総長対話を分析してみた

はじめに
東大で学費が値上げされようとしている。値上げそれ自体の是非だけでなく、その意思決定プロセス、オンラインの「総長対話」のあり方、総長対話後の安田講堂で警察が導入されたことなど、さまざまな論点が入り混じって混沌とした状態となっている。本noteでは、この混沌とした議論から抽出されたテキストデータをワードクラウド・感情分析という手法を用いて分析する。テキストデータの分析を通じて、読者の方に混沌としたテキストの海の概観を提供できれば幸いである。
内容に入っていく前に、筆者自身の立場を明らかにしておこう。筆者は東京大学の修士1年生である。少なくとも現時点において、私自身は学費値上げそれ自体に関しては猛烈な反対を示しているわけではない(現在の財務状況の緊迫性や値上げ分の活用方法、値上げ後の奨学金制度などが不透明であり、賛否の判断を下すのに十分な議論材料が手元にない)。一方で、今回の意思決定プロセスや「総長対話」での総長・副学長の学生に対する冷笑、「総長対話」後の警察の導入などで強い憤りを覚えた。そこで、私なりの抵抗の方法を色々と考えた結果、テキストデータを収集し分析することを決めた。
テキストを単語単位に分解して量的に分析するというとても暴力的な試みであることは分析者自身、自覚している。また、定量的な分析としてのレベルもかなり低いものとなっている。それでも、この学費値上げ・「総長対話」をめぐる議論の大雑把な特徴を捉える助けになると考えている。以下、読み進めるに当たっては、そのことを留意していただきたい。
データの背景
5月中旬に学費値上げ検討が報道されて以降、様々な形で議論や反対運動が学内外で盛り上がってきた。こうした動きの詳細な時系列は、教養学部自治会の特設ページがわかりやすい。
6月21日(金)に「総長対話(総長と授業料および東京大学の経営について考える)」がZoomウェビナー上で開かれ、藤井輝夫総長からの概要説明の後、限られた時間・発言形式ではあるものの学生と総長の間で質疑応答が行われた。
また、このオンライン「総長対話」の後、総長との対面での対話を求める学生が安田講堂前に集まった。しかし、大学によって夜23時ごろ20~30人に及ぶ警官隊が動員され、安田講堂前の集会は一旦終結した。この警察動員をめぐっては、大学自治を脅かす事態として激しい非難が集まっている(詳細は学費値上げ反対緊急アクションのnote参照)。
「総長対話」の分析
まずは、6月21日(金)にZoomウェビナーで行われた「総長対話」を分析していく。分析にはPythonを使用した。分析手順は以下の通りである。
自動文字起こしツールnottaを使って「総長対話」を文字化
誤変換を手作業で修正(ex. 「早朝」→「総長」)
発話内容を総長 / 副学長(司会進行) / 学生に分類
記号、数字などを書き起こしテキストから除外した上で、発言内容をMecabで分かち書き。名詞・動詞・形容詞だけ抜き出す。(ex. 「東京大学で学ぶ学生に必要な教育環境の改善は待ったなしである」 → 「東京大学 / 学ぶ / 学生 / 必要 / 教育 / 環境 / 改善 / 待ったなし」)
WordCloud で各単語の登場頻度を図示
「総長対話」は約2時間にわたってオンラインで行われたが、これは3万5000字分のテキストデータに相当する。今回の分析では、ワードクラウドという表現方法を使っていく。ワードクラウドでは、テキストデータ内の単語の頻度を視覚的に表現する手法である。単語の登場頻度に応じて、単語の大きさと色が変わる。頻繁に使われた単語ほど大きく表示され、同じ大きさの文字の間では青: 最も低頻度の単語、緑: 中程度の頻度の単語、黄色: 最も高頻度の単語を表している。単語が発言の中のどのような文脈で用いられていたかは捨象されてしまうものの、テキスト内での主要なキーワードやテーマを視覚的に把握することができる。
「総長対話」全体
まずは、「総長対話」のテキストデータ全体から見ていこう。「総長対話」全体において、「授業」や「値上げ」「大学」「予算」といった学費値上げに関連するキーワードが多く登場していることがわかる。また、一方で、「皆さん」「お願い」といった呼びかけの表現も多く見られる。

総長の冒頭プレゼンテーション
次に、総長が冒頭で示したプレゼンテーションの発話内容を見ていこう。藤井総長は質疑応答に先立って15分ほど大学の財務状況や奨学金制度について説明した(スライド資料は時代錯誤社ホームページからも確認可能)。前掲のワードクラウドと異なる語彙として例えば「改善」が挙げられる。学費値上げの必要性を訴える文脈において、"本学の環境や教育内容をどのように改善していくべきか"、"それから前期課程の基礎教育においても少人数の演習にするなどですね、改善すべきところ多いんですが"のような発言が多く見られた。また、「皆さん」という聞き手の学生への呼びかけ(ex. "その方法についてはぜひこれも学生の皆さんとも一緒に考えていきたいことだと考えています")も目立つ。

藤井総長の発言
ここから先は「総長対話」のテキストデータを①藤井総長、②河村副学長(司会進行)、③学生という発言者別で分析していく。まずは、藤井総長の発言のテキストデータを見ていこう。
ここで目立つのは、「検討」である。書き起こした限りだと、総長の口からは合計24回の「検討」が登場した。以下の引用部分が象徴的であろう。
その聞いた段階で相当に多くのご意見が出たということも踏まえてですね、よりしっかりと検討しようということで、現在に至っているということでありまして、その一環で当然あの、学生の皆さんの声も聞いてから、この現在検討中の案を今日はお示ししているわけですけども、これをさらに検討を進めていこうということでございまして、…
「検討使」という言葉も想起させるような発言である。「検討」という言葉を度々口にした場面で、パブリックビューイングの会場では「国会と同じじゃないか!」というヤジも飛んでいた。

学生の発言
発言希望者の中からランダムに選ばれた学生14人に質問・発言の機会が与えられた。「家庭」「親」「お金」「基準」「申請」といった学費負担・授業料免除関連の単語が多く登場している。

河村副学長(司会進行)の発言
今回の総長対話は河村知彦副学長が以下のような流れで進行していた。
1. 発言を希望する学生がZoom機能で「挙手」
2. 挙手順を使ってランダムに学部生・大学院生・全体から5名ずつ発言者を抽出
3. 副学長が発言者を指名し、発言終了時間が来ると副学長が"時間の関係上次に行きたいと思います"というように発言を打ち切る
そのため、副学長の発言内容にはその進行方針に沿った「機械的な」発言が目立っている(それがオンライン形式の「対話」である)。

ここまで、Zoomウェビナーで行われた「総長対話」の書き起こしテキストデータを分析してきた。ワードクラウドで各発言者の特徴が大まかにわかると思う。
ツイート分析
さて、次は「総長対話」そのものではなく、それをめぐるTwitter (X)上の議論をテキストデータとして分析していく。今回は以下の手順で分析を行った。
Twitter APIに登録
"総長対話"という言葉が含まれる全ツイート(リツイート含む)をtweepyで収集
絵文字や記号、数字などをツイートのテキストから除外した上で、投稿内容をMecabで分かち書き。名詞・動詞・形容詞だけ抜き出す。(ex. 「学生が総長に意見を述べる」 → 「学生 / 総長 / 意見 / 述べる)
WordCloud で各単語の登場頻度を図示
PyTorchを使ってツイートの原テキストを感情分析(sentiment analysis)。学習済みの日本語BERTモデルを使用。
テクストデータの分析に入る前に、そもそものツイート(ポスト、投稿)の動態を確認しておこう。Twitter APIの仕様上、1週間分のツイートしか取得することができない。そのため、今回の分析に使用するのは「総長対話」2日前の6月19日(水)から「総長対話」5日後の6月26日(水)の7日分のツイートである。この期間に「総長対話」を含むツイートは合計18143件あった。リツイートを除くと836件である。「総長対話」が開催された6月21日の夕方から翌日にかけて、投稿が集中している。
投稿数

また、「学費値上げ反対緊急アクション」の呼びかけに応じて、#総長対話というハッシュタグをつけたツイートが「総長対話」前後に多く見られた。
【総長対話開催中】#総長対話 でみなさんの実況をお願いします。RTします!#学費を上げるな
— 学費値上げ反対緊急アクション (@no_raise_ut) June 21, 2024

ワードクラウド
「総長対話」書き起こしテキストデータの時と同様に、「総長対話」に関するツイートのテキストデータをワードクラウドで表現していく。頻繁に使われた単語ほど大きく表示され、同じ大きさの文字の間では青: 最も低頻度の単語、緑: 中程度の頻度の単語、黄色: 最も高頻度の単語を表している。
まずは、「総長対話」を含む全てのツイートから見ていこう。「授業」「値上げ」「反対」といった授業料値上げそのものに関するツイートのほか、「安田講堂」「広場」「警察」「自治」「デモ」といった「総長対話」の後に起きた警察介入に関する単語も多く登場している。

ハッシュタグ「#総長対話」が含まれるツイートは、それが「総長対話」の実況として使われていたこともあり、"検討"など「総長対話」の内容と関連したキーワードが多く登場している。

また、「総長対話」を含むツイートの中で「警察」も含むものだけを取り上げると、次のような結果になる。「大学自治」「大学自ら」「蔑ろ」といった大学自治に関するキーワードが多く登場している。

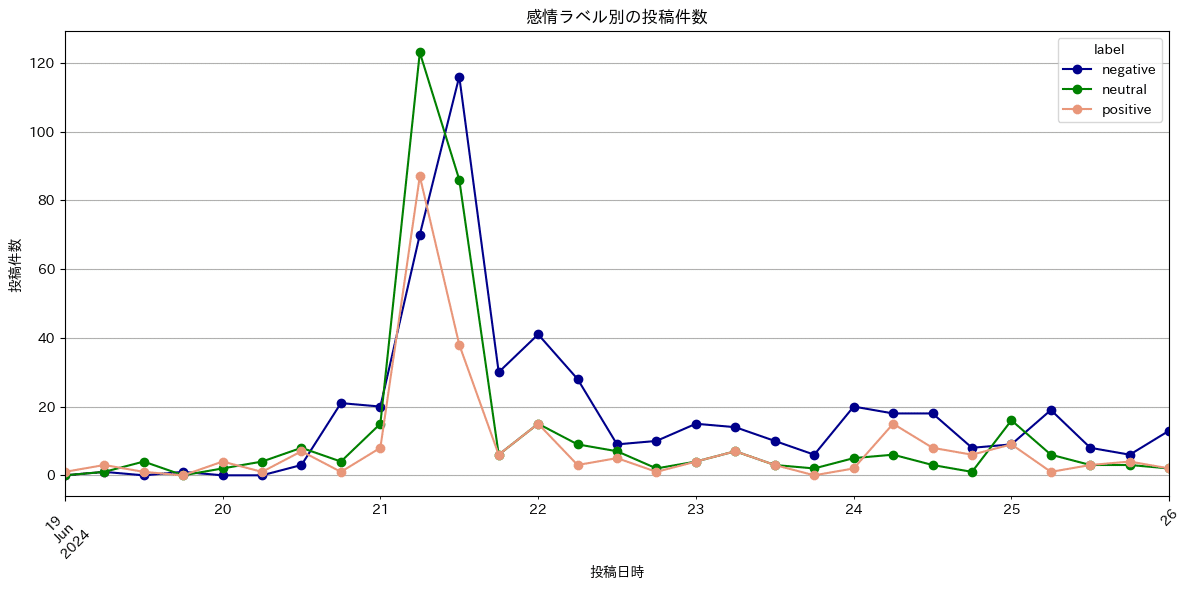
(おまけ) 感情分析
最後に感情分析 (sentiment analysis)の結果を紹介する。結論から言うと、筆者の技能不足もあり、この感情分析はあまり有用ではなかった。
感情分析は、テキストデータに含まれる単語からそのテキストが持つ"感情"を自動的に識別し、分類する手法である。感情分析で分類される"感情"は一般的に「ポジティブ」、「ネガティブ」、「ニュートラル」の3つである。今回はこのラベルに加えて、ポジティブなら1、ニュートラルなら0、ネガティブなら-1付近の値を取るようなスコアも算定した。
以下の例文だと、我々人間的な直感と整合的な結果が得られる。
・「今日は美味しい寿司を食べたから、幸せな日だ」… ポジティブ(0.9986)
・「朝から雨で最悪。テンション下がる」 … ネガティブ(-0.9563)
・「本郷三丁目駅に行くには、丸の内線か大江戸線を使う」 … ニュートラル(0.0456)
一方で、「総長対話」に関連するツイートにおいては、この分類があまり有用ではなかった。例えば、以下のようなツイートは適切にネガティブ分類された。
東大生と藤井輝夫総長が話し合う『総長対話』 本郷キャンパス安田講堂前広場の授業料値上げ反対デモに警察が介入「大学自らが大学の自治を蔑ろにしてどうすんの?
しかし、ポジティブ分類されたツイートは以下のような皮肉ツイートであった。
みんな総長対話見とるん?大人気やん
総長対話は交渉の場ではありません!! そうだ!そうだ!!総長最高!!!
みなさん総長対話をご覧になりましたか。総長陛下の、顔を見合わせて笑みをこぼすような傲岸不そ…上品な御尊顔と、台本どお…心からの真摯な説明で、学費値上げに対して素晴らしい施策だと納得されたことでしょう‼️‼️ 学費値上げは神 総長最高 以下のアンケートはもちろん一択ですよ‼️ #総長対話
今回用いた機械学習ベースでの感情分析は、単語に着目したクラス分け・スコアリングである。そのため、人間であれば識別できるようなアイロニー(単語の表面上の意味とは逆の意味が裏に込められた表現)を汲み取れない"KYな"分類になってしまった。
一応、このラベリング・スコアリングのもとでの分析結果を載せておく。ただし、この感情ラベリング・スコアリングがあまり信頼に足る精度ではないことに留意してほしい。


まとめ
このnoteでは、筆者が独自に作成した「総長対話」の文字起こしテキストデータ、「総長対話」に関するツイートのテキストデータを分析してきた。その中で、学費値上げの議論におけるキーワードが明らかになった上、「検討」のように今回の議論の進め方を代表するような表現も改めて浮き彫りになった。
今回のテキストデータ分析では、「総長対話」およびTwitter上の発言をテキストとして扱い、そのテキスト(テクスト)を単語という最小単位に粉砕した。分析対象となったテキストは当然、単語の単なる羅列ではない。本来のテクストにおいては、単語同士が結びつき、そして言外にある知識も参照しながら意味が生まれる。しかし、今回の分析ではそうしたものを全て捨象し、テクストを単語の羅列として扱うことで定量的な表現・分析を試みた。こうした試みは、テクストの解釈に入っていく前段階の「記述統計」として有用であると考える。このnoteが読者が学費値上げに関する議論の全体像を大雑把に把握する手助けになっていれば幸いである。
この記事が気に入ったらサポートをしてみませんか?