
社内でISUCON問題(private-isu)に触れてみた 実践編

この記事は、2023年のPharmaXアドベントカレンダー14日目の記事となっております。
こんにちは、PharmaX、YOJO事業部エンジニアの江田です。
この記事は「社内でISUCON問題(private-isu)に触れてみた 環境構築編」の続きとなります。
前回はprivate-isuの環境構築を行いました。今回は実際に計測を行って改善するまでの流れを紹介します!
ベンチマーク実行時のCPU負荷確認
まずは、ベンチマーク実行時のコンテナごとの負荷を確認してみます。
これによってwebサーバー、アプリケーションサーバー、DBサーバーのどこにCPUのボトルネックがあるかがわかります。
docker container stats
# ベンチマーク実行
docker run --rm --network host -i private-isu-benchmarker /opt/go/bin/benchmarker -t http://host.docker.internal -u /opt/go/userdata今回はdockerで環境構築しているので、dockerコマンドで確認します。ec2などを使ってlinux上で各サーバーを立ち上げている場合は、htopやdstatを使って確認できます。
実行すると以下のように明らかにmysqlがリソースを食っていることがわかります。

スロークエリへのアプローチ
CPU負荷の結果から、まずはmysqlの改善から始めたほうが良いことがわかりました。次はmysqlの中で問題のあるクエリを探していきます。
1. MySQLのスロークエリログを出力する
前回書き換えた、/webapp/etc/my.cnf
[mysqld]
slow_query_log=1 # スロークエリを吐き出すようにする
slow_query_log_file=/var/log/mysql/slow-query.log # ログファイルの場所指定
long_query_time=0.0 # 指定した秒数以上の時間がかかったクエリをスロークエリとする
mysqlの設定でスロークエリを出力するには、上記の3つを設定する必要があります。
long_query_time=0にすると、0秒以上のクエリを出力するので実質すべてのクエリを出力するようになっています。
パフォーマンスチューニングにおいては、「時間はかからないが、大量に発行されるクエリ」もボトルネックとなりうるため、すべて出力してしまう方がチューニング対象を探しやすいです。
2. pt-query-digestで遅いクエリを確認
sudo pt-query-digest logs/mysql/slow-query.logpt-query-digestの結果は、3部構成になっており、全体の統計・レスポンスタイムのランキング・各クエリの詳細によって構成されています。
①全体の統計情報
全体の統計。今回はボトルネックとなるクエリを探すのが目的なので、ここは特に意識しなくて良いです。
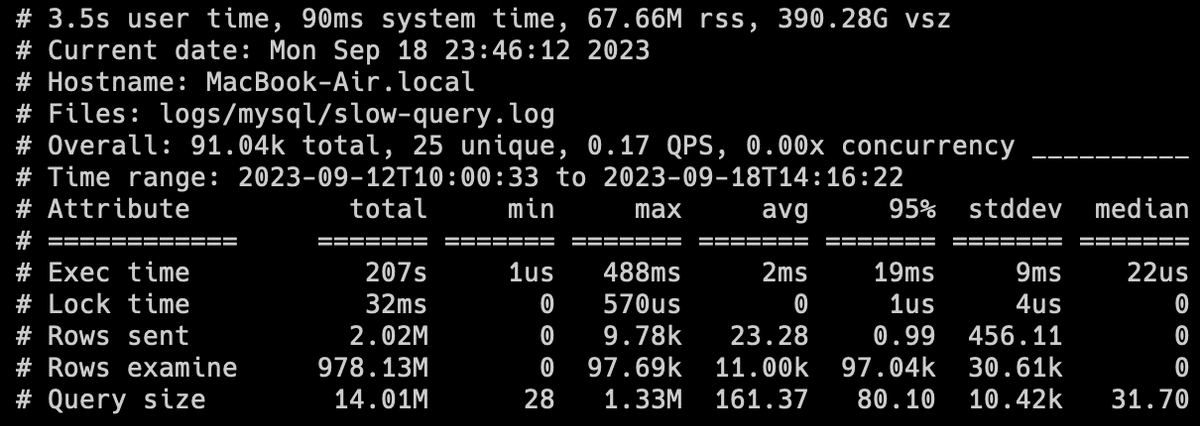
②ランキング
これを見ることで1位のクエリがmysql全体のレスポンス時間の67.9%を締めていることがわかります(Response timeの項目)。
次の項目でこの1位のクエリの詳細をみることができます。

③各クエリの詳細
ここで詳細が確認できます。
一番下を見ると、クエリが載っていて、commentsテーブルをpost_idで絞り込んでcreated_at順に並び替えるクエリであることがわかります。

特に注目すべきは、Rows sentとRows examineです。
Rows sent: クエリ結果として、送信した行数
Rows examine: クエリ処理のため、確認した行数
query1を見ると、、、

avgのRows sentが「2.42」、Rows examineが「97.67k」。
1回のクエリごとに、平均して2.4行返すために、約10万行走査していることがわかります。クエリ内容を鑑みると、特定のpost_idのコメントを平均2.4行取ってくるだけで、これほどの走査は必要なさそうだと予想できます。
3. クエリの効率がなぜ悪くなってしまっているのか調べる
EXPLAIN句を使ってクエリの実行計画を見てみます。
docker exec -it webapp-mysql-1 bash
mysql -uroot -proot
use isuconp
# mysqlのコンソールで実行
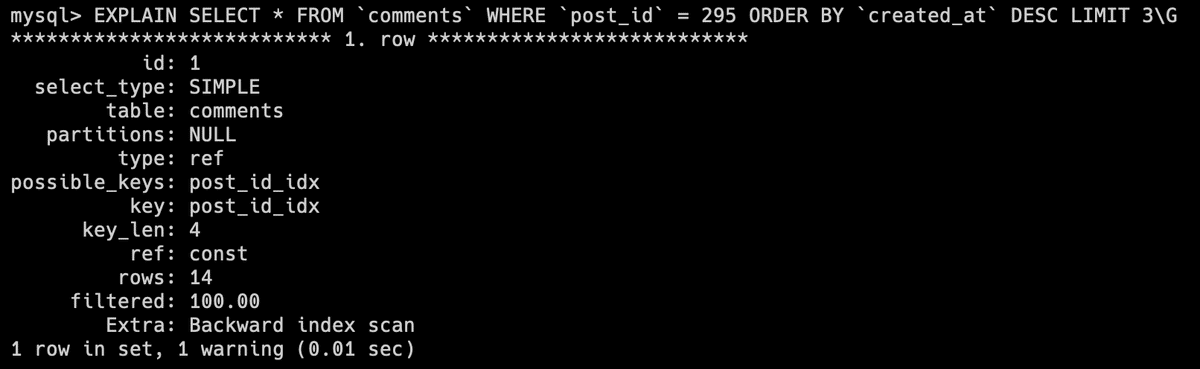
EXPLAIN SELECT * FROM `comments` WHERE `post_id` = 295 ORDER BY `created_at` DESC LIMIT 3\G
possible_keysがNULLになっていることがわかります。possible_keysは、行の検索に使用可能なキー(index)のことで、これがNULLということは利用可能なインデックスがないということです。
rowsを見るとクエリを実行する際に読み取る必要がある行数がわかります。
インデックスがないので、whereの条件にあうレコードを取る時すべての行を確認する必要があり、検索効率が悪くなってしまっています。
4. commentsテーブルにインデックスを追加してみる
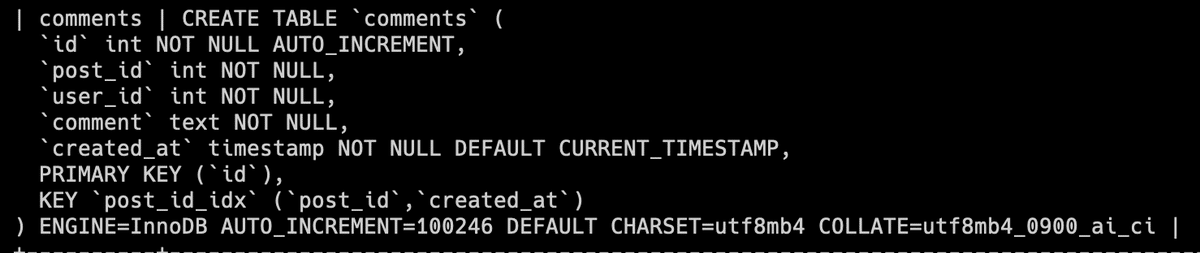
まず、commentsテーブルの状態を確認します。
SHOW CREATE TABLE comments;実行結果から、プライマリキー以外のindexが1つも貼られていないことがわかります。

今回のクエリに必要なインデックスを追加します。
今回のクエリはpost_idで絞り込んだ上で、created_atの降順に並べるため、post_id、created_atの複合インデックスを作成するのが良いです。
ALTER TABLE `comments` ADD INDEX `post_id_idx` (`post_id`,`created_at`);show create tableによって再び確認すると、しっかりインデックスが貼られていることがわかります。
インデックスを貼ったので、再びEXPLAINを実行してみます。
possible_keysを見ると先程のインデックスが使われていることがわかります。
rowsを見ると、なんと14行見るだけで目的のレコードを検索できることがわかります(元々約10万行)。
検索におけるインデックスがいかに重要かわかりますね。
ベンチマーク実行結果は12000点まであがりました(初期スコアは2000点ほど)。
docker run --network host -i private-isu-benchmarker /opt/go/bin/benchmarker -t http://host.docker.internal -u /opt/go/userdata
アプリケーション上の遅いエンドポイントへのアプローチ
改善を1つしたので、再びdocker container statsを使ってボトルネックを調べ直します。
ベンチマーク実行時の負荷を見てみると、ボトルネックがmysqlからappに変わっていることがわかります。

1. alpでnginxのログを見てみる
cat logs/nginx/access.log | alp ltsv -m="^/posts/[0-9]+","^/image/[0-9]+\.(jpg|png|gif)","^/@[a-z]*" --sort=sum --reversenginxのaccess.logをalpによって解析します。
-m で正規表現を与えることで、パスにIDなどが入ったエンドポイントも同一のエンドポイントとして集計できます。
また、--sort=sumによって、レスポンス時間の合計順にならべています。

GET /imageのエンドポイントが613回も叩かれており、合計のレスポンスタイム(SUM)が最大であることがわかります。
2. /imageのエンドポイントの処理を確認
get '/image/:id.:ext' do
if params[:id].to_i == 0
return ""
end
post = db.prepare('SELECT * FROM `posts` WHERE `id` = ?').execute(params[:id].to_i).first
if (params[:ext] == "jpg" && post[:mime] == "image/jpeg") ||
(params[:ext] == "png" && post[:mime] == "image/png") ||
(params[:ext] == "gif" && post[:mime] == "image/gif")
headers['Content-Type'] = post[:mime]
return post[:imgdata]
end
return 404
end/imageは名前の通り、指定したIDの画像を取得するAPIです。
DBのデータ(imgdata)をそのままreturnしていることから、dbに直接画像を保存していることがわかります。
3. 画像はpublicディレクトリに置き、配信はnginxにしてもらう
public配下にimageディレクトリを作成
mkdir ./public/imagedocker-compose.ymlでpublicディレクトリをマウントするようにします。
app:
# Go実装の場合は golang/ PHP実装の場合は php/
build: ruby/
environment:
ISUCONP_DB_HOST: mysql
ISUCONP_DB_PORT: 3306
ISUCONP_DB_USER: root
ISUCONP_DB_PASSWORD: root
ISUCONP_DB_NAME: isuconp
ISUCONP_MEMCACHED_ADDRESS: memcached:11211
links:
- mysql
- memcached
volumes:
- ./public:/home/public
ports:
- "8080:8080"
init: true
deploy:
resources:
limits:
cpus: '1'
memory: 1g
webapp/etc/nginx/conf.d/default.confに設定追加
server {
~関係のない設定は省略~
location /image/ {
root /public;
expires 1d;
try_files $uri @app;
}
location @app {
internal;
proxy_pass <http://host.docker.internal:8080>;
}
~関係のない設定は省略~
}
try_filesを用いることで、/imageへのリクエストが来た際、まず$uriに一致するファイル(例:/image/1111.jpg)を探し、なければアプリケーションサーバーに問い合わせるように設定できます。
続いてapp.rbの画像投稿API、画像取得APIを修正します。
投稿画像をpublicにおくため、fileutilsを使用
require 'fileutils'
# 保存場所の定数も追加
IMAGE_DIR=File.expand_path('/home/public/image',__FILE__)
画像投稿時、dbへの保存をやめ、publicに画像を置くようにする。
post '/' do
me = get_session_user()
if me.nil?
redirect '/login', 302
end
if params['csrf_token'] != session[:csrf_token]
return 422
end
if params['file']
mime,ext='',''
# 投稿のContent-Typeからファイルのタイプを決定する
if params["file"][:type].include? "jpeg"
mime,ext = "image/jpeg","jpg"
elsif params["file"][:type].include? "png"
mime,ext = "image/png","png"
elsif params["file"][:type].include? "gif"
mime,ext = "image/gif","gif"
else
flash[:notice] = '投稿できる画像形式はjpgとpngとgifだけです'
redirect '/', 302
end
if params['file'][:tempfile].size > UPLOAD_LIMIT
flash[:notice] = 'ファイルサイズが大きすぎます'
redirect '/', 302
end
params['file'][:tempfile].rewind
query = 'INSERT INTO `posts` (`user_id`, `mime`, `imgdata`, `body`) VALUES (?,?,?,?)'
db.prepare(query).execute(
me[:id],
mime,
'',#バイナリは保存しない
params["body"],
)
pid = db.last_id
#アップロードされたテンポラリファイルをmvして配信ディレクトリに移動
imgfile=IMAGE_DIR+"/#{pid}.#{ext}"
FileUtils.mv(params['file'][:tempfile],imgfile)
FileUtils.chmod(0644,imgfile)
redirect "/posts/#{pid}", 302
else
flash[:notice] = '画像が必須です'
redirect '/', 302
end
end
画像取得の際、DBの画像データをpublicにコピーする。
get '/image/:id.:ext' do
if params[:id].to_i == 0
return ""
end
post = db.prepare('SELECT * FROM `posts` WHERE `id` = ?').execute(params[:id].to_i).first
if (params[:ext] == "jpg" && post[:mime] == "image/jpeg") ||
(params[:ext] == "png" && post[:mime] == "image/png") ||
(params[:ext] == "gif" && post[:mime] == "image/gif")
headers['Content-Type'] = post[:mime]
imgfile=IMAGE_DIR+"/#{post[:id]}.#{params[:ext]}"
f=File.open(imgfile,"w")
f.write(post[:imgdata])
f.close()
return post[:imgdata]
end
return 404
end
設定によって画像はnginxで直接配信するので、publicに画像がなかった際に、この画像取得APIが叩かれることになります。
このAPIが叩かれた場合DBから画像を取得しますが、次回以降のリクエストで直接配信できるようpublicに画像をコピーしておくという処理になっています。
この方式にすることで、画像データをDBから手動で移行する必要がなく、除々に自動で画像データを移行してくれるようになります。
4. アクセスログをリセットして、ベンチマーカーを実行する
webapp/logs/nginx/access.log
中身をすべて削除
nginxやrubyの変更をサーバーに反映し、ベンチマーカー実行
docker-compose build
docker-compose up
docker run --network host -i private-isu-benchmarker /opt/go/bin/benchmarker -t <http://host.docker.internal> -u /opt/go/userdataベンチマーク結果はなぜか下がってしまいました。以前ec2で解いた際には同じ変更でしっかりスコアが上がったので環境起因の問題な気がします。

スコアはなぜか下がりましたが、今回の変更でレスポンスタイムが改善したか見てみます。
cat logs/nginx/access.log | alp ltsv -m="^/posts/[0-9]+","^/image/[0-9]+\.(jpg|png|gif)","^/@[a-z]*" --sort=sum --reverse

注目すべきは3点です。
まず、/imageのエンドポイントの順位が下がり、合計レスポンスタイムがかなり改善したことがわかります。
AVGを比較してみると、平均0.5秒かかっていたのが、0.04秒になっており、一回ごとのレスポンスが大幅に改善しています。
2~6列目の「1xx」はエンドポイントのステータスコードを表しています。
改善前ではすべて200番台で返していたのが、改善後には多くを300番台(リダイレクト)で返しており、nginxでの直接配信によってAVGが改善したことがわかります。
GET /をソースコードから解析する
/imageのエンドポイントが改善したことで、今度はGET / が一位に浮上しました。COUNTもAVGも高いのでボトルネックになっていそうです。
1. ボトルネックとなっているGET / のソースコードを見てみる
実際のアプリケーション側の処理を追っていきます。
するとmake_postsというヤバい関数があることがわかります。
def make_posts(results, all_comments: false)
posts = []
results.to_a.each do |post|
post[:comment_count] = db.prepare('SELECT COUNT(*) AS `count` FROM `comments` WHERE `post_id` = ?').execute(
post[:id]
).first[:count]
query = 'SELECT * FROM `comments` WHERE `post_id` = ? ORDER BY `created_at` DESC'
unless all_comments
query += ' LIMIT 3'
end
comments = db.prepare(query).execute(
post[:id]
).to_a
comments.each do |comment|
comment[:user] = db.prepare('SELECT * FROM `users` WHERE `id` = ?').execute(
comment[:user_id]
).first
end
post[:comments] = comments.reverse
post[:user] = db.prepare('SELECT * FROM `users` WHERE `id` = ?').execute(
post[:user_id]
).first
posts.push(post) if post[:user][:del_flg] == 0
break if posts.length >= POSTS_PER_PAGE# 20
end
posts
endヤバいポイントは大きく3つです。
最終20件しかレコードを使わないのに、全件取得してからループとbreakで20件に絞っている。
userのdel_flgが0以外のレコードは使わないのに、全件取得してからdel_flgが0のものだけ集めている。
post1件ごとにusersとcommentsのクエリが新しく走る(N+1問題)
1と2に関しては、LIMIT句の使用や、WHERE句でdel_flgが0のものを絞り込むことで解決できます。また、usersやcommentsはJOINを使用することで問い合わせ回数を無駄に増やさず済みます。
いずれにせよクエリを工夫することで改善できそうです。
2. GET / で使用されているクエリの改善
GET / の処理で、make_postsに渡すためのpostsを取得するクエリを改善します。
# before
results = db.query('SELECT `id`, `user_id`, `body`, `created_at`, `mime` FROM `posts` ORDER BY `created_at` DESC')
# after
results = db.query("SELECT p.id,p.user_id,p.body,p.created_at,p.mime,u.account_name FROM `posts` AS p JOIN `users` AS u ON p.user_id=u.id WHERE u.del_flg = 0 ORDER BY p.created_at DESC LIMIT #{POSTS_PER_PAGE}")LIMITを追加し、WHEREでdel_flgが0のものを絞り込みます。
JOINは一旦usersのみ行いました。
これに伴い、make_postsの中も不要な処理を修正します。

修正箇所は省略しますが、他のmake_posts使用箇所もクエリを修正します。
3. ORDER BY用のインデックスを貼っておく
ついでに、ORDER BY created_atを効率よく行うため、postsのcreated_atにインデックスを貼りました。
docker exec -it webapp-mysql-1 bash
mysql -uroot -proot
use isuconp
EXPLAIN SELECT p.id,p.user_id,p.body,p.created_at,p.mime,u.account_name FROM `posts` AS p JOIN `users` AS u ON p.user_id=u.id WHERE u.del_flg = 0 ORDER BY p.created_at DESC LIMIT 20;
ALTER TABLE posts ADD INDEX posts_order_idx(created_at DESC);4. ベンチマーカーを見てみる
webapp/logs/nginx/access.log
中身をすべて削除
nginxやrubyの変更をサーバーに反映し、ベンチマーカー実行
docker-compose build
docker-compose up
docker run --network host -i private-isu-benchmarker /opt/go/bin/benchmarker -t <http://host.docker.internal> -u /opt/go/userdata
スコアが跳ね上がりました。過去ec2で試した際はもっとスコアがでていた気がしますが(確か8万くらい?)、画像配信でスコアが下がったことが関係していそうです。
alpも確認します。
cat logs/nginx/access.log | alp ltsv -m="^/posts/[0-9]+","^/image/[0-9]+\.(jpg|png|gif)","^/@[a-z]*" --sort=sum --reverse
AVGを見ると2.265秒かかっていたところが、0.129秒まで改善しています。
スコアの伸びが思ったよりなかったことは残念でしたが、ボトルネックの改善自体はしっかりできていそうです。
本当はこの先も改善できる項目はいっぱいあるのですが、今回はここまでとします。
おわりに
今回は、実際にISUCONでやるような計測〜改善の流れをいくつか試しました。mysql、nginxの設定やアプリケーションのソースコードの改修など幅広い領域の改善ができたと思います。
やはり除々に改善していく様子がalpやpt-query-digestで数値としてしっかり出てくると達成感があり、やっていて楽しいですね。
ISUCONに関する勉強会は今後も実施予定なので、また記事等で紹介できればと思います!
お知らせ
PharmaXの採用情報について、こちらで随時更新しております。
少しでもご興味をお持ちいただけましたら、ぜひカジュアルにお話ししましょう!
またPharmaXでは、主にエンジニア向けイベントを定期的に開催しています。オンライン開催ですので、お気軽にご参加ください!