
ChatGPTでデータ活用を内製化しよう!(講義2回目:業務改善編 CRISP-DMとは)

こんにちわ、ペンギンラボです。内製化シリーズの2回目、今回から複数回に亘って、「データを活用して日々の業務を改善したい」と考えていらっしゃる方向けに、その具体的なノウハウをお伝えしてまいります。
世の中の多くの書籍、講座を見ていると、「技術ありき」でAIに関する技術(機械学習、深層学習など)を中心にしてしまっているコンテンツが散見されます。
もちろんそういった技術に対する理解は非常に重要です、それがないと実現可能性が検討できません。しかし、それらは全て何かを達成するための手段でしかありません。問題の中心は常に人やビジネスであるべきです。
ということで、まずは「AIを使って何を解決したいのか」にフォーカスし、ここを煮詰める練習をしましょう。といっても、何から始めれば良いか、さっぱりという人も多いと思います。そういう時は、世間一般に普及しているフレームワークを使って、「型をおさえにいく」ことから始めましょう。
世間に認知されたフレームワークを理解し、使うことことで、他の人との「共通言語」を獲得でき、円滑なコミュニケーションが可能となります。
CRISP-DMとは
CRISP-DMとは「CRoss-Industry Standard Process for Data Mining」の略称で、直訳すると「データマイニングの業界横断標準プロセス」となります。データマイニングは「データから金脈を発見する」というように解釈され、一昔前にはやった言葉です(金脈なんて期待値高いことを言っちゃったおかけですぐに廃れましたがw)。まぁ、実際のところは、データから商機を掴んでビジネス回していこう!という感じでしょうか。
何はともあれ、「業界横断的な」という表現があるように、データをビジネスに活用する上で業界問わずに使えるということから、考案から約30年経った現在、データ分析の界隈で最も使われているフレームワークになりました。
CRISP-DMはデータを中心に、6つのステップから成ります。「データが全ての源泉である」という一種の気概のようなもの?を感じることができて、私自身はここが最も気に入っているポイントです。
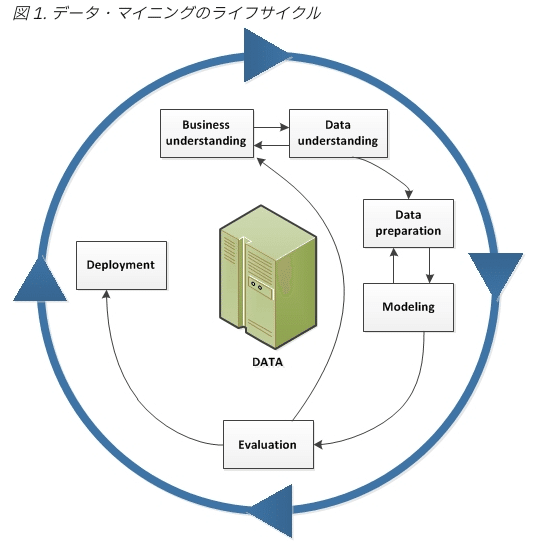
さて、あまり長文になってもだらけてしまうので、本日はここまでとして、次回から各ステップの詳細について見ていきましょう!
本日もご覧いただき、ありがとうございました!今後も連載を続けてまいりますので、データ活用に少しでも興味のある方、ぜひフォローをお願いします!w