
Web of Science Core CollectionとPubMedデータの重複チェック [Tips]

SRではより網羅的な情報収集を目的に複数のデータベースでの検索を行います。その後,各データベースで得られた文献が集合の中で重複がないかをチェックする流れになります。

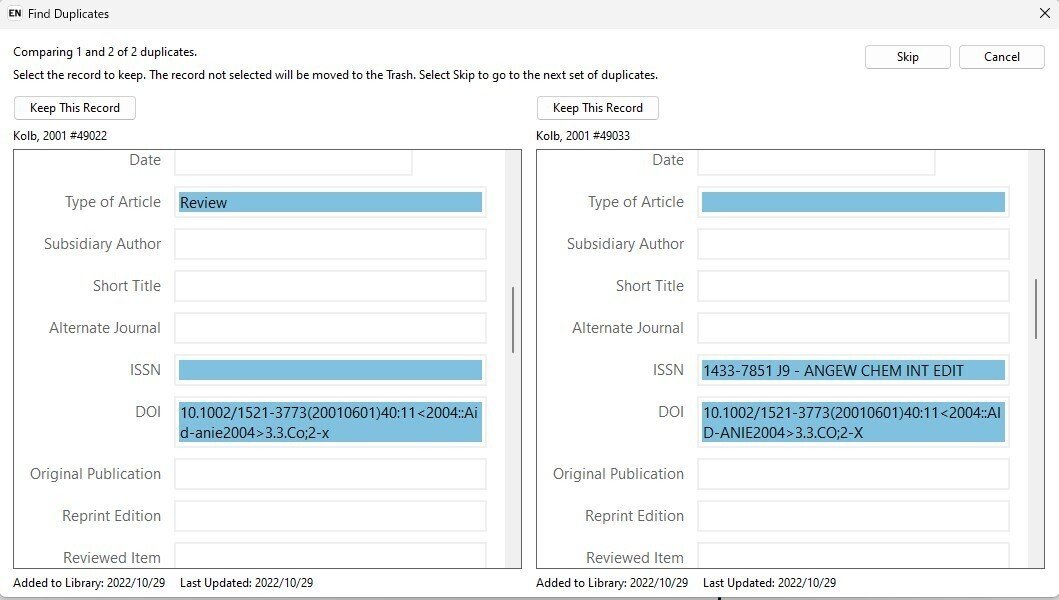
私は普段重複チェックにEndNote デスクトップ版を使用しています。
重複と判断されて挙がってきたそれぞれの書誌をなるべく簡単に見分けるために(私見です)なるべく桁が少ない項目を見比べるのがいいと思い,どちらもPMIDがある場合は(Accession Numberに取り込まれる)PMIDをキーに判断をしています。
ない場合DOIを見ています。(DOIがない書誌の場合は,巻号ページなども見比べるなどの順で判断しています)
検索対象にWeb of Science Core Collection(以下,WoS)も含める場合,WoSのデフォルト設定でエクスポートしEndNoteに取り込むとWoS Accession NumberがユニークIDとして取り込まれてしまいます。

ここでWoSからもPMIDをエクスポートさせてEndNoteに取り込む方法をご紹介します。
WoSのエクスポート機能からRIS形式を選び,Record content設定でcustom selectionを選びます

カスタム画面でAccession Numberのチェックを外し,PubMed IDにチェックを入れ[Save selections]をクリックします(Accession Numberにチェックが入っているとWoS Accession Numberが優先される仕様だとのことで,PMIDはエクスポートされないので注意が必要です)

この状態でRISファイル形式でエクスポートすると,デフォルトではWoS Accession Numberがエクスポートされて取り込まれていたAccession NumberフィールドにPMIDがセットされるようになります。

これでどちらの書誌にもPMIDが含まれるようになりました。
ちょっとした手間ですが,DBからのエクスポート時は一括で出力項目ができる一方で,重複判断の書誌画面は一つ一つの書誌を確認する必要があるのでエクスポートの際工夫すると,より便利に使うことができます。
[参考メモ]

余談ですが,SRの報告時には重複チェックの方法とその際使用したツールについても本文中で報告することが推奨されています。
PRISMA-S 項目 16. 重複排除
複数の DB 検索やその他の情報源から資料の重複を排除するために用いたプロセスとソフトウェアを記載する。
https://prisma-statement.org/documents/PRISMA-S%20in%20Japanese.pdf