
「MusicGen」と「ChatGPT」を組み合わせて色々なアーティスト風の音楽を生成してみた

Meta(以前の Facebook)による最新の音楽生成 AI モデル「MusicGen」を試してみました。本記事では MusicGen の概要や使用方法と、「ビートルズ風」や「レッチリ風」といった特定のアーティストっぽい楽曲を生成したデモを10パターン紹介します。
細かい部分は飛ばして生成結果のみ聞きたい人は、以下の目次から「melodyモデルで生成された音楽」、「largeモデルで生成された音楽」に飛んでください。
MusicGen:AI モデルの概要
MusicGen は、テキストとメロディから音楽を生成できるAIモデルで、入力されたメロディに基づく条件付けを行える点が大きな特徴です。モデルの具体的な機能については、開発者によるデモ動画が参考になるでしょう。
We present MusicGen: A simple and controllable music generation model. MusicGen can be prompted by both text and melody.
— Felix Kreuk (@FelixKreuk) June 9, 2023
We release code (MIT) and models (CC-BY NC) for open research, reproducibility, and for the music community: https://t.co/OkYjL4xDN7 pic.twitter.com/h1l4LGzYgf
MusicGen は 4 つのトレーニング済みモデルを提供していますが、その中でメロディを入力できるのは「melody」モデルだけです。
small: 300M モデル、テキストから音楽を生成
medium: 1.5B モデル、テキストから音楽を生成
melody: 1.5B モデル、テキストから音楽を生成、またはテキスト+メロディから音楽を生成
large: 3.3B モデル、テキストから音楽を生成
この記事では、melodyモデルとlargeモデルの性能を試してみます。
MusicGen の始め方
MusicGen のデモは Google Colab で提供されており、次のリンクからアクセスできます。
また、huggingface でも Web UI でmelodyモデルを簡単に試すことができます。ただし、他のユーザーが使用中の場合は待ち時間が発生する可能性があります。
Google Colab を使用すると、無料の GPU でも短時間の曲なら生成できるので、色々とパラメータを調整しながら試したい方は Google Colab をお勧めします。以下の章ではGoogle Colabを用いたMusicGenの動かし方を紹介します。
melodyモデルのデモ: テキスト+メロディから音楽を生成
まずは Google Colab で melody モデルを試してみましょう。このモデルは GPU でのみ動作するため、メニューから「ランタイム」 → 「ランタイムのタイプを変更」を選択し、ハードウェアアクセラレータが GPU に設定されていることを確認してください。
無料の T4 GPU ではメモリ不足によるエラーが発生する可能性がありますが、生成時間(duration)を短くしたり、入力するメロディの音声ファイルを短くしたり、一度に生成するトラック数を減らすなどで対応可能です。
以下に示すコードの検証結果は、A100 GPU を使用しています。
まず、1 番目のセルをそのまま実行します。必要なパッケージのインストールが始まります。
!python3 -m pip install -U git+https://github.com/facebookresearch/audiocraft#egg=audiocraft
# !python3 -m pip install -U audiocraft
次に、2 番目のセルに import torchaudio を追加して実行します。
from audiocraft.models import musicgen
from audiocraft.utils.notebook import display_audio
import torch
import torchaudio # 追加
次に、3 番目のセルのモデル名をmediumからmelodyに変更します。このモデルはテキストとともにメロディの音声データを入力として受け取ることができます。duration は生成される音楽の秒数を表します。デフォルトの 8 秒では短いため、ここでは 30 秒に設定します。durationを増やすと使用 GPU メモリが増えるため、T4 を使う場合はdurationはデフォルトのままにしておくことを推奨します。
model = musicgen.MusicGen.get_pretrained('melody', device='cuda') # medium → melody
model.set_generation_params(duration=30) # 8 → 30。無料GPUの場合は8のまま変更しないこと推奨
4 番目のセルの実行前に、左のフォルダアイコンからファイルツリーを開きます。ここに入力したいメロディの音声データをパソコンからドラッグ&ドロップでアップロードします。今回の例では、musicgen_melody.wavをアップロードしました。
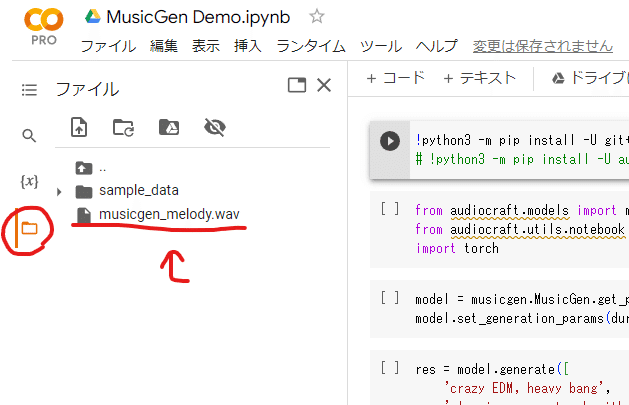
4 番目のセルに以下のコードを入力し実行します。melody_inputとdescriptionは、各々の環境や好みに合わせて値を変更できます。descriptionはリスト形式になっており、リストの各アイテムが 1 トラックに対応します。下記の例はリストに 10 個の文章が格納されているため、10 トラックが生成されます。
# 設定
melody_input = './musicgen_melody.wav'
description = [
"A composition featuring the tonal qualities of The Beatles, characterized by memorable melodies, unique chord progressions, strong vocal harmonies, and a pop-rock instrumentation.",
"A musical piece embodying the spirit of Metallica, incorporating heavy guitar riffs, dynamic drumming patterns, intense vocal lines, and complex song structures.",
"A track inspired by the unique sound of Earth, Wind & Fire, infusing elements of soul, funk, R&B, and pop, with a strong presence of brass and layered vocal harmonies.",
"A song with the distinct style of the Red Hot Chili Peppers, intertwining elements of funk, punk rock, and psychedelic rock, featuring standout bass lines and energetic vocals.",
"A music piece reflecting Skrillex's signature dubstep style, marked by aggressive electronic synth lines, intricate beat patterns, and heavy bass drops.",
"A composition that mirrors the style of Nujabes, combining elements of hip-hop beats, jazz samples, and atmospheric soundscapes, producing a calm and emotive mood.",
"A song inspired by D'Angelo's Neo-Soul style, characterized by intricate rhythmic patterns, rich vocal harmonies, and a seamless blend of R&B, jazz, and soul elements.",
"A creation mirroring the experimental and jazz-infused electronic music style of Flying Lotus, marked by intricate beats, abstract soundscapes, and layered musical textures.",
"A composition capturing the essence of Snarky Puppy's unique blend of jazz, funk, and world music, characterized by complex harmonic structures, intricate rhythmic patterns, and high-level musicianship showcased through extended improvisational sections.",
"A track capturing the essence of J Dilla's innovative approach to hip-hop production, characterized by unique sample selection, off-kilter drum programming, and a soulful, laid-back aesthetic."
]
# 実行
melody, sr = torchaudio.load(melody_input)
res = model.generate_with_chroma(description, melody[None].expand(len(description), -1, -1), sr)
display_audio(res, 32000)今回のdescriptionの文章は全て ChatGPT を使って作成しています。以下にそのプロンプトを示します。
数分待つと音楽が生成され、Google Colab上でプレビューを聞くことができるようになります。メモリ不足でエラーが生じた場合は、durationの値を調整したり、melody_inputに入力する音声ファイルを短いものにするなど試してみてください。
出力された音楽ファイルを保存したい場合は以下を実行すれば左のファイルツリー上に保存されます。ランタイムの接続解除するとファイルが消えてしまうのでローカルにダウンロードするのをお忘れなく。
from audiocraft.data.audio import audio_write
for idx, one_wav in enumerate(res):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'MusicGen_output_{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")
もしくはGoogle ColabとGoogle ドライブを接続してそちらに保存するのも良いと思います。この場合はランタイムの接続解除してもファイルが消えません。ドライブと接続して保存するには下記のコードを実行してください。
from google.colab import drive
drive.mount('/content/drive')
from audiocraft.data.audio import audio_write
for idx, one_wav in enumerate(res):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'./drive/MyDrive/MusicGen_output_{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")
melodyモデルで生成された音楽
上記の楽曲はラグタイムの名曲、Scott Joplin の The Entertainerをメロディとして入力しています。
今回の出力結果を確認した限りだと、melodyモデルは入力されたメロディを新しいコンテキストやスタイルで単純にアレンジするようなものではないということがわかります。入力メロディをサンプリングした新しいトラックを創造する、という感覚が近いように思います。これでメロディの元ネタ当てゲームなどを作るのも面白いかもしれません。
largeモデルのデモ:テキストから高品質な音楽を生成
次に一番高性能なlargeモデルを試してみます。こちらのモデルはメロディの入力はできずテキストのみから楽曲を生成します。
1 番目、2 番目のセルはデフォルトのままなので省略。3 番目のセルでモデル名をlargeにします
model = musicgen.MusicGen.get_pretrained('large', device='cuda') # medium → large
model.set_generation_params(duration=30)
4 番目のセルを実行します。
description = [
"A composition featuring the tonal qualities of The Beatles, characterized by memorable melodies, unique chord progressions, strong vocal harmonies, and a pop-rock instrumentation.",
"A musical piece embodying the spirit of Metallica, incorporating heavy guitar riffs, dynamic drumming patterns, intense vocal lines, and complex song structures.",
"A track inspired by the unique sound of Earth, Wind & Fire, infusing elements of soul, funk, R&B, and pop, with a strong presence of brass and layered vocal harmonies.",
"A song with the distinct style of the Red Hot Chili Peppers, intertwining elements of funk, punk rock, and psychedelic rock, featuring standout bass lines and energetic vocals.",
"A music piece reflecting Skrillex's signature dubstep style, marked by aggressive electronic synth lines, intricate beat patterns, and heavy bass drops.",
"A composition that mirrors the style of Nujabes, combining elements of hip-hop beats, jazz samples, and atmospheric soundscapes, producing a calm and emotive mood.",
"A song inspired by D'Angelo's Neo-Soul style, characterized by intricate rhythmic patterns, rich vocal harmonies, and a seamless blend of R&B, jazz, and soul elements.",
"A creation mirroring the experimental and jazz-infused electronic music style of Flying Lotus, marked by intricate beats, abstract soundscapes, and layered musical textures.",
"A composition capturing the essence of Snarky Puppy's unique blend of jazz, funk, and world music, characterized by complex harmonic structures, intricate rhythmic patterns, and high-level musicianship showcased through extended improvisational sections.",
"A track capturing the essence of J Dilla's innovative approach to hip-hop production, characterized by unique sample selection, off-kilter drum programming, and a soulful, laid-back aesthetic."
]
res = model.generate(description, progress=True)
display_audio(res, 32000)
largeモデルで生成された音楽
melodyモデルと比べるとだいぶクオリティが上がり、インスパイアされたアーティストのイメージに近い曲調になっていることがわかるかと思います。ちなみに30 秒 ×10 曲を作った際の生成時間は A100 で 183 秒でした
まとめ
Meta の新しい音楽生成 AI モデルである MusicGen を試用してみました。
melodyモデルは、入力されたメロディを新しいスタイルでアレンジするというよりは、入力メロディからインスピレーションを得て新しいトラックを作り出すことに主眼を置いていると感じました。メロディの解釈については、拍子の解釈が不完全などまだ改善の余地があるように思えます。
一方、largeモデルはメロディの入力ができないものの、生成されるトラックの品質はかなり優れていました。人間が作成したトラックの品質と比較するとまだギャップは存在しますが、AIが人間のトラック制作能力に近づいていく日はそう遠くないかもしれません。現在のところ、MusicGenはボーカルを出力しないですが、今後このモデルとAIボーカルを組み合わせたトラックがさまざまな形で現れてくることになるでしょう。