ダイエットとStataの使い方 4

停滞期が続いてはいますが、少しずつ体重が落ちています。
今回は、進捗報告も兼ねてStataのコマンドを中心に解説します。
今回のポイント
・棒グラフの後ろに影をつける方法の別解
・散布図と近似線を重ねる方法
・リードとラグの取り方
まず棒グラフの後ろに影をつける方法ですが、この記事で解説したようにareaを使うのが最も簡単です。
しかし、以前の私はこの論文を参考にしてもう少し面倒なことをしていました。忙しい人はマネしないことを推奨します。一応コードを書いておくと
gen inter2=102
local barcell2 inter2 date /*
*/ if (date>= date("11/29/2021","MDY",.) & date<= date("12/1/2021","MDY",.)) /*
*/ | date>= date("1/8/2022","MDY",.) , bcolor(gs14) base(90) /*
*/ //barcell2 というlocalなマクロを作成
label var inter2 "食事管理"
label var weight "体重"
label var date "日付"
twoway (bar `barcell2') (tsline weight if date>= date("9/1/2021","MDY",.) , /*
*/ cmissing(n)) です。細かな解説は省略しますが、棒グラフを大量に書いています。そして、色と透明度を調整することでデフォルトの青い棒グラフじゃなくしています。
上の論文だとareaは2つ以上の分かれた範囲を塗るのに適していないと言っていますが、以前の記事で紹介したcmissing(n)オプションで解決するのでareaでやったほうがいいです。
続いて、散布図と近似直線を重ねる方法ですが、すでに使用しているtwowayを使用します。twoway (GRAPH_1) (GRAPH_2)もしくはtwoway GRAPH1 ||GRAPH_2 のように書くとできます。
散布図はscatterで近似線はlfitなので、下のコードです。食事管理以降のデータを使用するため2022年のもののみ表示しています。
twoway scatter bmi date if date>= date("1/1/2022","MDY",.) || lfit bmi date if date>= date("1/1/2022","MDY",.)その結果がこちらです。
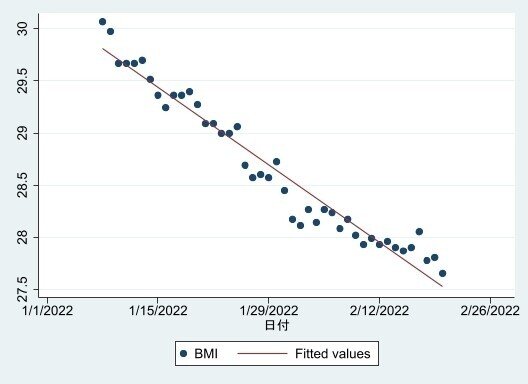
さて、ダイエットは最初は減るけど途中からは減らなくなるということなので変化率を見るために対数を取ります。細かな議論は省略します。
対数を取ったグラフがこれです。
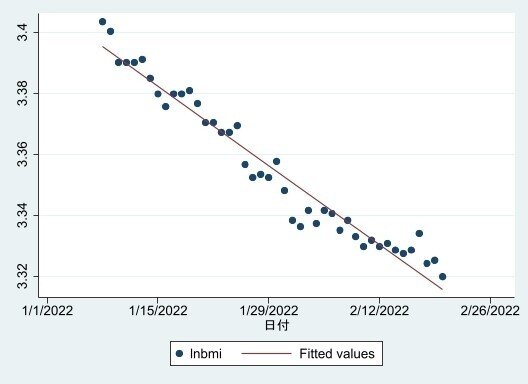
対数を取った場合と取らなかった場合を右辺にタイムトレンドを使用した単回帰の結果で比較します。
dateは、1960年の正月からの日数であることを思い出してください。
. qui reg bmi date if date>= date("1/1/2022","MDY",.)
. est sto wout_log
. qui reg lnbmi date if date>= date("1/1/2022","MDY",.)
. est sto w_log
. esttab wout_log w_log, se r2 star(* .1 ** .05 *** .01)
--------------------------------------------
(1) (2)
bmi lnbmi
--------------------------------------------
date -0.0532*** -0.00185***
(0.00187) (0.0000637)
_cons 1234.0*** 45.29***
(42.43) (1.444)
--------------------------------------------
N 44 44
R-sq 0.951 0.953
--------------------------------------------
Standard errors in parentheses
* p<.1, ** p<.05, *** p<.01ここで、quiはquietlyの省略で結果を表示させないことを意味します。
そして、est stoは分析結果を保存してesttabで結果をまとめています。
est sto 保存したい名前で結果を保存して、結果をまとめて票にするためにesttab 保存した名前1 保存した名前2 のように書きます。
オプションは、標準誤差とR-squaredを表示するためのse r2と有意水準の星の数を調整するものを書いています。
結果は、サンプルサイズが小さいこともあり決定係数に大きな違いはありません。(決定係数でモデルのフィットの良さを判断すると怒る人はいますが、今回はその話はおいておきます。)
ちなみに、quiを前につけないとこのようになります。
. reg lnbmi date if date>= date("1/1/2022","MDY",.)
Source | SS df MS Number of obs = 44
-------------+---------------------------------- F(1, 42) = 843.30
Model | .024264532 1 .024264532 Prob > F = 0.0000
Residual | .001208485 42 .000028773 R-squared = 0.9526
-------------+---------------------------------- Adj R-squared = 0.9514
Total | .025473017 43 .000592396 Root MSE = .00536
------------------------------------------------------------------------------
lnbmi | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
date | -.0018493 .0000637 -29.04 0.000 -.0019778 -.0017208
_cons | 45.28764 1.443968 31.36 0.000 42.37359 48.20169
------------------------------------------------------------------------------また、体重の1日の変化に一喜一憂してはいけないらしいのでBMIの1週間の平均を取ることにしました。
BMIの定義は
体重(kg)÷身長(m)÷身長(m)
なので、分析の左辺が体重でもBMIでも大きな問題にならないはずです。
というのも、私の身長は一定なのでBMIから体重に左辺を変えるために身長の二乗を誤差項にかけても誤差項の期待値は0のままなはずだからです。
(コアノメ良だったので自信はありません)
ということで、1週間の平均を取ってグラフを描くためのコードがこちらです。
gen ave_bmi=(L3.bmi +L2.bmi+L1.bmi +bmi+F.bmi+F2.bmi+F3.bmi)/7
label var ave_bmi "BMIの1週間平均"
twoway scatter ave_bmi date if date>= date("1/1/2022","MDY",.) || lfit ave_bmi date if date>= date("1/1/2022","MDY",.)L.が過去のデータでL.bmi(or L1.bmi)が昨日のBMI、そしてF.がリード変数でF.BMIが明日のBMI、F2.bmiが明後日のBMIです。
こうして描かれたグラフがこれです。
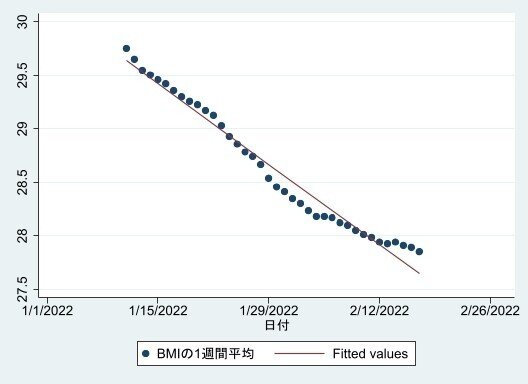
明らかに停滞していますが、開始時点よりは明らかに、そして着実に減っています。