
Speaker Diazrization From Nemo | 第一回

この記事を書いたのは 山岡さん.
0. この記事から理解できることは?
Speaker Diarizationとはどのような技術か
Speaker Diarizationの評価基準
Nemoの提供しているモデルがどのようなモデルか
2者間の音声データにおける精度
1. Speaker Diarizationとは
Spekaer Diarizationとはいつだれが話したかを推定する問題です。
つまり、図1に示してある通り、入力は音声データの信号で、出力が音声区間のタイムスタンプとその区間における話者IDとなります。

この技術は、Web会議が増え、その結果、議事録作成の自動化や非言語的な解析の需要が高まっていることもあり、応用技術でも今後さらに研究が進むテーマの一つです。
この技術は、音楽の分野でも応用されており、音楽の分野では、いつどの楽器が演奏されているのかを推定する問題として置き換えることが出来ます。
更に発展した研究では、オーケストラなど同じの楽器を演奏している場合に同じ楽器でも演奏者ごとに予測するラベルを分けれないかの研究なども行われえています。
音声、音楽どちらにしても1区間の中で発話している人や演奏している人が一人であれば高い精度はほとんどの場合、保証されています。
ただ、現実問題ではその仮定を置くことが出来る状況だけではないので、複数人が同時に話している、演奏している状況では技術的な課題があります。
2. Speaker Diarizationの評価基準とは
先ほど「高い精度」という言葉を用いたのですが、Speaker Diarizationではどのような基準を用いて良し悪しを測っているのでしょうか?
SpeakerDiarizationではDER(Diarization Error Rate)が良く用いられている。
DERは以下の計算式で計算可能される。
$${DER = {\frac{FA+MD+Confusion}{ToTal} -(1)}}$$
FA(false alarm) : 発話していないのに発話と推定された時間
MD(missed detection) : 発話したのに発話がないと推定された時間
Confusion : 話者が異なって推定された時間
Total : 発話と推定された全部の時間
DERには様々な情報が一つにまとまっているため、FA、MD、Confusionのどの部分の間違いが多かったかにも注目して議論していくことが大事な指標である。
2022年の国際学会で発表されたものではDERが6.6%の論文もあれば、35.79%と報告した論文も存在した。このことからも、扱う音声によって精度にかなりの差があることが分かる。
3. Nemoが提供しているモデル
図2がNemoの提供しているSpekaer Diarizationのモデル図です。

Nemoの提供しているモデルの流れ
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
【モデルの流れ】
MarbleNetを用いて音声区間検出を行う。
検出された音声区間に対して、TitaNet-Lを用いてSpeaker Diarizationに必要な情報を抽出する
クラスタリングを行う(Overlap非対応)
MSDDによってクラスタリングを行う(Overlap対応)
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
MarbleNetは、QuartzNetを基にしており、End-to-Endのモデルです。
(MarbleNetのモデル図は図3を参照)

論文によると、当時最先端のモデルと比較して約12%のパラメーター数で同等の性能を達成したと報告されています。
モデルが軽度で高性能なことはプロダクトの観点からみるととても助かりますね!
MarbleNetの元の論文はこちらから読むことができます。
TitaNet-Lは、ContextNet を基にしており、モデルは図4を参照
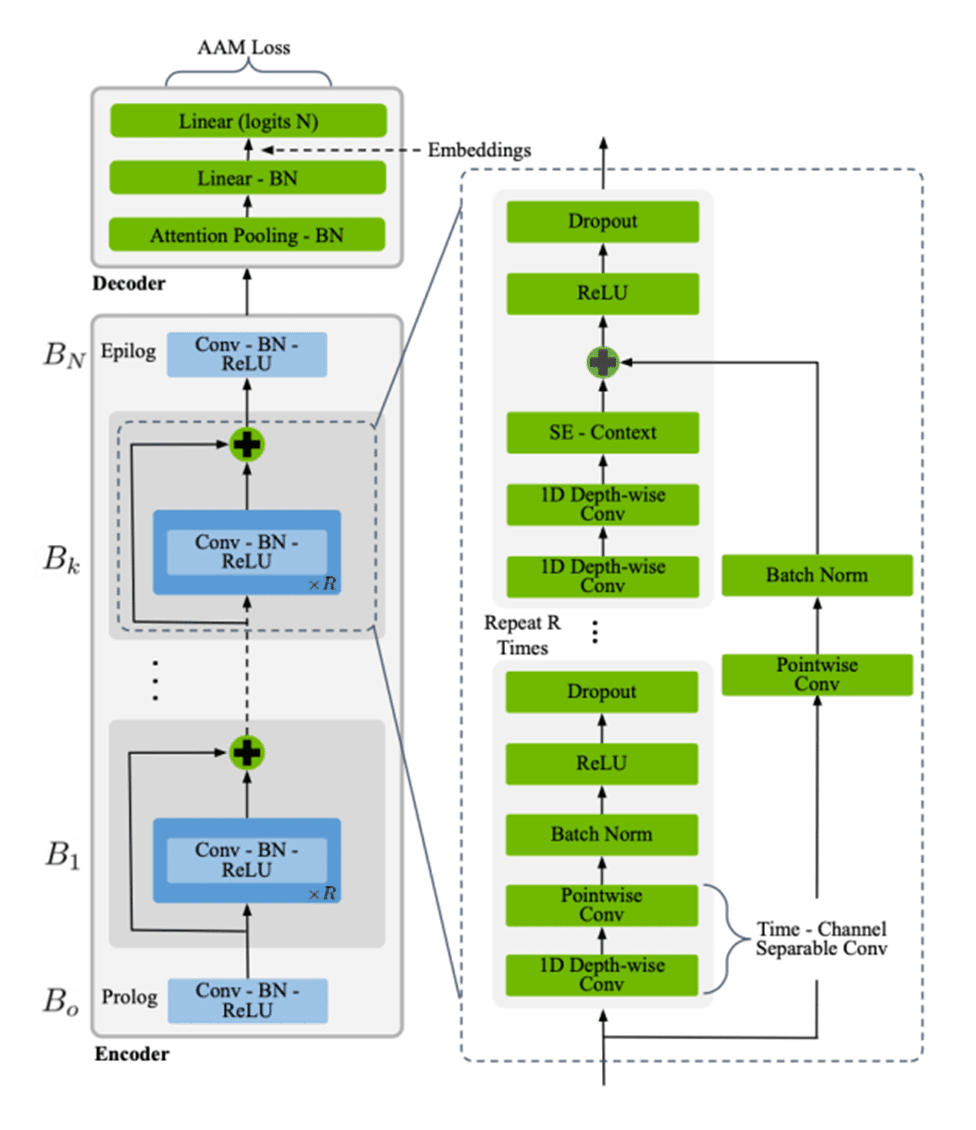
TitaNetには、パラメータ数の異なる3つのモデル(TitaNet-S、TitaNetM-、TitaNet-L)が用意されています。
パラメータ数は、TitaNet-Sを基準にすると、TitaNet-MはSの2倍のパラメータ数。
TitaNet-LはMの2倍(=Sの4倍)になります。
TitaNet-Lの元論文はこちらから読むことが出来ます。
4. 簡易実験
【実験に用いた音声の情報】
発話者:男性2名
合計発話時間:16分
Overlap:10.66%
周波数:48K
チャンネル数:1(モノラル)
VAD結果

VADの結果を見ると、短すぎる発話交替点の検出は難しいが、おおむねきれいに発話区間を取れている。
話者が一人のだけの音声のDER
total: 959.22[s]
miss: 106.9[s]
false alarm 326.6[s]
confusion: 9.31[s]
DER: 46.16%
オーバーラップの音声(1区間に話者が2人以上いる音声)のDER
total: 102.3[s]
miss: 102.3[s]
false alarm: 0[s]
confusion: 0[s]]
DER only for overlap: 100%
DERの値は良いわけではないのだが、false alarmの値が間違いの7割以上を占めておりこれはアノテーションを細かくしすぎたことが原因かと思われる。
一方で、1区間に話者が2人以上いる音声ではうまく検出できなかった。
人数を変えて実験も行ったので、その結果詳しい間違い分析は、次回の記事で紹介します。
第二回に続く