
ChatGPTのライバルたち:大規模言語モデルの徹底比較

ChatGPTの登場から一年が経ち、その間に様々な開源大言語モデル(LLM)が登場し、それぞれがChatGPTに匹敵、あるいはそれを上回ると主張しています。この総合的な研究報告では、これらのモデルのパフォーマンスを詳細に比較し、それぞれのモデルがどのようなタスクで優れているかを明らかにします。
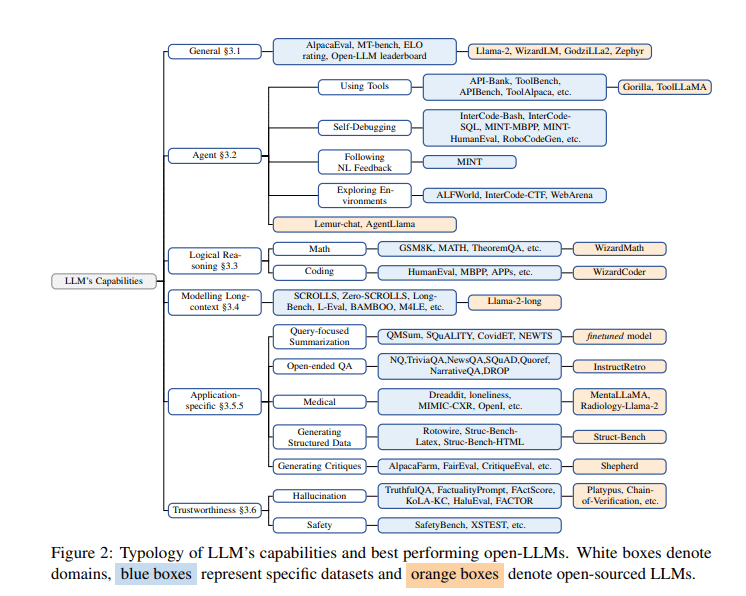
一般能力の比較
基准テスト:MT-Bench、AlpacaEval、Open LLM Leaderboardなど。
主要モデルのパフォーマンス:Llama-2-70B-chat、WizardLM-70B、Zephyr-7BなどがGPT-3.5-turboと競合。しかし、GPT-4が最高のパフォーマンスを示す。

代理能力の分析
基准テスト:API-Bank、ToolBench、InterCode-Bashなど。
モデルのパフォーマンス:Lemur-70B-chatがALFWorldやWebArenaでGPT-3.5-turboやGPT-4を上回る。
論理推理能力
基准テスト:GSM8K、MATH、TheoremQAなど。
モデルのパフォーマンス:WizardCoderやWizardMathがGPT-3.5-turboを上回る成果を示す。
特定の応用能力
基准テスト:AQualMuse、QMSum、SQuADなど。
モデルのパフォーマンス:InstructRetroがGPT-3に対して7-10%の改善を達成。
医学分野の応用
基准テスト:IMHI、OpenI、MIMIC-CXRなど。
モデルのパフォーマンス:MentalLlama-chat-13BやRadiology-Llama-2がChatGPTやGPT-4を超える。
可信赖性の評価
基准テスト:TruthfulQA、FactualityPrompts、HaluEvalなど。
モデルのパフォーマンス:Platypusなどのモデルが幻覚の低減や安全性の向上に寄与。
まとめ
この研究報告は、ChatGPTを含む各大言語モデルの能力を総合的に分析し、それぞれの長所と短所を明らかにしています。企業がAIを導入する際、また独自のLLMを構築したい人々にとって、この報告は非常に価値のある情報源となるでしょう。各モデルの性能を理解し、ビジネスや特定の用途に合わせて利活用しましょう。
論文:
https://arxiv.org/pdf/2311.16989.pdf