
大型言語モデルの幻覚ランキング、GPT-4が首位、Googleが最下位

この記事は、異なる大型言語モデルが文書の要約時に発生する幻覚(正しくない要約)の性能を比較したランキングについて解説する。
LLM Hallucination Leaderboardとは、大型言語モデル(LLM)の文書要約時の「幻覚」の正確性を評価・比較したランキングのことです。
「幻覚」とは、文書の内容と合致しない誤った要約を含むことを指します。
このランキングでは、主要なLLM(GPT-3、GPT-4など)を対象に、以下の指標で評価・比較しています。正確率:文書内容と合致した正しい要約率
幻覚率:誤った要約(幻覚)を含む率
回答率:要約を回答できた文書数率
平均要約語数:1つの文書の平均要約語数
集計方法は、文書の要約をLLMに依頼し、独立したモデルでその要約文を分析。幻覚の有無から正確率と幻覚率を算出しています。
このランキングにより、各LLMの文書要約能力とその信頼性を客観的に比較・評価できるため、LLM開発や応用開発の参考データとなっています。今後もLLMの進化に伴い、継続的に更新される予定です。
GPT-4が最高の結果、Googleが最下位
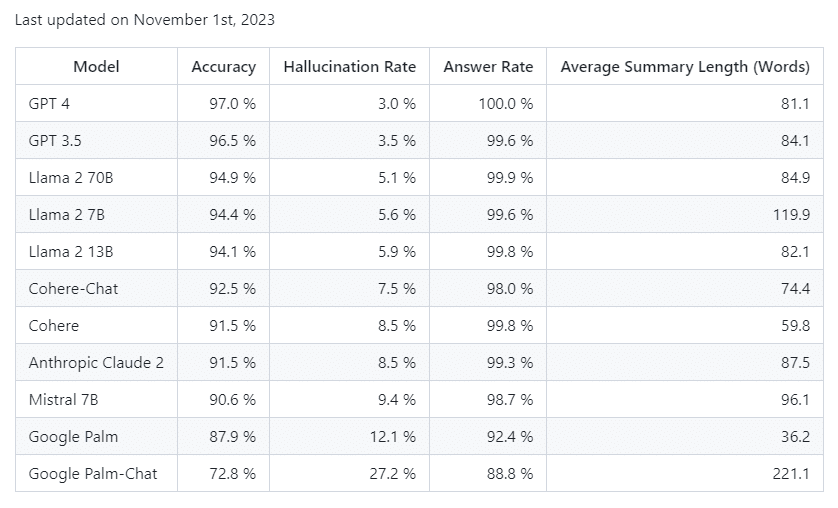
ランキングでは、要約時の正確性、幻覚率、回答率が含まれている。GPT-4は正確性97.0%、幻覚率3.0%、回答率100.0%と最高の結果を示した。一方で、GoogleのPalm Chat 2は正確性72.8%と低く、幻覚率は高い27.2%だった。
ランキングの算出方法
このランキングは、@vectaraが開発した幻覚評価モデルによって算出された。このモデルは、大型言語モデルが文書の要約時に幻覚を含む頻度を評価する。
そのモデルはHugging Faceでオープンソースとして公開されており、商用利用も可能。
含まれるデータと計算方法
ランキングには、各モデルの正確性、幻覚率、回答率、平均要約語数が含まれる。例えばGPT-4は、正確性97.0%、幻覚率3.0%、回答率100.0%、平均要約語数81.1語だった。
vectaraは、要約モデルの事実一致性データセットを用いて幻覚検出モデルを訓練し、1000個の文書を大型言語モデルに要約させ、831個の文書から各モデルの正確率と幻覚率を算出した。
以上の通り、このランキングは大型言語モデルの要約力能力を客観的に比較したものと言える。