PaperBotくん上でデータを作成
2. LangSmithのデータセットに保存
3. そして最後にRagasで評価

データセットの作成
ではまずデータセットの作成の話から始めます。

PaperBotくんで今回評価したい機能は「要約コマンドを使うと落合陽一先生フォーマットで論文を要約する」機能です。
基本的には以下の項目ごとに要約していきます。
どんなもの?
先行研究と比べてどこが優れているか?
技術や手法の核心は何か?
どのようにしてその効果を検証したか?
議論されている点はあるか?
次に読むべき論文は何か?
Slackに返信する時にはこれらを一つの文章にして返信しますが、データセットでは各質問ごとにデータとしてデータセットを作成します
データセットを作成するのに考えた点
データセットの作成場所にはLangSmithを使用します。
保存する際には幾つかの点を考えなければいけません。以下に記載します。
データとなる論文は何を使用するか?
QunaSysは多くの論文を出しています。QunaSysが2023年に出した論文を今回のデータセットとして使用したいと思います。
保存する時のデータセットのデータ構造は?
LangSmithのコンソールで既存のデータからデータセットを作ろうとすると作ろう以下の画像のようになります。

なのでデータセットの構造は以下のようにしました。
{
input : {
question: ~ ,
context: [~ , ~, ~]
},
output : {
answer: ~
}
}LangSmithのデータセットタイプは?
基本タイプはKVで十分です。他のデータセットタイプは既知のファインチューニング・フォーマットにエクスポートするのに便利らしいです。
データセットを作成する(TypeScriptでの実装サンプル)
PaperBotくんはNodejs上でTypescriptで書かれているので、同じRAGシステムを使ってデータセットの作成ができるように、PaperBot上にデータセットを作成できる仕組みを作っています。
コードは使いやすいように改変して掲載します。
import { Client } from 'langsmith';
export type RagasDatasets =
{
question: string;
context: string[];
answer: string;
}[]
const createRagasDataset = (
name: string,
data: RagasDatasets,
): Promise<void> => {
const client = new Client();
// inputsの整形
const inputs = data.map((d) => {
return {
question: d.question,
contexts: d.context,
};
});
// outputsの整形
const outputs = data.map((d) => {
return {
answer: d.answer,
};
});
// データセットの作成
const dataset = await client.createDataset(name, {
description: 'question answering dataset : ' + name,
});
// データを追加
await client.createExamples({
inputs: inputs,
outputs: outputs,
datasetId: dataset.id,
});
return;
}他にやりたいことはLangSmithのドキュメントを見ながら追加で実装してみてください。
あと、この後のTipsでも記載しますが、データセットはRAGのバージョンごとに作成した方がいいので名前の付け方はしっかり考えた方がいいですね!
データセットを作る時のTips
LangSmithがおすすめしている注意点で、今回の点で気をつけた方がいいことを私なりに解釈してRAGに合わせて記載します。
バージョンごとに集計して評価しよう( Use aggregate evals )
基本的にRAGのバージョンごとにまとめて評価できるようにデータセットを作っていくようにしましょう!
そうするとRAGのバージョンごとの評価を比較できるので、何が精度アップに寄与してるかわかります。
なのでRAGのバージョンが変更された時には、データセットは上書きや追加は基本的にはせずに新しくデータセットを作成していきましょう。
ちなみにデータの優位性がわかるのは100~1000+だそうです。
サブセットごとにパフォーマンスを測定しよう(Measure performance on subsets)
データセットにも色々あります。質問は全て同じですか?
違うのであれば、それを一括で評価しても正しく評価できない場合があります。
「このRAGの仕組みだと特定の質問には弱い!」とかも全然あります。
タグとかつけてサブセットごとに評価することで細かくパフォーマンスを測定する方がいいでしょう。
Ragasでデータセットを評価する
次にRagasで実装して評価までしていきましょう。

Ragasを実装する
Ragasの評価パイプラインはGoogleColabで実装していきます。
まずは必要なライブラリをインストールしてください。
%pip install ragas langchain langsmith langchain_core環境変数などの設定します。
import os
import openai
import getpass
from langchain_openai.chat_models import AzureChatOpenAI
from langchain_openai.embeddings import AzureOpenAIEmbeddings
# 環境変数の設定
os.environ["OPENAI_API_KEY"] = getpass.getpass()
openai.api_key = os.environ["OPENAI_API_KEY"]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
os.environ["LANGCHAIN_ENDPOINT"]="https://api.smith.langchain.com"
os.environ["LANGCHAIN_PROJECT"]="your project name"データセットをLangSmithから取得します。
from langsmith import Client
from datasets import Dataset, Sequence,Value,Features
# データセットをLangsmithから取得
client = Client()
examples = list(client.list_examples(dataset_name="your dataset name"))
questions =[]
answers=[]
contexts=[]
for e in examples:
questions.append(e.inputs["question"])
answers.append(e.outputs["answer"])
contexts.append(e.inputs["contexts"])
# Datasetの受け入れるデータ形式を定義
features = Features({
"question":Value("string"),
"answer": Value("string"),
"contexts": Sequence(Value("string")),
})
# データセットをRAGASの入力形式に変換
ds = Dataset.from_dict(
{
"question": questions,
"answer": answers,
"contexts": contexts,
}
, features=features)データセットをRagasで評価します。
この時注意する必要があるのが、Ground Truthをデータセットに含めずにcontext_precisionを使用しようとすると以下のように言われます。
Using 'context_precision' without ground truth will be soon depreciated. Use 'context_utilization' instead
なので、データセットにGround Truthが含まれていない場合はcontext_utilizationを使用しましょう。
from ragas.metrics import context_utilization, answer_relevancy, faithfulness
from ragas import evaluate
# 評価
# context_precision は使わずにcontext_utilizationを使用すること。
result = evaluate(ds, metrics=[context_utilization,
faithfulness, answer_relevancy
],llm=azure_model, embeddings=azure_embeddings)
print(result)評価結果を表形式にして見やすくします。
import pandas as pd
df = pd.DataFrame(list(result.items()), columns=['Metric', 'Score'])
dfRagasでの評価結果
さて、GPT-4 と GPT-3.5-turboでの比較は以下のようになりました。

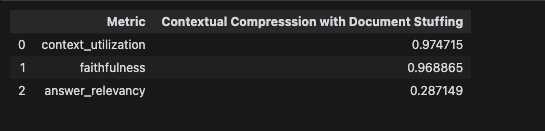
予想通りGPT-4の方がいいですね。
ただどちらにせよAnswer Relevancyの値が低いですね。これに関して考察してみましょう。
Answer RelevancyはLLMが生成した回答がプロンプトに対して適切かどうかを表しています。
現状プロンプトは落合陽一フォーマットの質問ごとにGPTに渡して回答を生成しています。
- どんなもの?+ 論文の関連部分 ⇨ 生成1
- 先行研究と比べてどこが優れているか?+ 論文の関連部分 ⇨ 生成2
- 技術や手法の核心は何か?+ 論文の関連部分 ⇨ 生成3
- どのようにしてその効果を検証したか?+ 論文の関連部分 ⇨ 生成4
- 議論されている点はあるか?+ 論文の関連部分 ⇨ 生成5
- 次に読むべき論文は何か?+ 論文の関連部分 ⇨ 生成6
各質問で生成したものを最後に合体させて落合陽一フォーマットのサマリーを作成しています。
Answer Relevancyでは
どんなものか? ↔️ 論文の関連部分
を比較しているのです。
こう見ると「どんなものか?」というプロンプト自体は情報量がほとんどなく、Answer Relevancyを適切に評価ができていないのではないかと考えられます。
さらに各データセットごとにスコアを出していきますが、最後に各データセットの調和平均を取ってます。調和平均取るとスコアが低いと低い方に引っ張られるので余計スコアが低く表示されて今回のAnswer Relevancyのスコアになったのでは?と考えられます。
評価においてのTips
今回は考慮していませんが、今後RAGの評価をしていくにあたり役に立ちそうなTipsがLangSmithのRecommendationに書かれていたので私なりに解釈し、共有したいと思います。
ドメインに特化した評価器を作ろう(Create domain-specific evaluators)
なんでもかんでもRagasで評価して終了!ではもったいないです。
Ragasは汎用的な評価器と考えて使う方が良いと私は考えています。
できればアプリケーションのドメインに特化した評価器を作る方がより適切な評価器になります。
今回のPaperBotくんもRagasだけの評価で十分とは言い切れません。
なぜなら、「論文を探しやすくなったか」をより良くすることが目標だからです。
この目標掲げた時に、今回のRAGが良くなったかの指標には「サマリーは人が読みやすい形式か」なども本当は含まれていいはずです。
その辺りも今後は考えていきたいと思います。
安定性も測ろう(Measure model stability)
入力がわずか変化するだけでもLLMの回答の生成に影響を与えてしまう可能性があります。生成した回答の内容に大きく影響を与えてしまうのは良い仕組みとは言えないですよね。
だから質問事項をちょっと変えて(類似した質問に言い換える、など)評価することで、安定して回答を生成できるかを測ることができるとより良い評価になりそうです!
そんな時にはRagasのSynthetic Test Data generationの機能が使えそうです。
今回は使っていませんが、よりより評価をするためには使っていきたいですね。
最後に
CRSチームでは、化学の研究活動のサポートに向けて調査・開発を進めて行きます。もしお困りのことがありましたらお気軽に下記までお問い合わせください!