
PubMedの近接演算はストップワードを含んでしまう

2022年からPubMedで近接演算子が使えるようになって2年も経つのですが今更知った衝撃の事実。
個人的には待望の機能で、PubMedを使う場合活用していました。特にフレーズインデックスエラーの場合。
うっかりものの私が気づいたわけではなく、Tracy さん(海外のライブラリアン)がSNSでおっしゃていたのを拝読して、へ??と思い、検証してみました。
最近私の周りでホットなSDOHをPubMedで、近接演算子を使って検索したのが以下の画面です。
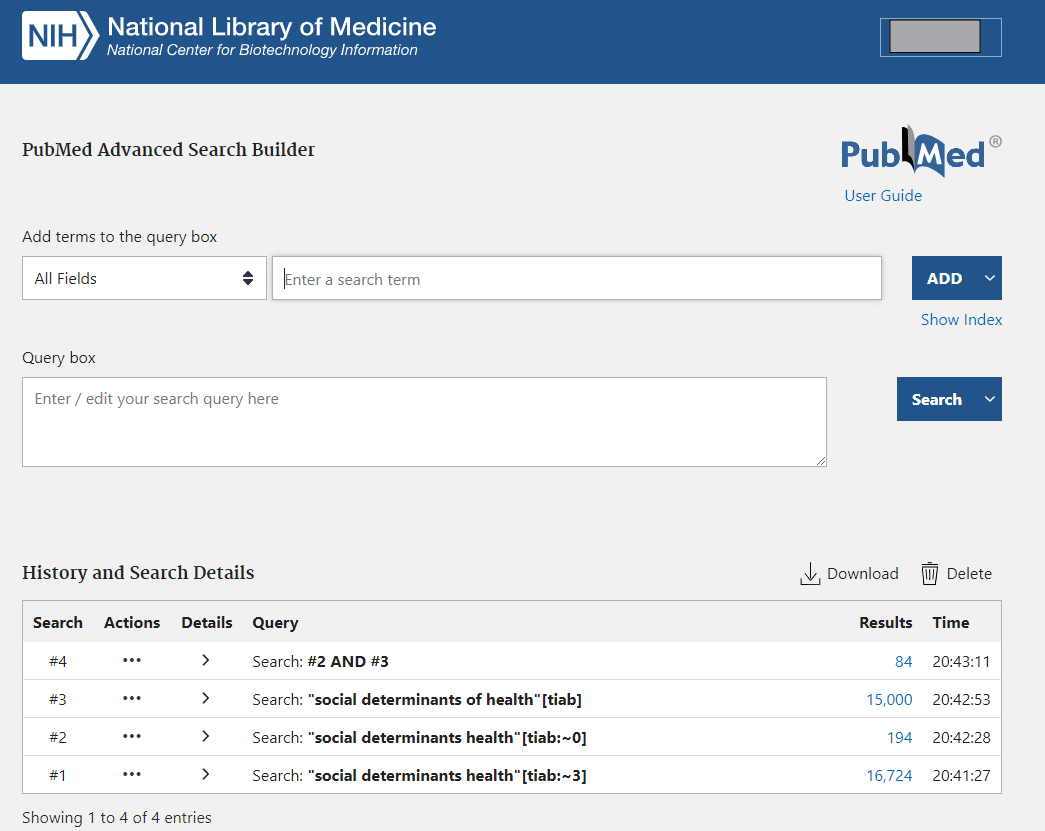
PubMedでの近接演算子については過去の記事またはHelpをご覧ください
#1ではsocialとdeterminantsとhealthの3つの単語が(語順は問わず)3語以内に近接して論題または抄録内で使用されている文献を検索しています。
16,724件がヒット
#2では0語以内、つまりフレーズとして論題または抄録内で使用されている文献を検索しています(語順は問わず)。
194件がヒット
#3では、"social determinants of health"のフレーズ(語順はこの通り)として論題または抄録内で使用されている文献を検索しています。
15,000件がヒット
(近接演算子をどのくらいの近接から始めるかも先日medlibsな方々のコミュニケーションから学び、気になるところですが、)
PubMedを使い慣れた方はご存じの通り、PubMedではaとかofやtheといったストップワードにリストされている単語(冠詞や接続詞など)を切り捨てて検索が行われます。
ですので、この近接演算検索の時も"the social determinants of health"のtheやofは切り捨てられた検索が行われるものと、Tracy さんの情報を見るまでは思ってNを検討していました。
#2の検索と#3の検索の重複分を確認したところ、一見"social determinants of health"も拾ってヒットしているように見えなくもないですが、実際には赤線を引いた箇所の「health. Social determinants」を拾ってヒットしていると気づきました。(句読点は切り捨ててますね)

私が「:~0」近接0を指定する場合、フレーズインデックスにないよ。のエラーで(そのエラーを回避すべく)、0を指定していたので、
このままだと本来は拾うべき"social determinants of health"を落としてしまうということに気づきました。
PubMedの近接演算子、著者所属フィールドも指定可能になったので、著者所属の時も○○of▲▲ とかthe ××みたいな機関を検索するときは、このことも念頭に置く必要がありそうです。
近接の幅を拡げると当然ノイズも増えるので、精度と感度のバランス。を考えつつ。
Helpを見たら、なんとちゃんと書いてありました。笑

上述のようにストップワードだけではなく、論理演算子もカウントしてしまうようなので、合せて気をつけます。
人は自分の気になる文しか読まないことを改めて実感しつつ、Tracyさんに感謝を申し上げます。