
「テキストマイニング」したいと思ったらここだけ押さえとけばOK

Hakali小川です。
「気づく」ためのデータ分析を進めていくにあたり、そもそもデータ以外の部分が大事であることをよく書いている訳ですが、そうは言っても実際にデータを扱う必要は当然ながらある訳です。
でもじゃあ「データサイエンティスト養成講座だ!」とかになってしまうとおおごとな訳で、こちらからすると欲しい果実をサクッと手に入れたい、統計とか偏差とかそういうのはできればごめんなさいしたい。
という方のためのコンテンツがあまりないなと思い、非データ系人材のためのサバイバルデータアナリシスシリーズを展開してみたいと思っています。頭文字をとってSDAs。なんか流行り感/持続可能感出てきました。SDAs。
SDAs第一弾は、「たくさんあるテキストデータの中から、意味のある考察を抽出したいなー」と思いついてしまった非データ系人材の方が、最も労力をかけずにテキストデータを分析できる方法について考えてみたいと思います。
なるべく難しいことは言わずシンプルにアウトプットイメージを持ってもらえるようにがんばります。
そもそも「テキストマイニング」って何?
ちゃんとした定義はwiki見てもらえればと思いますが、要は自由記述のデータからなんらかの意味を抽出するための方法です。
アンケートとかで「はい、いいえ」といった質問をしている分には「『はい』と答えた人が70%もいました!」みたいなレポートを作るのは簡単なのですが、そのためには質問をかなり緻密に制御する必要があります。それはそれでとても大事なのですが、ニュアンスとか雰囲気とか気持ちとかを知りたい時も当然ある訳でFA(Free Answer)形式にならざるを得ない場合、その自由記述データを上司にどうやって説明したらいいのか悩ましいですよね。
または、SNS上で自社サービスのコメントをキーワード検索で引っ掛けた時に、それが1万件あったとすると、どうやって解釈したらいいんだろうか。目検かな?でも目検だと最初の方は文句が多かったけど後の方で褒めてるものが多かったらどうしよう、とか、それを上司に突っ込まれた時になんて説明しよう、となってしまいますよね。
テキストマイニングはざっくりそんな時に使うものになります。
「テキストマイニング」のアウトプットイメージ
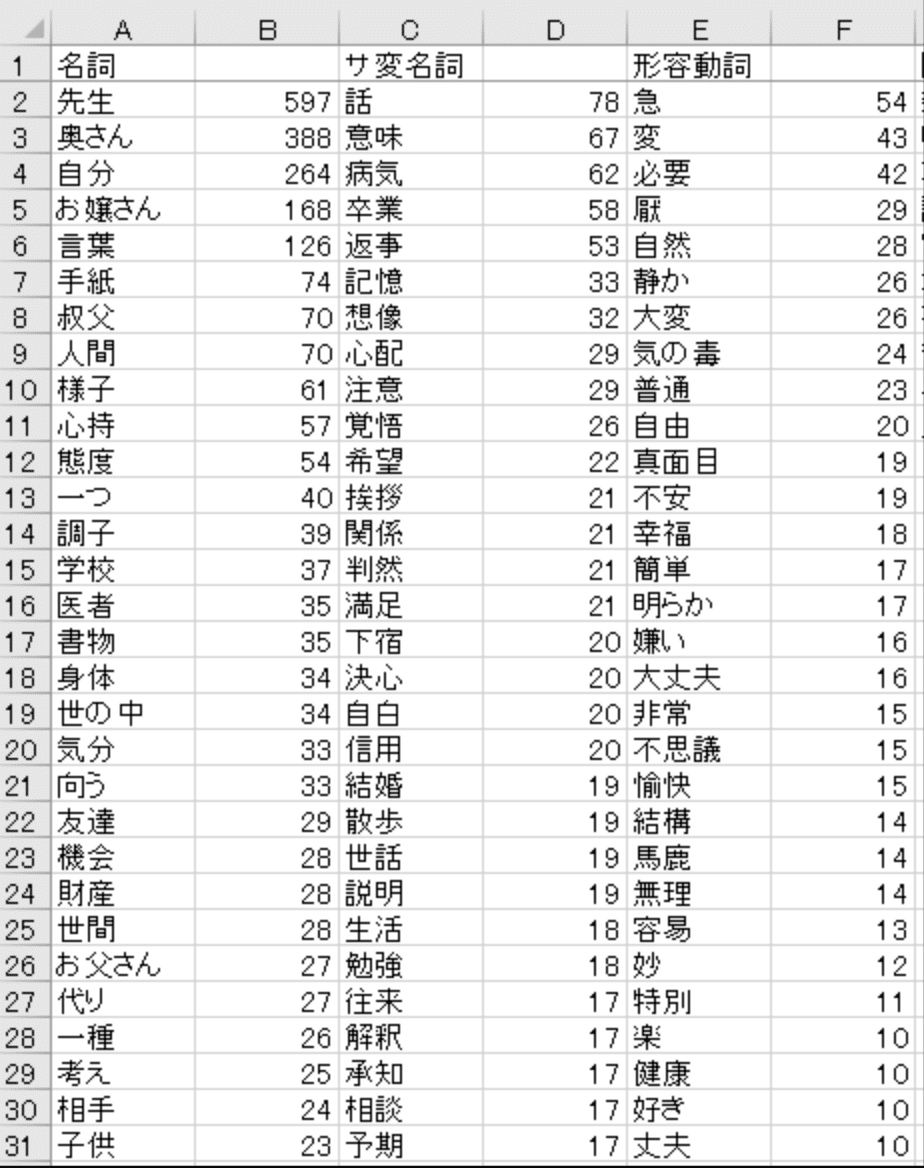
単語のカウント
一番シンプルなのはこれですよね。出てきた単語をカウントするという。でも正直これだけだとあんまり意味が読み取れません。。。ふーん、てなって終わり。
下記は夏目漱石「こころ」の品詞別単語カウント。
ネガ・ポジ分析
SNS分析とかで出てくるのはその発言はネガティブなのかポジティブなのか。をカウントして「ネガティブ4割、ポジティブ6割でした!」みたいなものもあります。

これは大体単語自体を「ネガティブワード」「ポジティブワード」とラベルづけしてカウントしていることが多い印象です。だから「お前マジでクソだなwww」という実は褒め言葉なやつとかはネガティブに入ってたりはします。
個人的には上記のような精度そのものもあるのですが、「6割がポジティブでした!」と言われても「ふーん、それは良いの悪いの?ポジティブな要素はなんなの?」という方が気になりますけどね。それ以上思考が深まらないものをレポートで出してもうーんてなりがち。まぁ、とりあえずのレポートとしてはいいと思うのですけども。
派生系としてはポジネガだけじゃない喜怒哀楽的な感情分析まではいっているものもあります。
一緒に出てくる単語の組み合わせ分析(共起分析)
個人的には一番良く使う方法です。
これは、一人の人が書いている文章に一緒に出てくる単語(共起といいます)のセットを見て、一緒に出てくる率が高いものを教えてくれます。
下記は多分夏目漱石の「こころ」のマイニング結果。

これの良いところは内容をクラスタリングしてくれるから意味がとりやすいんですよね。全体を通してどんなことを言っているのか、サマリーできる。
ということで僕は大体これを使っています。具体的なイメージとしては、
・結果としては大きくnタイプくらいのコメントがありそう
・それぞれのタイプと特徴的なコメントはこれ(具体的な例示も行う)
・こうなっている背景の仮説としてはこういうことが考えられそう
と、フリーコメントをもとにそうなっている因果の仮説を立てるところまでならこれでできますね。
アンケートだったらその内容をもとに定量的な質問に置き換えて再度取ることも可能は可能です(実際は予算的に難しいでしょうけど。。アラブの石油王くらいしか許されなさそうなプレイか...)
「テキストマイニング」を楽にしたいぞ
現状、僕の知りうる範囲で上記効能が得られる「テキストマイニング」が楽に(無料で)できるのは下記2点かなーと思っています。他にもあったらごめんなさい使ったことないです。
ただし、SNS分析系は今回スコープに入れてません。SNS分析はツールが豊富にあるのでそちらをご参照遊ばれてくださいませ(ニーズがあればこちらもリサーチしてレポートしますが世の中にいっぱいありそう。)
選択肢1:USER LOCALのAIテキストマイニング
オンライン上でファイルupすればサクッと解析してくれるというすぐれものです。衝撃的な楽さですね。懸念があるとすれば下記
・クラウド上にデータ上げてしまう(究極見られうる)
・ファイルサイズが10MBまで
特に後者はそれなりの分量やろうとすると致命的ではあります。ただ、サクッとやるにはもうほんとこれで充分です。
選択肢2:立命館大学教授が作ったKH-Coder
もう何年も僕がお世話になっているのがKH-Coder。macが若干インストールがめんどくさいのですがwindowsならサクッとできます。macもインストールサポート版みたいなやつが3,980円くらいで提供されているのでインストールでごちゃごちゃ考えたくない人は3,980円払うのが平和かもしれません。
上記2つだけ知っておけば一般ピーポーが求められるレベルのテキストマイニングは大体完結します。これだけならコンサル費払うまでもないかもですね。。。
結論:テキストマイニングは「気づき」観点では割と難しい
上記ツールがあるのでテキストマイニングの作業自体は比較的易しいのですが、そこからの意味の読み取りがなかなか難しいと思っています。
やって終わりになりづらい分析といいますか。そこからもう1段2段考察を深めていかないと見えてこない/気づけない事が多い。アンケート設計士の方々が「フリーコメントはなるべくやっちゃいかん。」とよくおっしゃる理由がこの辺にあるのだと思います。
設計側で楽をしている分(とりあえず自由に書いてもらっちゃえ)、意味の読み取りタイミングでそのツケを払ってるような感覚です。
ただ、とはいえ「雰囲気/空気」を知れる観点では気づきにつながる大事な情報であることも確かなので、フリーコメントデータをお持ちの皆様はぜひテキストマイニングを行った上で、そこから更にもう一段深ぼった考察をしてみていただけるとよいかと思います。
質問等ある方はどっかからお気軽にご連絡いただければ、僕も深まるのでありがたいですー。よろしくおねしゃす。