
PCに画像生成AIの環境を構築して、自分で描いた絵を追加学習させてみた

自宅PCに画像生成AIの環境を構築して、さらに自分で描いた絵を追加学習させて画像を生成する、というのをやってみました。

追加学習は成功し、できあがった絵の一つが上になります。かわいい。
やってみようと思ったきっかけはゲーミングPCの自作です。
グラフィックボードをどれにするかスペック等を調べていたら、ローカル環境で画像生成AI「Stable Diffusion」を構築できることを知りました。
(自作ゲーミングPCについては機会があればご紹介したいと思います)
普段のデザイン業務では、AdobeStockなどで素材を探すことがあります。
ただし、目的に沿った素材を探すのが苦手なのと、イメージには合っているのに被写体のポーズが違うバージョンがほしいとか、一定以上の編集が必要な時があります。
似たような経験をした人は結構いるのではないでしょうか。
もしかして自由に画像生成AIが利用できる環境があれば最強なのでは、と。
なお、この記事では自分で描いた絵を学習させて、新しい画像を生成する所までをご紹介します。業務に使えるレベルの画像生成を行う所までには至っておりません。
Stable Diffusionとは
Stable Diffusionとは、テキストや画像を元に高品質な画像を生成する「訓練済みのAIモデル」を搭載した画像生成AIです。オープンソースで誰でも無料で利用できます。
Web上で公開されている環境で動かしたり、ローカル環境で独自に動かしたりもできます。Web上で公開されているサービスは以下のようなものがあるようです。
ただ、こういったサービスは一部が有料だったりします。ローカル環境に構築してしまえばこういった煩わしさも解消できそうです。

さっそく環境構築!
Stable Diffusionやその拡張機能は頻繁にアップデートが行われており、ネット上にある情報もすぐに古くなってしまいます。さらに自分の環境によって動いたり動かなかったりします。
何かを実行しようとすると何かしらのエラーが発生し、エラーメッセージを元に原因と対策を調べて根気よく解決せねばなりません。逆にアップデートが行われず、いざ手順に従ってセットアップしてみたら動かずやり直し、ということもしばしばありました😇
PCのスペックは以下の通りです。グラボのVRAM容量が重要なようです。
CPU:AMD Ryzen 7600
グラボ:GeForce RTX 4060 Ti 16GB
Python、Git、Stable Diffusion Web UI(AUTOMATIC1111)のインストールを行い、WebUIが立ち上がるまで15~20分ほどでした。
セットアップは以下の記事を参考にさせていただきました。
Stable Diffusionを使うためにインストールするPythonのバージョンはある程度決まっているようで、私の環境では「3.10.9」で問題なく動作しています。このあたりは今後変わっていくと思います。
ちなみにあとからPythonのバージョンを変更すると、Stable Diffusionがエラーで動かなくなったりします。もちろん経験済みです。きぃぃぃぃぃ!

セットアップが完了すると、http://127.0.0.1:7860/ でStable Diffusion WebUIが起動します。
動作確認します
適当にプロンプトを入力して画像を生成してみます。「cyber punk Samurai」で試してみました。
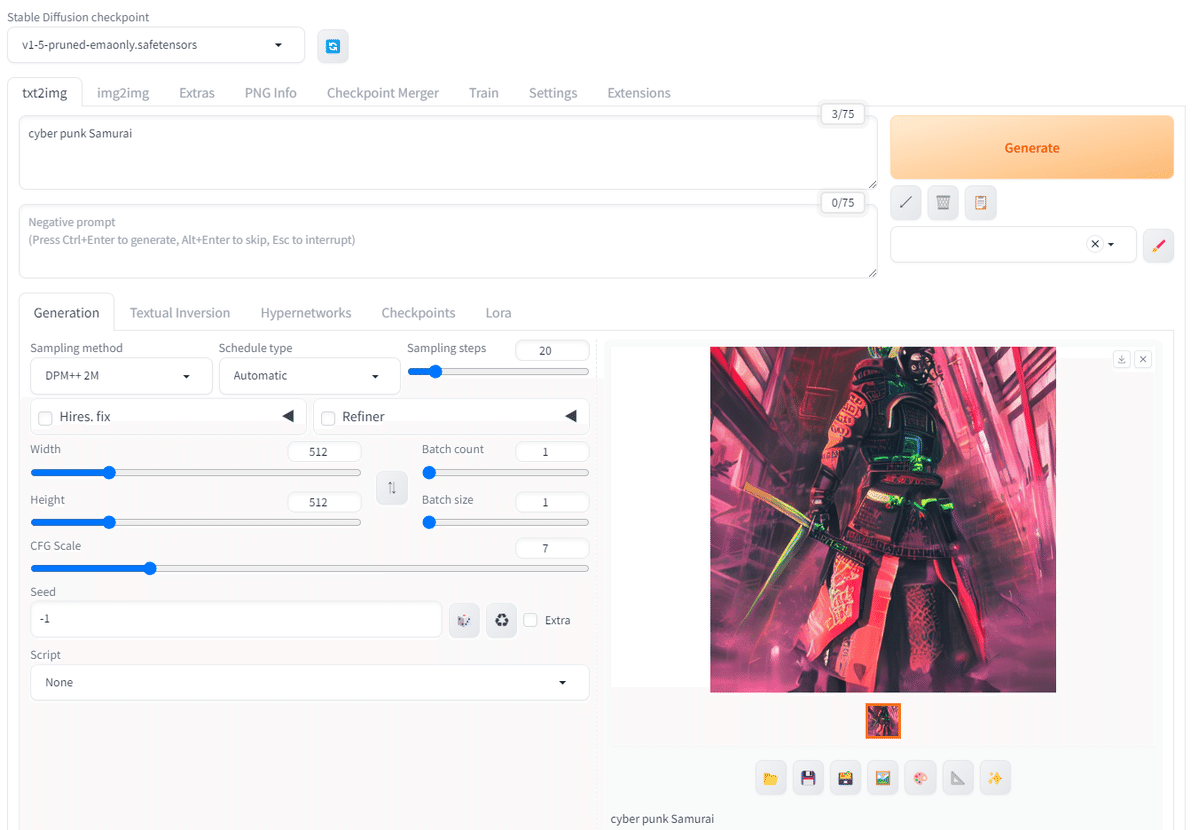
生成した画像は自動的に保存されます。
上記では「txt2img」という、プロンプトを元に画像生成をする機能を使いましたが、他にも以下のような機能が用意されています。
img2img:画像を元に新たな画像を生成する
Inpaint:画像の一部を修正する
PNG Info:画像からプロンプトを抽出する
モデル
さて、Stable Diffusion Web UIでは画像生成AIモデルをもとに画像生成されます。標準のモデルデータ以外にも、配布サイトでモデルデータを入手することができます。
ここで「LoRA」や「Checkpoint」といった単語が出てきます。
「Checkpoint」はモデル本体のことを表します。
「LoRA(Low Rank Adaptation)」は、LLM(大規模言語モデル)や、モデルの追加学習データのことです。
Stable Diffusionでは、オープンソースのモデル=Checkpointにモデルに対して追加学習を行い、新たなモデルを作成することが可能です。
背景のLoRAや髪型や服装、ポーズのLoRAなど、複数のLoRAを適用することができます。生成する画像のクオリティの向上や画風の追加なども可能です。
AIに任せてランダムな画像生成を何度も繰り返して気に入った画像を見つけるのではなく、LoRAを使用して調整をし、目的の画像を生成できるようになるんですね。
CheckpointやLoRAは、CivitaiやHugging Faceなどといったサイトから、ユーザーが作成したデータをダウンロードすることができます。
LoRAやCheckpointについて詳しく知るには下記サイトが参考になりました。
商用利用について
ここで注意点が一つあります。
配布されているCheckpointやLoRAを使った画像は、商用利用できる場合とできない場合があります。基本的にはStable Diffusionで生成した画像は商用利用可能ですが、独自でインストールしたモデルの場合は商用利用が可能かどうか、規約やライセンスを確認する必要があります。
モデルのダウンロード
では今回はCivitaiからモデルをダウンロードして画像生成してみます。
一つ目は「yayoi_mix」です。リアルな女性画像を生成するモデルです。
プロンプトには以下のようなテキストを指定しました。推奨されたテキストをそのまま使っています。日本人女性だとか顔にフォーカスが合っているとかが指定されています。
best quality, face focus, soft light, ultra high res, (photorealistic:1.4), RAW photo,1japanese girl, solo, cute, (pupil, lights in the eyes), (high resolution detail of human skin texture),(middle hair),(portrait)
ネガティブプロンプト(除外したい要素)には例に従って以下を指定しました。
blurry,short shirt, painting,sketches,(worst quality:2),(low quality:2),(normal quality:2),((monochrome)),((grayscale)), missing fingers ,skin spots ,acnes,skin blemishes,loli

2つ目は「Goofball Mix」です。アニメ調の画像を生成するモデルです。
プロンプトは以下を指定しています。
1girl,solo, upper body,looking at viewer, white background, bob cut, short hair, multicolored hair, makeup , parted lips, eyeliner, hoodie
ネガティブプロンプトはこちら。
(worst quality, low quality:1.4), (jpeg artifacts:1.4),greyscale, monochrome, motion blur, emphasis lines, text, title, logo, signature

自分で描いた絵を学習させてみる
ようやく本題です。
ここから自分で描いた絵を学習させて、AIに画像生成してもらいます。AIくん、きみはどこまでやれるの?みたいな調査的な意味合いが今回は強いので、適当にiPadで以下のような絵を用意しました。

追加学習を行ってLoRAファイルを自作するために、Stable Diffusionの拡張機能を利用します。
最初は「sd-webui-train-tools」という拡張機能を使ってみたのですが、何度も何度もエラーが発生し、イーッ!ってなります。そしてできたLoRAは使い物にならないような崩れた画像が…
どうやら「sd-webui-train-tools」は最近あまり更新されてないのだとか。
気を取り直して「Kohya」という拡張機能でLoRAファイルを作ることができました。
以下は参考にさせて頂いたサイト様。まじで助かりました。
追加学習をする際のモデルにはAnyLoRAというモデルを利用しました。
自作LoRAを適用して画像生成!
自分の絵を学習させてできたLoRAを使って、画像を生成してみます。
LoRAを使うにはプロンプトに<lora:〇〇:数字>を指定します。〇〇はLoRAを使用するときに使うトリガーワードです。今回は「yoshiko」という名称でLoRAを作りました。
数字は、どれくらい強くLoRAを反映するかといったウェイト指定になるようです。
以下のようなプロンプトを基本にして、何枚か画像生成してみます。
<lora:yoshiko:0.7>,1girl, solo, looking at viewer, bob cut, short hair, tshirt

なんか自分が描いた絵っぽいものが生成された…!笑
プロンプトにhoodieを指定してパーカーを着せてみたりします。


かわいい~~~😍 服装変更できますね!あとウェイトが同じ0.7でもyoshikoの影響が強く出たり出なかったりしますね。この辺りが境界っぽいんでしょうか。
では、ウェイトの数字を変えて試してみます。
0.0~1.4と、徐々にLoRAの適用を強めていきます。

0.0だと使用したモデルそのものって感じで、yoshiko感は一切ありません。


なんか下膨れっぽくなって、yoshikoの影響が出てきたか…?

・・・!


!!!
0.7から急にyoshikoの主張が強くなってクオリティが笑




1以上は破綻してしまいました😢 こわいです。
次は他の表情やポージングを試してみます。ウェイトは0.5~0.7です。









まとめ
目的にあわせてモデルとLoRAを準備し、プロンプトをうまく指定すれば狙った画像を作れそうです。非常に可能性を感じる結果となりました。
すぐにAdobeStockの代替となり得るかでいうと、準備のほうが大変かつライセンスの件もあり、もう少し時間をかけて作る必要があると感じました。
最後に、なぜトリガーネームが「yoshiko」になったのかについて触れておきます。
当初はヨシダの「yoshi」にしていたのですが、追加学習する過程で指定漏れがあったのか、<lora:yoshi:1>を指定して画像生成したら某兄弟ゲームに出てくる恐竜っぽいものが…

ということでベローン恐竜と誤解されないために、それと女の子の名前っぽくするために「yoshiko」としたのでした。
今回はここまでになります!