
ベクトルデータベースPineconeの概念と利用手順まとめ

こんにちは。
PharmaXエンジニアリング責任者の上野(@ueeeeniki)です!
今回はGPTの台頭によって、注目度が急上昇しているPineconeの概念と利用し始めるまでの手順をまとめたいと思います!
Pineconeは、LangChainやLlamaindexのようなLLMライブラリで文章をベクトル化して保存するのに使われます。
LLMの話をしだすときりがないため、今回はPineconeの概念と使い方のみをまとめていきます。
LLM用のベクトルデータベースにPineconeを使いたいと思っている方の参考になれば嬉しいです!
ベクトルデータベースとは?
その名の通り、ベクトルを保存できるデータベースです。
機械学習では、文章、画像、音声、動画などのあらゆるデータを、特徴抽出したベクトルに変換して扱うことが多いです。
ベクトルデータベースに保存することで、膨大な量のベクトルの類似度を計算することができます。
特にLLMでは、文章をベクトル化し、類似度の高い文章を取得することで、Fewshotプロンプティングなどを行うことができます。
Llamaindexなどを使って、社内文書のQAツールを作ってみたというような例であるように、プロンプトに自社独自のデータを読み込ませることで、GPTを自社独自の回答をさせることが可能になります。
Pineconeとは
公式ドキュメントにあるように、
・速い:数十億のアイテムがあっても超低クエリレイテンシーを実現している
・フレッシュ:データを追加、編集、削除すると、インデックスがライブ更新され、(最新の)データをすぐに準備することができる
・フィルタリング :ベクトル検索とメタデータフィルタを組み合わせることで、より適切で迅速な検索結果を得ることができる
という特徴のあるフルマネージドなベクトルデータベースです。
アクセスはAPI経由で行い、簡単に使い始めることができます。
特に、Pineconeのようにベクトルのフィルタリングをパフォーマンス高く実現するのはかなり難しいようです(下記ドキュメントなどをご覧ください)。
Pineconeに出てくる概念
Pineconeに出てくる概念をざっくり紹介したいと思います。
組織・プロジェクト管理
Organization: OrganizationにProjectやメンバーが紐づき、Organization単位で課金などの管理を行う
Project: Project単位でIndexを管理する。APIキーもProject単位で発行される。Projectの単位で、利用する環境(クラウドプロバイダーやリージョン)が設定される
index管理
Pod: PodはIndexを管理するハードウェアの単位。各インデックスは、1つまたは複数のポッド上で実行される。PodにはTypeとSizeがある。
Type: ストレージ効率重視のs1, パフォーマンス効率重視のp1, p2があります。(Typeはindex作成後には変えられない)
Size: x1、x2、x4、x8の4つのポッドサイズをサポートしています。容量は、Type × Size の組み合わせで決まります。
Index: Indexはベクトルデータを管理する単位。Indexには、ベクトルの次元数、ベクトルの類似性検索に使用するMetric(コサイン類似度、ユークリッド距離、など)などが設定出来る。
Collection: CollectionはIndexのある時点のバックアップデータ。データ移行のためにも使用できる。
データ管理
Namespace: Index内のVectorをNamespaceごとに分けて管理することができる。Vectorは必ず1つのNamespaceに属しており、デフォルトは空文字。queryを実行する時にNamespaceで絞り込むこともできる。
Metadata: Vectorに付随するメタ情報。String, Number, Booleanなどがサポートされている。queryを実行する時にMetadataでフィルタリングすることで、Vectorを効率よく検索することができる。
無料版Pineconeのセットアップ
それでは早速、Pineconeのセットアップ方法について見ていきましょう。
無料で簡単に始めることができます。
アカウント登録
Googleアカウントでサインインすると始めからOrganizationが作られている。
メールアドレスのドメインを読み取っているような挙動をする。
Projectを見るとデフォルトのプロジェクトがすでに作成されている。

API keyとEnvironmentを取得する。
APIはプロジェクトに紐付いており、下の写真のようにプロジェクト単位で管理されている。


index作成
ローカルでスクリプトを実行して、indexを作ることとする。
無料なので、Pod Typeは選べない。
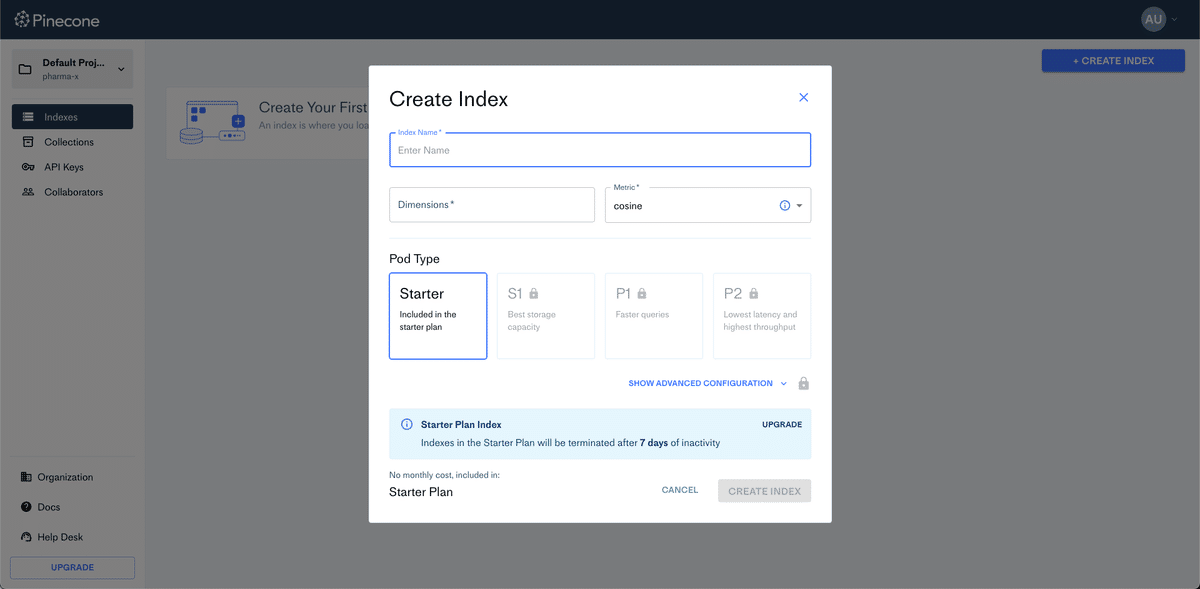
GUIで作ることも出来るが今回は、スクリプト実行にした。
# pinconeの初期化
pinecone.init(
api_key="<PINECONE_API_KEY>",
environment="<PINECONE_ENVIRONMENT>"
)
# indexを作成する
pinecone.create_index(
name="<PINECONE_INDEX>",
dimension=1536, # text-embedding-ada-002でベクトル化するときの次元数
metric="cosine",
metadata_config={
"indexed": [
"source",
"source_id",
"url",
"created_at",
"author",
"document_id"
]
}
)30秒〜1分ぐらい時間がかかって作られたのを確認する。
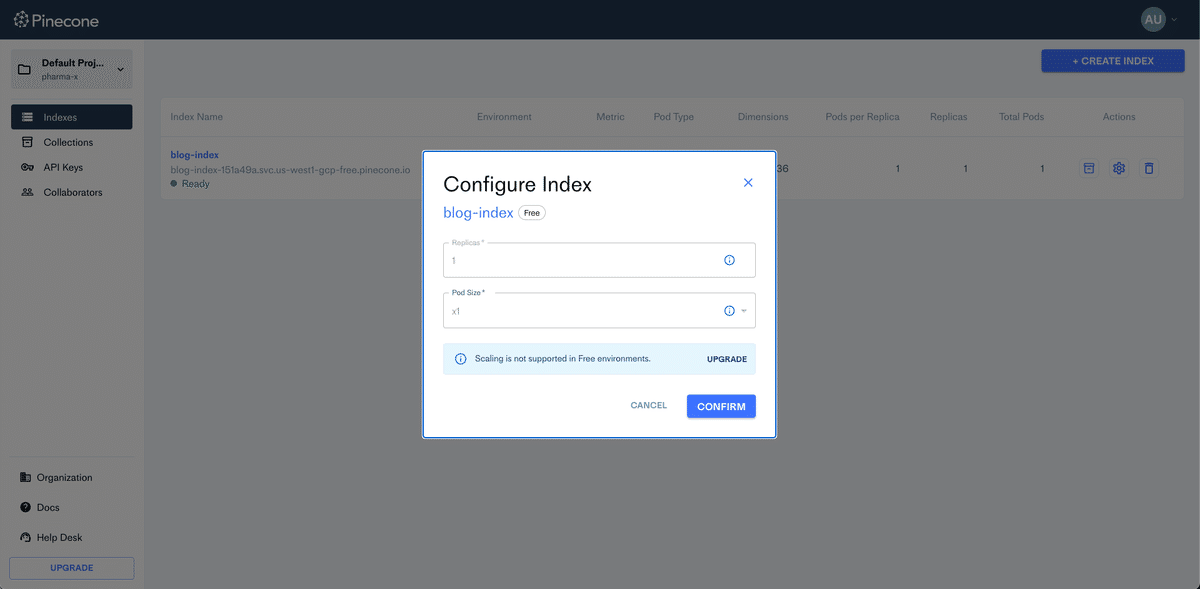
後から手動でpodのサイズやレプリカの数を変えることは出来るが、プランのアップグレードが必要。
実際にベクトルを保存すると以下のように表示される。
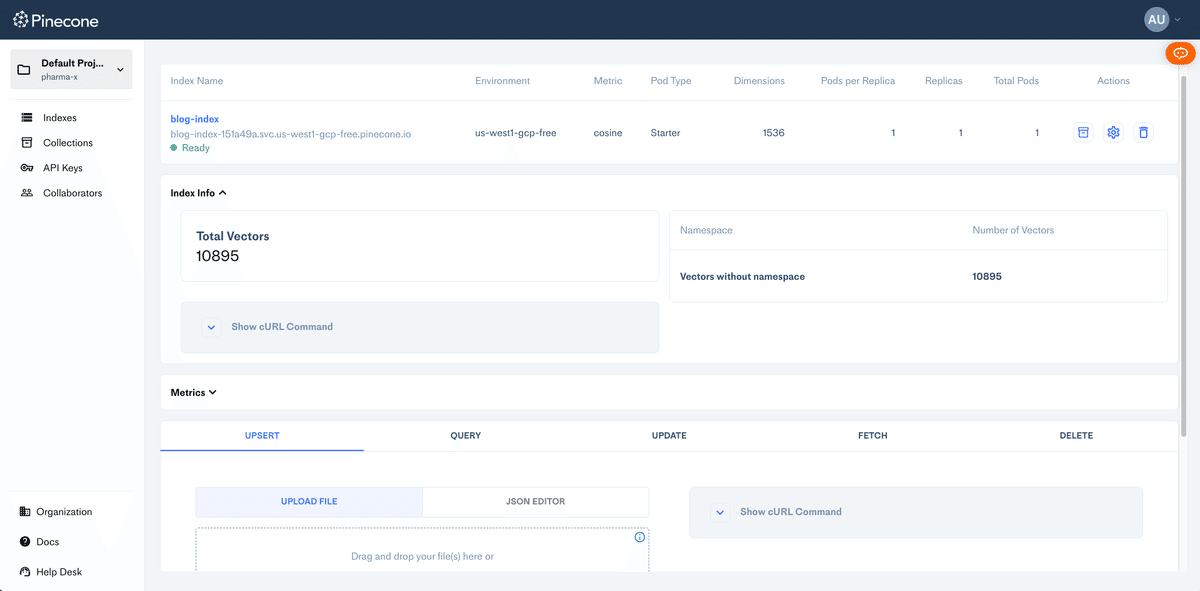
有料版Pineconeのセットアップ
有料版もセットアップしたので共有します。
アップグレード

billingタブからプランをアップグレードする。
クレジットカードの登録などをさせられて、プランを選べばいいだけなので迷うことはない。
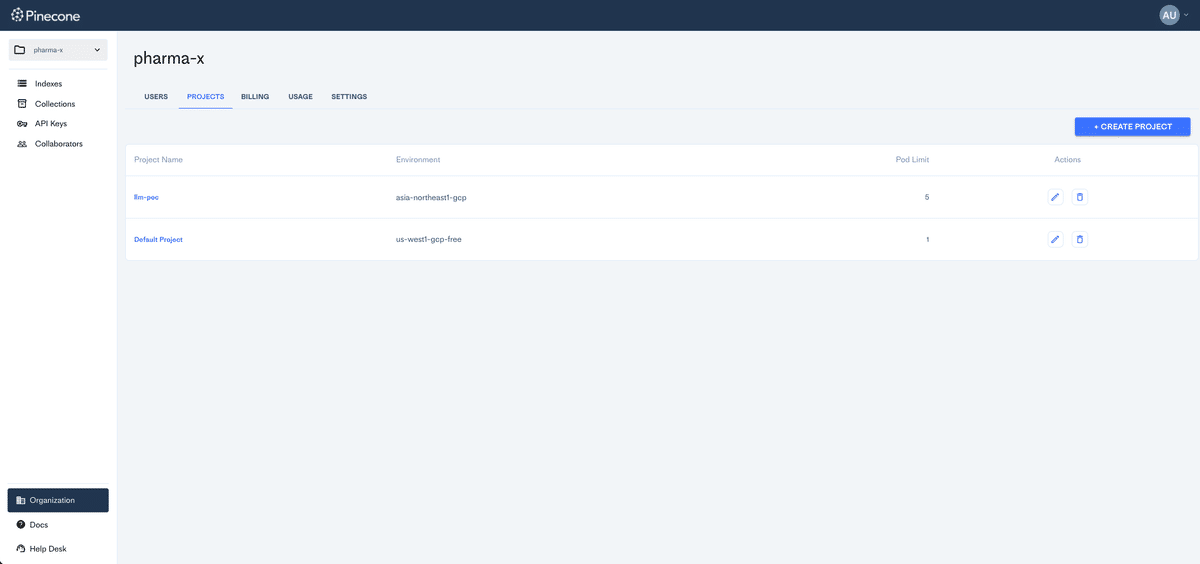
project作成
create projectをしようとすると下記のようにprovider、Region、pod数の上限を決めさせられる。
pod数はindexをまたいでの数らしい。
また数分待たされる。
indexの作成
今回は明示的にpod_typeを指定するようにする。
# indexを作成
pinecone.create_index(
name=os.environ["PINECONE_INDEX"],
dimension=1536, # text-embedding-ada-002でベクトル化するときの次元数
metric="cosine",
metadata_config={
"indexed": [
"source",
"source_id",
"url",
"created_at",
"author",
"document_id"
]
},
pods=1,
pod_type="s1.x1"
)プロジェクトが作成されているのを確認。

replicasの数やpod sizeは後からGUIでも変更可能(Pod Typeは変更できない)。

実際にベクトルを保存するとこのようになっており、namespaceでも区別されている。

使ってみての感想やまとめ
今回は、Pineconeの入門として、概念の整理やセットアップ方法を取り上げました。
これまでのテックブログでは、こういった入門記事みたいなものは取り上げて来なかったのですが、LLMのPoCの中でPineconeを使ってみ、あまり入門記事も多くなかったので、書いてみました。
マネージドなサービスなので、使い始めやすいのが非常によかったです!
パフォーマンスもかなりいい感じのため、セキュリティの問題などはあるもののベクターストアとして使い始めてみるのには最適かなと思います。
最後に
もっと詳しい話を聞きたいなど、ご興味がある方は、YOUTRUSTまたはTwitter DMからご連絡をお待ちしています!
また、生成AI/LLMの専任チームも立ち上げておりますので、ご興味ある方はご連絡ください!
