日本語モデルの長文QA性能の比較

現在2023/12/28ですが、最近Swallow-13b、nekomata-14b、ELYZA-japanese-Llama-2-13bといくつか13b級のモデルがリリースされました。
(モデルを公開してくださっている皆様、ありがとうございます!)
類似検索などで取得した文脈に対するQAやチャット(いわゆるRAG)に興味があり、長いコンテキストをうまく考慮できるかを調べてみました。
この検証結果によると以下のようにモデルを選ぶとよさそうですが、評価手法によるばらつきや偏りも大きいため、ご参考程度に考えてください。
定量的には
コンテキスト長を2000~3000文字より長くしたい場合はSwallow-13b-instruct-hf(緑の実践)
コンテキスト長が短くても構わない場合や、VRAMの都合などで7Bモデルが必要な場合はELYZA-japanese-Llama-2-7b-fast-instruct(赤の点線)
定性的には
簡潔に回答してほしければSwallow-13b-instruct-hf(緑の実践)
チャットモデルとして個人的に好みなのはshisa-gamma-7b-v1(黒の点線)とELYZA-japanese-Llama-2-13b-instruct(紫の実践)
7bモデルが点線、13-14bモデルが実践
検証対象のモデル
新しめの7b~13bモデルを対象にしました。
また、QAの指示に従う能力が必要なためinstrution tuningされたモデルのみを検証対象としています。
検証方法
公開されている文章に含まれる知識を問う質問にしてしまうと、モデルの持つ知識で回答ができてしまい、RAGの検証としては不適切です。
(当初、JSQuADを使おうと考えていましたがこの理由で変更しました)
今回は松xRの公開している美少女ゲームブランドRosebleuのシナリオデータセットから、08_Impuryという作品のデータを使用しました。
(素晴らしいデータを公開してくださり、ありがとうございます!)
08_ImpuryのAルートは約32万文字あります。
400文字程度ずつの約1000のチャンクに分け、intfloat/multilingual-e5-largeで埋め込み、質問「飛鳥が持ってきた猫缶のキャッチフレーズは何?」を使って類似チャンクを取得します。それらのtopkのチャンクをhard negativeとして、正解のフレーズである「ネコ、猛ダッシュ」を含むチャンクを加えてshuffleし、contextを作ります。
この猫缶は架空の商品なのでLLMの持つ知識で答えることはできませんが、正解のパラグラフを読んでこの答えを回答することは容易(=複雑な推論能力は不要)なため、モデルが文脈を考慮する能力のみを測るのに適していると思います。
context長と正解の位置をランダムに変えながらモデルごとに約2000回生成を行い、正解のフレーズがコンテキスト末尾から数えてどの位置にあるかによって、正解率がどの程度変化するかを計測しました。
(一般に、末尾から離れるほど文脈を考慮しづらくなる傾向があるため、末尾から数えています)
以下がイメージ図です。
promptのテンプレートはcalm2の場合で、モデルごとに適切なものに置き換えました。

定量評価
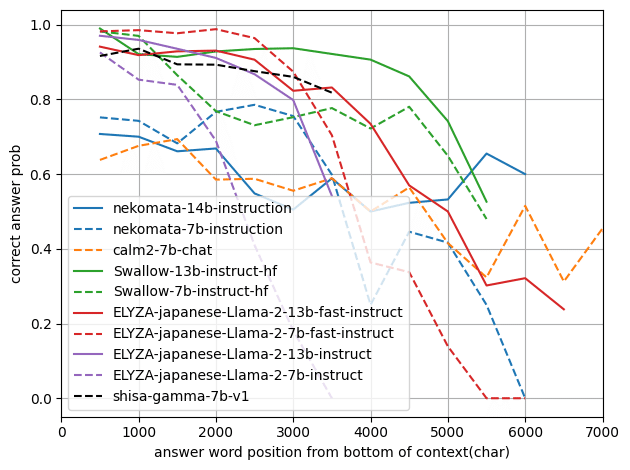
まずは、横軸を「コンテキスト末尾から数えた正解フレーズの位置(トークン数でカウント)」とした正解率のグラフです。
点線が7bモデル、実践が13-14bモデルです。

このグラフを見るとSwallow-13b-instruct-hf(緑)とELYZA-japanese-Llama-2-13b-instruct(紫)、shisa-gamma-7b-v1(黒)はほぼ差がないように見えますが、tokenizerが異なるため文字数基準に直すとかなり差があります。
1万文字あたりのトークン数は、calm2では約5000トークン、ELYZA(のfastではないモデル)の11,600トークンで2倍以上の差があります。

これが横軸を文字数でカウントした場合のグラフです(記事冒頭のグラフと同じ)。

末尾から3000文字以上離れたところに正解の情報がある場合は、Swallow-13b-instruct-hf(緑)がもっとも良く見えます。
コンテキストをあまり長くする想定がない場合、いくつかのモデルがほぼ同じ良さですが、7bモデルのELYZA-japanese-Llama-2-7b-fast-instruct(赤)が優秀に見えます。
個人的にはnekomata-14bの正解率が低いのが意外でした(Qwen-14Bの評判が良いため)。
誤った生成は以下の画像のような例があり、猫缶のメーカーである"ガルガウ"をキャッチフレーズと誤解して回答してしまうことが他のモデルと比べて多かったようです。

定性評価
定量評価の良かったいくつかのモデルについて、出力を見てみました。
ELYZA-japanese-Llama-2-7b-fast-instruct
前置きを言ってから回答する形式の応答がほとんどでした。
応答がかなり長くなるので簡潔に答えだけ出してほしい場合はやや使いづらいかもしれません。

Swallow-13b-instruct-hf
簡潔に答えのフレーズだけ出す形式です。
EOSを出さずに続きを書き始めることが多いので、#が出たらgenerateを終了する停止基準を入れておく必要がありそうです。

shisa-gamma-7b-v1
このモデルは独自の日本語DPOデータセットを使って訓練されているためか、簡潔すぎず長すぎずの良い返答だと思います。
個人的には好みです。

ELYZA-japanese-Llama-2-13b-instruct
ELYZA-13bは独自の高品質な指示データセットを使ったとblog記事に書いており、実際に出力は簡潔すぎず、定型的な文句で長くなりすぎたりせず全体的に良い感じに見えます。
ただ、3つ目の出力のようにハルシネーション的な出力が続くことがちょくちょくありました(promptの工夫で防げるかもしれませんが)

制限事項
1種類の質問だけで評価したため、質問を増やすことで結果が大きく変わる可能性があります
contextはすべて同一のシナリオの抜粋から作成しているため、wikipedia文章などドメインが異なると結果が大きく変わる可能性があります
QAの回答率の数値はそのモデルがどの程度QAデータでinstruction tuningされたかにある程度依存すると思います。同じQAデータで訓練した場合にどのベースモデルが良い結果になるかはこの検証では測れていません