
ディープラーニングを用いて、動画からBVH形式のモーションファイル生成を試みる

ポリリズムのR&D部門のNです。今回は、「mp4などの動画データから人間の骨格およびモーションの検出を行い、そのモーションをBVH化 -> Unity上でHumanoidに適用する」といったことを試した際の話を書ければと思います。なお、BVHとは、Biovision社が提唱したモーションキャプチャデータのファイルフォーマットのことです。BVHはBlenderなどのツールで利用可能です。
モーション検出とディープラーニング
骨格やモーションの検出はモーショントラッキングやそれらに類するハードウェアを用いたり、opencvで荒く処理するなどが一般的でしたが、ディープラーニングの登場によりハード的なモーショントラッカーを利用せずとも非常に精度の高いモーション検出ができるようになってきました。特に openpose はディープラーニングを用いたモーション検出のタスクでは認知がとても高いものとなっています。

また、最近社名をMetaに改名したFacebookもこの領域で張っており、オブジェクトのセグメンテーションや検出、動物や人間の骨格検出などの様々なタスクを解けるツール群である detectron2 を開発しています。おそらくは、Metaがこれから開発するようなメタバース上のアプリケーションなどにもdetectron2を利用したものが出てくる(あるいはすでに利用している)と予想されます。
2次元の骨格から3次元の骨格を推定する
OpenPoseのような骨格検出器は通常、画像座標上の関節の座標を平面的に検出します。すなわち、(x, y)のような2次元のベクトル群として、各関節の集合が得られます。このため、動画を入力した場合は、パラパラ漫画のように二次元的な骨格の推移は作れますが、3Dモデルに適用しても、奥行きのあるモーションとはなりません。(ユークリッド空間を考えれば、y軸方向の動きが無い)
そこで、二次元の骨格から三次元の骨格を推定するというタスクを用いることで、3Dモデルに適用可能な骨格データを生成しようというのが今回試したアプローチです。次はそのような手法に関する論文で、2D -> 3D骨格推定のために今回利用したツールであるvideo2bvhの基礎的な理論を提供するものです。
関連論文紹介
A simple yet effective baseline for 3d human pose estimation
3D human pose estimation in video with temporal convolutions and semi-supervised training
1に関しては、形式的には予測値を最小化する関数$${f^*: \mathbb{R}^{2n} \rightarrow \mathbb{R}^{3n}}$$を次のように定めます。(nは関節数、二次元上の関節の座標$${\bm{x}}$$を$${\mathbb{R}^{2n}}$$の元、三次元上の関節の座標$${\bm{y}}$$を$${\mathbb{R}^{3n}}$$の元とする。)
$$
f^* = \underset{f}{\rm{min}} \hspace{1pt} \frac{1}{N} \hspace{1pt} L(f(\bm{x}_i) - \bm{y}_i)
$$
ここで、$${f^*}$$をニューラルネットワークとして解くことを考えます。$${f^*}$$は次のようなアーキテクチャとなっています。
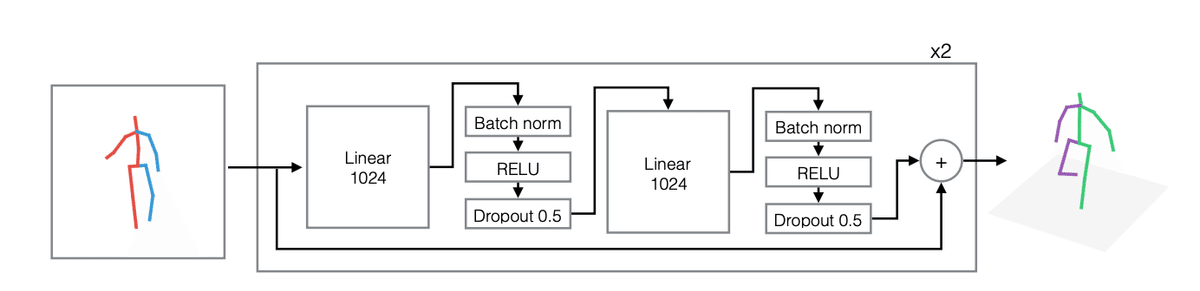
A simple yet effective baseline for 3d human pose estimation より
シンプルなネットワークですが、類似手法の中でもロスがかなり低いことが論文内で挙げられています。学習用のデータセットはh36mです。
一方、1の手法が1フレームからの2D ->3D変換であったのに対し、2の手法では複数フレームを用いた関節の軌跡に着目した3Dの姿勢を推定するモデルを提供しています。また、LSTMを用いた従来手法から時間方向にDilated Convolutionを用いることで精度改善を行ったのと、3Dラベルが得られないような環境を考慮し、3Dラベル付きのデータとラベルなしのデータを用いた半教師学習を用いる点が特徴です。

上側は、3Dラベルがある場合で、3D姿勢およびグローバルポジションを推定し、実測値とのlossを計算する教師あり学習となっています。
下側は教師なし学習で、上側と同様のモデルで3Dの姿勢およびグローバルポジションを推定します。(精度低下があるため、重みの共有はしないそう)このとき、3Dラベルの平均的な骨の長さを用いたBone length L2 lossを用いて、推定される3Dの姿勢に成約をかけています。そして、lossとして、推定した3D姿勢とグローバルポジションを用いて2D姿勢を再投影し、元の2D姿勢とのMPJPE lossを使用します。
MPJPE lossは次のような関数です。($${\bm{x}}$$と$${\bm{y}}$$は比較する姿勢の各関節のベクトルで、$${\bm{y}_z}$$は深度。ノルムは$${L^2}$$)
$$
E = \frac{1}{\bm{y}_z} \| f(\bm{x}) - \bm{y} \|
$$
video2bvh
今回利用したライブラリです。以下の機能が実装されています。
OpenPoseによる動画からの2次元モーション検出
上記手法1, 2による2次元モーション -> 3次元モーション変換
3次元モーションデータをもとにBVHを生成
※ video2bvhはLinuxで動作することを前提に作られているようで、Windowsで動かすまでにコード修正がそれなりに必要でした。また、私の環境では、Mac(CPU)で実行した場合とwindowsのCUDA環境(RTX-2080Ti)とで100倍近く実行時間に差がありました。
video2bvhのデモ

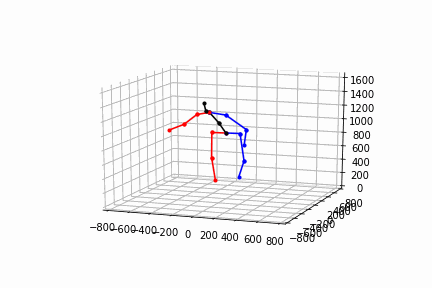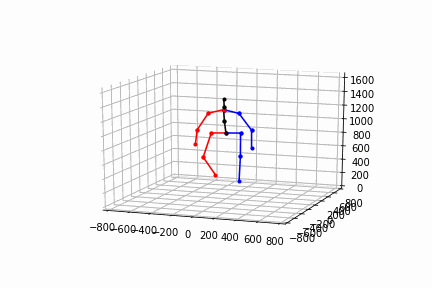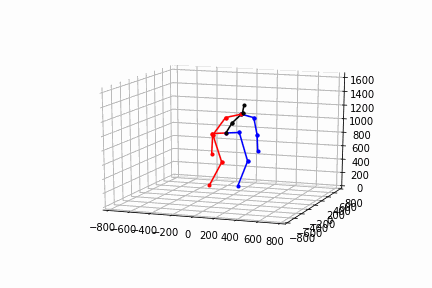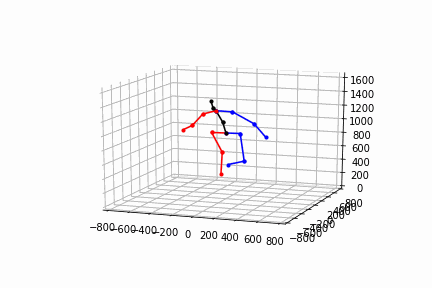
video2bvhを試す
用意した3Dモデル
3Dモデルには、VRoid で自作したものを利用しました。VRoidをUnityに配置するまでには、Unityプラグインの導入など一手間かかります。ネット上に詳しい工程を解説した記事がたくさんありますので、ここでは割愛させていただきます。興味のある方は「Unity Vroid」などのキーワードで検索してみてください。

実演
次の動画をvideo2bvhの入力として、生成したBVHを3Dモデルに適用するまでの実演を行います。利用した動画: https://www.pexels.com/ja-jp/video/6003988/
video2bvhでは、デモ用のnotebookがあるため、お手元の環境に合わせて変更を行えばBVH生成までのタスクを一括で実行可能です。
https://github.com/KevinLTT/video2bvh/blob/master/demo.ipynb
video2bvhから生成したBVHファイル

ダンスのモーションが生成され、ブレンダーで再生できています。ただし、生成後のBVHは入力動画によってはカクツキがおき、スムーズなモーションとならないことがありました。そのため、BVH内のすべての座標データに対して移動平均によるスムージングを行うことでカクツキを低減する工夫をしています。
Unity上のVRoidに適用

実際の動画よりもコンパクトな動きではありますが、自動生成したモーションデータを3Dモデルに適用することができました。Vroidにモーションを適用するまでの工程は次のものとなります。
BVHをブレンダーに配置し.blenderファイルとして保存
.blenderファイルをUnityのAsset配下にD&Dし、RigをHumanoidに変更
Animator Controllerを作成し、VroidのAnimatorに適用
3で作成したAnimator Controllerに2のモーションを適用
最後に
今回は、動画から検出したモーションをBVH化し、3Dモデルに適用するということに挑戦してみました。まずは、pythonの実装が提供されている比較的古い手法を試してみたため、最新手法というわけではないですが、可能性を感じさせるような結果となりました。今後は類似する最新手法などもリサーチし、実験結果をこのブログに投稿できればなと思っています。