
西内 啓氏 推薦「Excelで学べるデータドリブン・マーケティング」まえがきと目次&1章を全文公開

2025年1月29日発売「Excelで学べるデータドリブン・マーケティング」
【MMMやマーケティング分析に付帯する基礎となる統計知識から『学びたい』方向け】の書籍
「Excelで学べるデータドリブン・マーケティング」はデータの分布とは?回帰分析の決定係数とは?といった統計の基礎から学ぶことができる書籍です。判型を大きくしカラーにしたのはExcelで行うデータ分析の演習の画面キャプチャーを張り付けて丁寧に解説しているからです。この書籍のターゲットはTVCMやネット広告などの売上貢献を定量化し予測モデルを構築するMMM(マーケティング・ミックス・モデリング)を行う際に統計や因果推論の基礎から確実に学びたい方です。TVCMの投下単位のGRP(グロス・レーティング・ポイント)とは?から解説するなどマーケティング初心者向けの書き方をしています。
判型が大きく難しい技術書に見えますが、丁寧に解説するために大きな判でフルカラーになっているだけで内容は次に紹介する「その決定に根拠はありますか?」ほど高度ではありません。基礎から学びたい方向けの書籍です。53万部を販売した大ヒットシリーズ書籍の「統計学が最強の学問である」
著者の西内啓氏に「マーケターはグラフの見た目より『因果推論』に注意すべきである」と推薦コメントを頂くことができました。
この書籍は2018年11月に発売した書籍の改訂版です。演習をより分かりやすくるために、動画講義を付録として追加しました。合計9時間を超える動画講義8本のうち、1本の動画講義を公開しました。1章の内容、データ分析の基本的な考え方、各章で行う分析演習など、書籍と動画講義の全体像のガイダンスとなっています。
上記内容は2025年に追記した内容です。
以下の内容は改訂版の初版出版時、2018年に公開したものを一部、改訂に伴い修正した1章までの全文公開です。
【まえがき&目次&第1章を全文公開】
はじめに
本書はデータドリブン・マーケティングをテーマにした書籍ですが、昨今マーケティングの現場で話題になっているような、あらゆるデータを集めて分析し、その分析にAIを活用するといった先進的な内容を紹介するものではありません。マーケターが日々の意思決定をデータドリブンにしていくために必要な知識を補うことにフォーカスしたものです。 例えば、消費者アンケート結果などの定量調査を集計し考察する際に、特定のターゲットセグメントが平均より高いスコアだった場合、ただのバラつきや誤差でそのような差が生じる確率を考慮していますか?本書の演習で紹介する「独立性の検定」などの統計的検定を行ったほうが慎重な判断ができます。 例えばTVCMの効果検証で、放映前後の消費者アンケートの態度変容(購入意向率など)や売上の変化などから効果を推し計っていませんか?施策の実施前後を単純比較するやり方は、季節性などの施策以外の要因の影響を考慮できないなど、多くの問題を含んでいます。因果推論のためには正しい分析のデザインが必要です。本来マーケティングの現場で行う意思決定には統計や因果推論の知識が必要なものが多いのですが、そうした知識が浸透していないため、アンケート集計で有意な差がないのに有益な傾向差を見つけたと勘違いする、間違えた因果推論で施策の効果をはき違えているといったケースが見受けられます。 昨今マーケティングの現場では、ビッグデータマイニングやデータ分析におけるAI活用など先進的な取り組みが注目されていますが、それ以前に取り組むべき課題ではないでしょうか?本書はそうした状況を変えるために、マーケターに必要な統計や因果推論の基礎知識を「演習形式」で共有するものです。 筆者は過去、広告会社プランナーやデジタルマーケティングコンサルタントとして活動する中で、メディアプランニングに使用する調査データベースや消費者アンケート、ダイレクトマーケティングの顧客獲得や購買履歴、デジタル広告やWebサイトのアクセスログなどの多用なデータと向き合い、必要 な知識がない状態で様々な意思決定を行っていました。しかし、当時のデータ分析や調査による意思決定は間違いも多かったと思います。ターニングポイントとなったのは(株)電通ダイレクトフォース(現 (株)電通ダイレクトマーケティング)在籍時に時系列データ解析によってオフライン施策とオンライン 施策を横並びで評価できるマーケティング・ミックス・モデリング(以下「MMM」)を知ってからです。 当初は外部の専門家に委託してその分析を行いましたが、それを自ら会得するために統計や因果推論を学びました。それ以降、分析手法の引き出しが増え、マーケターとしての視野が格段に拡がりました。 そうした知識や分析スキルを共有するために、ExcelでMMMを行いながら学べる書籍を作りました。MMMは本来、専門家によって提供される高度な分析サービスです。統計学に初めてチャレンジする方がこれを習得することを目指した無謀なチャレンジです。Excel VBAで組んだマクロとExcel アドインの演算機能の「ソルバー」を用いるなど、分析作業を効率化するための工夫を凝らしましたが、 それでも本書の全ての演習を終えるのに半日から1日から2日前後はかかると思います。それでも、MMMや統計を学ぶ上で筆者が費やした膨大な時間の浪費は避けていただけるはずです。
これまで、統計になじみのない人間がMMMを学ぶ教科書はありませんでした。難解な専門書から手探りでヒントを探しながら学んできたため、筆者は少なくみて1,000時間は費やしたと思います。そうした経験により、分かりやすさにこだわり、統計関連の書籍にありがちな数式を用いた解説を極力減らし、演習で実際に分析をやってみながら学ぶ構成としました。詳細な知識は「統計WEB」や参考文献を案内するようにしています。 本書は統計やデータマイニングを学びたくなったマーケターが「専門書の壁」を越えて、生きたノウハウを身につけてもらうための「ビジネス専門書」を目指しました。

演習はMMMだけでなく「エクセル統計」体験版を用いた顧客分析の演習(数量化2類やクラスター分析等)も追加しました。最新のデータ解析ツールやシンジケートデータを紹介するコラムも入れました。

筆者が開発したExcelの「MMM_modeling」Bookと「MMM_simulation」Bookを用いて皆さん自身のデータも分析できるようにしました。MMMはマーケティングの「全体最適」をテーマにされている方には有益なヒントになるものです。オンラインとオフラインの施策またはチャネル全体でのマーケティングの全体最適を模索する企業のマーケティング責任者や経営者、またはそれを支援するコンサルティング会社やエージェンシーのマーケターに役立つものになったのではないかと思います。 皆さんが手掛ける(または支援する)ブランドを成長させるために必要なデータ活用とは何か?データドリブン・マーケティングのロードマップを描く、またはそれを支援するためにマーケターの視野を広げるきっかけになればと思います。
2025年1月
目次





日本語で〇〇ドリブンと使われる場合は「〇〇に突き動かされた」という意味から転じて、「〇〇 を起点にした、〇〇をもとにした」と使われることが多いそうです。「 データドリブン・マーケティング」とは、その言葉から直訳すると「データを起点にしたマーケティング」「データを元にしたマーケティング」です。ネットで検索すると、「様々なデータを作成、収集、見える化、活用するPDCAを回していくことで、ビジネスを成長させる」「データから導いた示唆を元に実行に移す」 といった説明を目にします。データを元にアクション(マーケティング施策)を実際に行い、改善 するPDCAが前提となっており、それを回していく際の指標となるKPIとアクション(マーケティ ング施策の実行)は対になるものです(図1-1-1)。

マーク・ジェフリーは著書『データ・ドリブン・マーケティング 最低限知っておくべき15の指標』 で、米国での実例を元に「ブランド認知率」や「解約(離反)率」などのマーケティング業務にお ける重要な15の指標の活用の仕方について、具体的な例を用いて丁寧に紹介しています。マーケターがデータ分析によるPDCAを模索するためのヒントを得られる内容となっています。
【参照文献】マーク・ジェフリー(著)、佐藤順、矢倉純之介、内田彩香(共訳)『データ・ドリブン・マーケティング』ダイヤモンド社、2018年
マーケターの多くは売上数や売上金額、顧客調査によって導きだした「ブランド認知率」、Web マーケティングの「コンバージョン率」や「クリック率」など多様な指標を参照しています。テクノロジーの発展に伴い、より多くのデータが得られるようになったことで、多様な指標に翻弄され、 全体最適やイノベーションのための重要な意思決定を見失い、部分最適に陥っているマーケターや マーケティング組織を多く見かけます。 分析とは主に複雑な事象を細かく分けて見ていくことであり、分析の反意語は統合または総合です。重要な意思決定には、分析によって得た示唆を統合または総合する力が必要です。そうした力を養いましょう。 本書では、ECの集客などインターネットに限定した「Webマーケティング」など特定のマーケティング施策に対応する分析法ではなく、オフラインとオンラインの全てのチャネルにまたがる最適化に対応する分析法として、 マーケティング・ミックス・モデリング(以下「 MMM」)を中心にした演習で全体最適をテーマにしたノウハウを共有することを目指しました。

筆者はこれまで自身が講演したセミナーなどをきっかけに多くの経営者やマーケティング担当者と会い、データをどのように活用すべきかといった相談を受けてきました。データドリブンなマーケティングへの変革の必要性を感じているが、何から着手したら良いか分からないといった悩みを 多く聞きました。また企業でデータサイエンティストとして活躍する方は、経営者や責任者のデータ分析の理解不足についての課題が多い印象がありました。 「エクセル統計」を提供する社会情報サービス社(以降SSRI社)が2017年8月に実施した「社会人の方へ統計に関するアンケート」で「あなたは次にあげる用語をご存知ですか、おおよその意味が分かるものをすべて選択してください。(複数選択)」 という問いに対して「重回帰分析」を選択した方は1割に満たなかったそうです(図 1-2-1)。

重回帰分析は本書で紹介するMMMの分析にも用いている手法です。同アンケートに実際に使いこなしているか?という質問はありませんでしたが、おそらく5%前後だと思います(過去筆者が開催したセミナー参加者アンケート等をまとめた時、その程度でした)。マーケターのうち仮に重回帰分析をしている人が5%だとして、それを「データを扱える人」の基準とした場合、残り 95%の意思決定者または実行者が「データを扱えない人」では、日本のマーケティング組織が本質的な「データドリブン・マーケティング」を推進することは難しいと思います。データサイエンティストが有益な示唆を導いても、意思決定者または実行者がそれを理解して実行できなければ意味がありません。スペシャリストとしての「データサイエンティスト」の育成も大事ですが、今、それより大事なのは95%のマーケターの分析リテラシーの底上げをすることなのです。
コラム
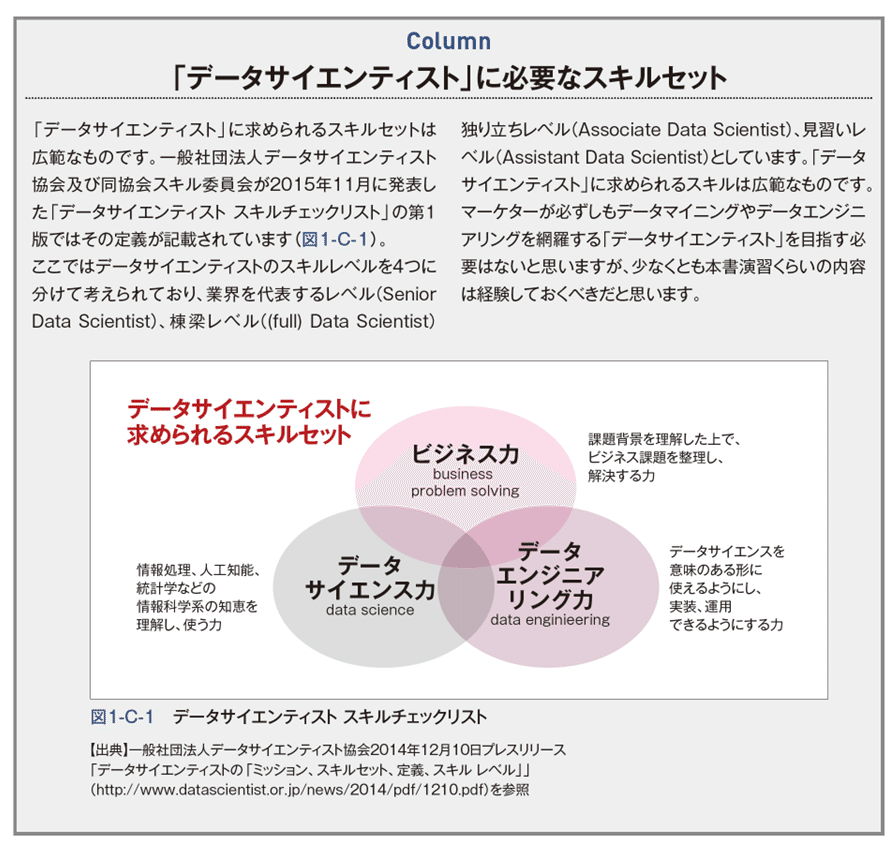

マーケティング施策の効果検証法は「準実験」と「MMM」の2種類に大別されます。それぞれ の手法の分析の元になるデータとして「シンジケートデータ」の活用も重要です。効果検証の精度 を高め、施策の真の投資対効果(ROI)を正確に把握することで、積極的なマーケティング投資を 行いブランドの成長軌道を描きやすくなりますが、適切な形でそれを行うことは容易ではありません。 「準実験」による効果検証は、日本のマーケティングの現場で最も良く行われています。例えば TVCMの効果を検証する際に、実施前後の調査で購買意向率の変化を調査して比較する、TVCM 接触者(介入群)と非接触者(対照群)の比較をするといったことです。介入群が仮にTVCMに接触していなかったらという反事実を対照群で代用し、その2つを比較することで効果に興味のある施策の介入効果を推定する方法です。最も確実な方法は介入群と対照群を施策介入以外の条件を 完全に同一な状態にして比較する実験です。そうした実験を「対照実験」といいます。対象者に介入を無作為に割り付けるランダム化比較実験が代表例です。医療分野で実験というと、多くの場合、 ランダム化比較実験のことを示します。治療対象者AB群のうち、Aには治療をするがBには治療をしない実験が倫理に反する場合や、多大な時間や手間がかかることなどから、ランダム化比較実験ができない状況は多いです。マーケティングの効果検証ではランダムに抽出したグループのうち一方にだけTVCMをリーチさせるといったことはできません。

マーケティング施策の効果検証を「対照実験」と呼べる状態で行われることはあまりないため、 そうした場合に消費者パネルからTVCMに接触した人としていない人を抽出し比較するなど、実験ではなく観察されたデータから対照実験と相応の状況を作り比較する方法が「準実験」です。「準 実験」は正しくデザインする必要がありますが、マーケティングの現場では明らかに比較してはい けない状態でそれを比較し、施策の効果(因果関係)を判断しているケースを多く目にします。 「MMM」は日本のマーケティングの現場の効果検証のスタンダードではありませんでしたが、 昨今、注目が高まり利用する企業が増えています。数理モデルや仮想現実のシミュレーションによっ て効果を定量化するものです。MMMは同時に実施している複数の施策の効果を定量化する時に 特に役立ちます。Webマーケティングの発展に伴い、課題となっているのはTVCMによるEC売上の増加効果などのクロスチャネルの効果把握です。例えばMMMによってオフラインチャネル(実店舗やコールセンター等)とオンラインチャネル(EC等)の売上をマーケティング施策などの要因によって説明する統計モデルを作り、施策の1単位を増やすと売上がいくら増えるか?それぞれの介入効果を推定し定量化することで、オンライン施策とオフラインの施策を横並びで評価することができ、TVCMによってECの売上がいくつ増えるかといったクロスチャネルの効果把握もできます(ただし、信頼できる統計モデルを構築できればという前提です)。時系列データ解析によるオンライン広告オンライン広告統合分析ツール「XICA magellan(サイカ マゼラン)」などのツールも普及してきて、MMMはだんだんと浸透してきました。しかし、マーケター全体の統計リテラシーが低いため、外部専門家または社内のデータサイエンティストが高度な分析を行っても、意思決定者の理解が得られず、分析結果が実行に落ちないケースもあったと思います。

コラム
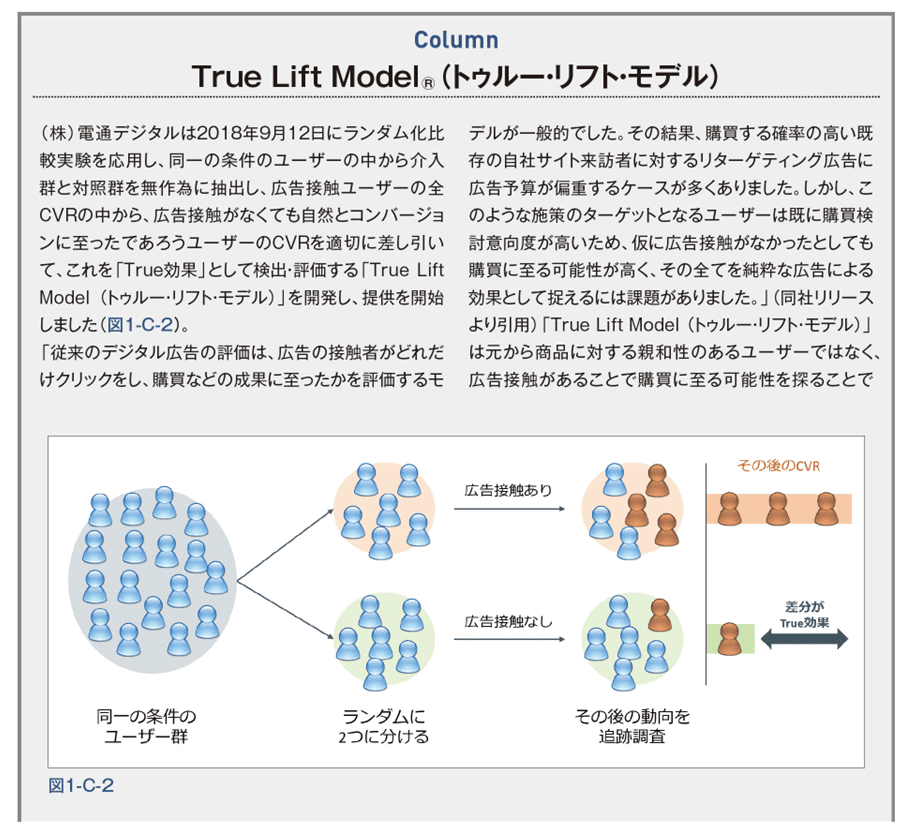


TVCMの放映前後でアンケート調査を行い、購入意向率などの差分を比較する方法はマーケティ ングの現場で良く用いられています。(中室、津川:2017)は共著『原因と結果の経済学』で単純 に広告を出す前後で結果を比較する手法を「前後比較デザイン」といい、時間とともに起こる自然 な変化(トレンド)の影響を考慮することができないことや、平均への回帰を理由にあげ、広告と 売上の因果関係を明らかにすることはできないことについて指摘しています。同書ではそれを改良 するために介入群と対照群のそれぞれにおいて、施策の実施前後の2つのタイミングのデータを入 手して分析する「差分の差分法」や、因果推論を行うべき結果に対して直接の影響はないが、原因 に対しては影響があり、間接的に結果に影響を与える第3の変数を用いた「操作変数法」、介入群 によく似たペアを対照群の中から選びだすことによって2つのグループを比較可能なものとする 「マッチング法」、観測可能な変数がある閾値を超えたときにその閾値前後でのYの不連続的な変 化の大きさから介入効果を推定する「回帰不連続デザイン」、本書で紹介するMMMに用いる「回帰分析」など因果推論を行うために必要な様々な分析法を紹介しています。 「差分の差分法」を用いてTVCM実施前後で興味のある指標を比較して介入効果を推定する場合はTVCM接触者グループ(介入群)とTVCM非接触者グループ(対照群)それぞれの実施前後の指標(認知率や購入意向率等)を比較します。図1-3-1のケースでは、介入群の実施後の増加分5%から、対照群の増加分2%を引いた3%の増加をTVCMの介入効果と考えます。

「差分の差分法」では介入群に対して介入が行われなかったケースを仮想したBからAを引いた 値がDからCを引いた値と一致する「平行トレンド仮定」を満たすように、介入群と対照群を設定する必要があります。 介入群と対照群を比較可能にするために行う調整法のひとつが「マッチング法」です。例えば、 健康食品の広告を健康雑誌に出した際に購入意向への介入効果を推定するケースにおいて、アンケートの広告閲覧有無で介入群と対照群に分けた場合、健康意識の高い人ほど健康雑誌の閲読率が高く当該広告に接触しやすいため、介入群は健康意識が高い方に偏ることが考えられます。こうした時に介入群の購入意向率が15%で対照群の購入意向率が5%だった場合、その差分10%が雑誌広告の介入効果とは言えません。介入群に健康意識の高い人が多く含まれることが健康食品の購入意向率を押し上げている可能性が考えられるためです。こうした状況で介入群と対照群の偏りを補正して比較可能な状態にする方法がマッチング法です。その手段のひとつとなる「傾向スコアマッチング」は、ロジスティック回帰などの統計解析でそれぞれの標本が介入群に割り付けられる可能性を「傾向スコア」として数値化し、その値を元に介入群の標本と似た標本を対照群の中から選びだしペアを作りマッチングしていくことで介入群と対照群の偏りを補正するものです。
また、介入群と対照群の偏りが健康意識だけの場合はそれが高い人と低い人を分けた層別分析で も比較可能なものとできます。準実験を行う際は適切な実験デザインが必要ですが、マーケティングの現場では本来比較してはいけない介入群と対照群の差分から介入効果を推定しているケースを 多く見かけます。因果推論の基礎や準実験のデザインをマーケターの共通言語にしていくため、ぜ ひ参照文献を読んで頂ければと思います。因果推論の基礎について知ることができます。巷に流れ るニュースや政策、マーケティングで行っていた意思決定などについて見直す機会になると思いま す。もう一冊参考文献として『データサイエンス「超」入門 嘘をウソと見抜けなければ、データ を扱うのは難しい』を紹介します。巷にあふれるニュースやウェブ検索でヒットする情報や専門家 の論考など、データの読み解き方について間違えたものが多いことについて指摘し、データに注目 し(因果推論に限らず)「嘘を見抜く技術」を紹介するデータサイエンス入門書です。『原因と結果の経済学』と『データサイエンス「超」入門 嘘をウソと見抜けなければ、データを扱うのは難しい』はマーケターに重要な気づきを与えてくれるでしょう。
【参照URL】統計WEB ブログ「層別分析とは」(https://bellcurve.jp/statistics/blog/14333.html)
【参照文献】中室牧子、津川友介(著)『原因と結果の経済学』ダイヤモンド社、2017年
松本健太郎(著)『データサイエンス「超」入門 嘘をウソと見抜けなければ、データを扱うのは難しい』毎日新聞出版、2018年

売上の変化を見る時やTVCMの接触と購買への影響などを把握するためのデータとして、シングルソースパネルの活用を推奨します※。 これは同一の調査対象者から、購買・広告接触・ライフスタイルなどの多面的情報を採取したデータのことを指します。例えばインテージ社のシングルソースパネルではPC、モバイル、TVなどのメディア接触ログ、属性/意識・実態のアンケート回答と消費財の購買履歴ログを収集していま す。これらを活用することで、例えば、TVCM放映後にアンケートで「商品Aを買いましたか?」 と聞かなくても、同モニターのうち広告接触者と非接触者の購買率の差分を比較することなどが可能となります。


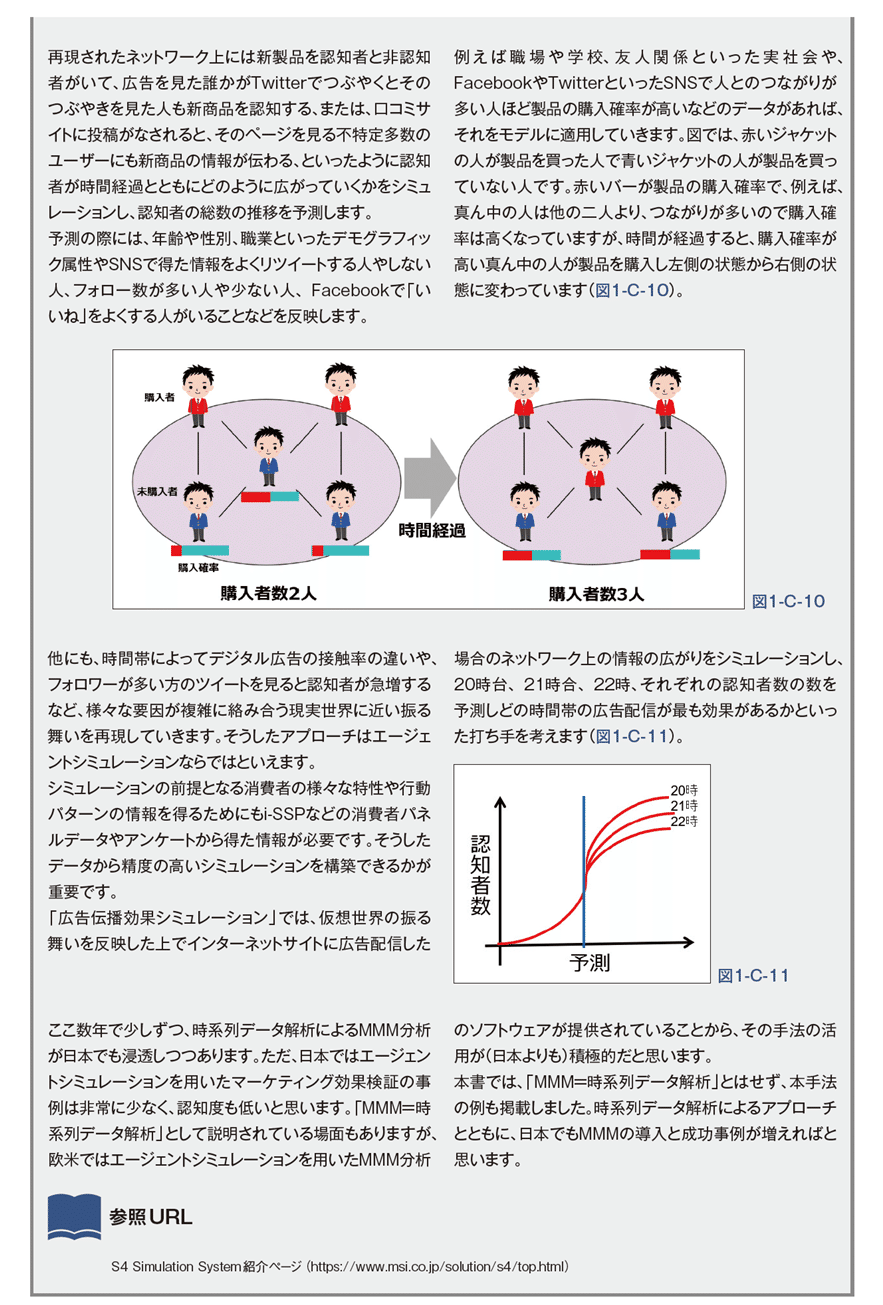
MMMは数理モデルや仮想現実のシミュレーションによって効果を定量化するものだと説明しましたが、もう少しかみ砕くと「マーケティングゴールとなる商品購買などへの影響を、同時に複数実施されているマーケティング施策やその他の要因を用いて(数理モデルなどを用いて)モデル化して説明することで、施策ごとの介入効果を推定し、効果の最大化といった最適化試算に落とし込む分析手法の総称」です。 日本では「MMM=時系列データ解析」と説明されることが多いのですが、エージェントシミュレーションという高度な手法も、欧米ではよく用いられています(欧米製でそうした分析を行うソフトがいくつか提供されています)。エージェントシミュレーションでは、現実で得られた消費者行動特性をルール化し、それを元にしたエージェント(消費者)の行動を仮想空間上で再現するモデルを作ります。日本製ではNTTデータ数理システムが提供する「S4 Simulation System(エスクワトロシミュレーションシステム) ※」を用いてマーケティングの分析に活用した事例があります。 本書で紹介するMMMはエージェントシミュレーションではなく、時系列データ解析によって行うものです。目的変数を説明変数で説明する予測式を作る「モデリング」と、予測式を元に売上等の効果を最大化または同一の効果数で予算を最小化するといった「予算配分最適化シミュレー ション」がセットになります(図1-3-2)。


モデル化の方法(統計解析アルゴリズム)については、ひとつ決まったものがあるわけではなく、いくつかの方法が用いられています。本書で紹介するのは回帰分析を用いた方法です。 回帰分析を簡単に説明すると、説明変数Xによって、目的変数Yの変動をどれくらい説明できるのかを分析する手法です。説明変数が複数になる場合は重回帰分析、説明変数がひとつの場合は単回帰分析となります。図1-3-3の表は、TVCMの出稿量と売上金額の関係を示したものです(架空の事例です)。

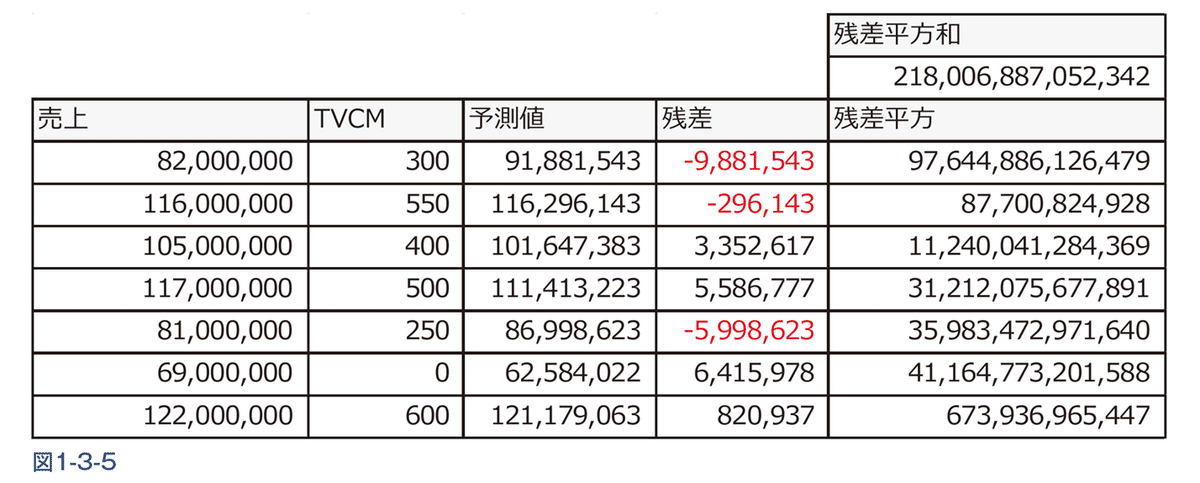
目的変数Yを売上として、説明変数XをTVCMの出稿量としてそれをY=aX+bで説明するためのaとbの値を求めます。aが説明変数の係数(正確には「回帰係数」)bを切片と言います※。 このデータを回帰分析するとY=103746X+59465564(※小数点以下は切り捨て)となり、aとbが求められます(図1-3-4)。aはこのグラフの右斜め上に伸びる直線(これを回帰直線)の傾きを示し、bは緑色の線の部分となります。

aとbを求める際には図中に赤い矢印で示した予測値と実績値の差(これを「残差」といいます) を最小化することを目的にした計算を行い、TVCMの出稿量Xによって売上Yを予測できる状態を作ります。残差は非負数(プラスの値)と負数(マイナスの値)があるため、残差の二乗(残差 平方)を算出し、全てを非負数にしてその値を合計した「残差平方和」を「最小化」する計算を行うのが回帰分析です(図1-3-5)。
回帰分析を用いたMMMでは、TVCMだけでなく、新聞広告やデジタル広告など、複数の説明変数を用いた重回帰分析によって売上個数を説明する方程式を作り、導いた偏回帰係数によって、 それぞれの施策の一定単位を増やすと売上等にどれだけ影響するか(介入効果)を推定し、定量化します(図1-3-6)。

例えば、実店舗での売上が主となっている企業が、FacebookなどのSNSのファンページや運用型広告を活用する例を考えます。一般的には実店舗への影響数が分からないために、Webマーケティング指標となるリーチ人数やインプレッション数などをKPI として用いている場合が多いと思います。
しかし、MMM によって介入効果を定量化することができれば、投稿リーチ1 人あたり、またはインプレッション1 回あたりで店舗売上が〇個または〇円増えるといった新たな指標を得ることができます。これは、TVCMなどのマス広告やLINEや動画広告などの他の施策についても同様です。各施策の投下コストや視聴率、メッセージ開封数や再生数などの1単位あたりでどれだけ店舗売上が増えるという新たな指標を得ることができます。今まで用いていたリーチやインプレッションといった指標がより有益なものに変わるはずです。MMMを活用することで、実店舗などのオフラインの顧客接点が主要なチャネルとなっている企業は、Online(施策)to Offline(売上)やOffline(施策)to Offline(売上)で効果を定量化して把握し最適化できます。オンラインが主要なチャネルとなっている企業では、TVCMなどのオフライン媒体に投資をしている際にOffline(施策)to Online(売上)の効果を定量化できます。昨今マーケターの間で「デジタルシフト」が騒がれていますが、日本はいまだ実店舗などのオフラインチャネルでの取引が主たるもの(9割以上)となっています※。多くの企業がWebマーケティング指標と向き合いOnline(施策) to Online(売上)のデータ分析や最適化に多くのリソースを割いている反面、クロスチャネルでの効果把握など、全体最適のための分析アプローチができている企業はまだまだ少数派です。多くの企業がWebマーケティングの部分最適に対してリソース過多となっているため、全体最適に目を向けるための手法としてMMM を活用していただければと思います。


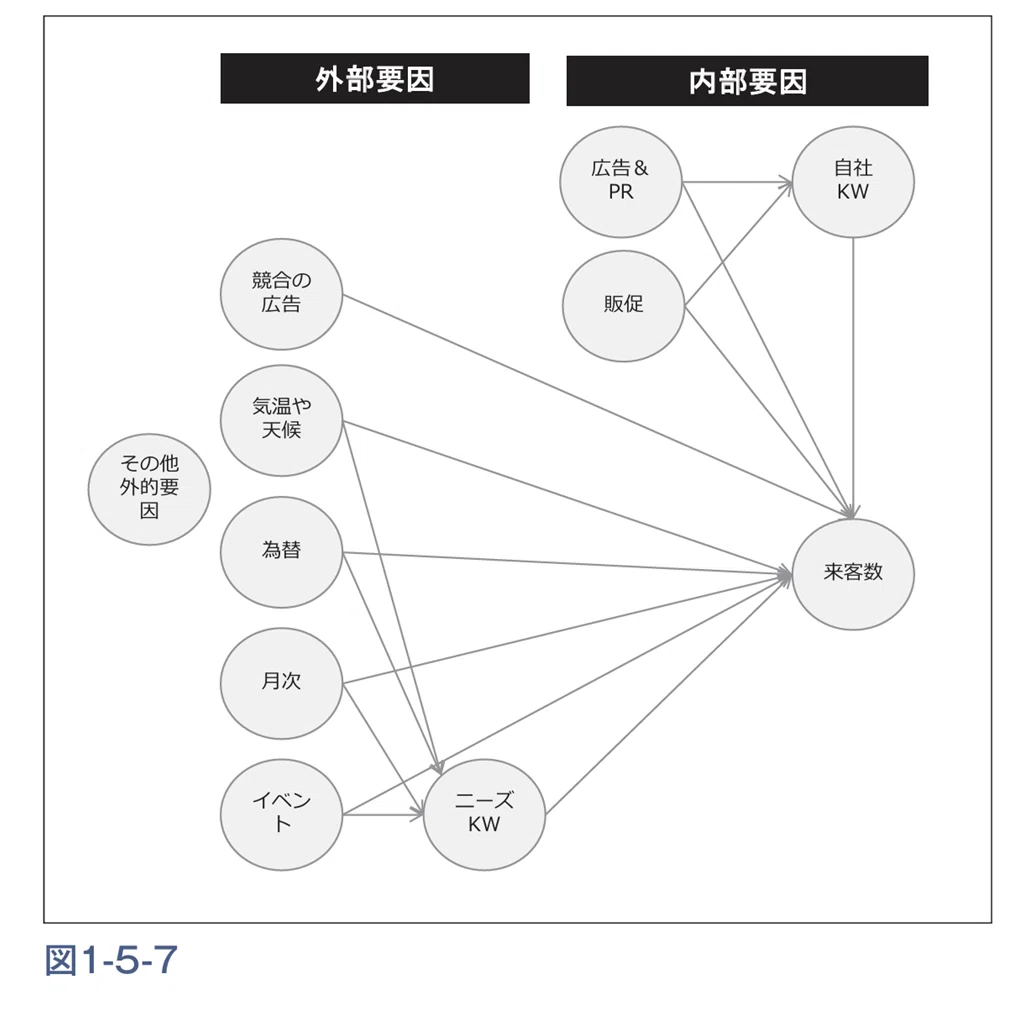
時系列データ解析で自社の商品やサービスの売上を説明するモデルを作る際、その要因となるプロモーション施策(TVCMなど)の変数を作る際にはTVCMの視聴率や各媒体の推定接触人数など、各施策の影響を象徴するデータを取得する必要があります。それらの多くはシンジケートデータとなります。MMMにおいてシンジケートデータの活用は必須と言えます。また競合企業のKGIまたはKPIとなるデータも取得できれば、それを用いて競合もMMMで分析し自社と効果を比較することができます※。 本節で紹介した内容を整理したものが図1-3-7です。

コラム




この節では「データマイニング」の分類やデータセットの種類についての基礎知識を紹介しておきます。

データマイニングは広範な概念であり、使われる場面に応じて多様な意味で用いられています。
が、主に用いられるのはその言葉が示す通り「データから有益な情報を採掘(マイニング)すること」です。データマイニングを「統計解析」と「機械学習」と、目的変数の有無で4タイプに分類し、うちエクセル統計で分析可能な分析を赤字で記載、さらに本書演習で行う分析を(太字+ 下線)で記載しました(図1-4-1)。

目的変数がある分析とは、「気温が上がる(原因)」と「海水浴客が増える(結果)」など、原因に対応する変数と結果に対応する変数がある分析です。予測または原因となっている変数の一定数を増やすと結果となっている変数が一定数増加する介入効果の推定が主な目的となります。対して目的変数がない分析では、クラスター分析のように分析対象となる標本を分類する、変数の関係を明確化することが主な目的となります。
【参照URL】統計WEB 統計学の時間「説明変数と目的変数」(https://bellcurve.jp/statistics/course/1590.html)
「統計解析」と比較し「機械学習」は新しいジャンルです。機械学習とは「明示的にプログラミングすることなく,コンピューターに学ぶ能力を与えようとする研究分野(A.L.Samuel[1959])」です。マーケティングのデータマイニングで用いられる機械学習は、主に人間では対応できない膨大・複雑なデータから知識の候補や仮説の導出をすることに期待されています。次に、データマイニングにおける「統計解析(ここでは主に多変量解析)」と「機械学習」それぞれの分類について説明します。

多変量解析とは、多数のデータ(変数)間の相互の関係性をとらえるために使われる統計的手法の総称です。主に因果推論または予測に用いられる「目的変数有り」の分析手法と、主にデータの分類・要約に用いられる「目的変数なし」の分析手法に分かれます(図1-4-2)

更に、扱うデータ(変数)には質的変数と量的変数の区別があり、どちらを扱うかによって分析の手法が変わります。質的変数とは、データがカテゴリーで示されるものです。名前の通り、データ間の「質」が違う変数です。例としては、性別や血液型などです。さらに質的変数はデータを評価する基準(これを尺度と呼ぶ)によって名義尺度と順序尺度に分類されます。対して量的変数は名前の通り、データの「量(数値)」が基準となるものです。例としては、気温や速度などがこれに相応し、さらに間隔尺度と比例尺度に分類されます(図1-4-3)。

見分けづらいのは「 間隔尺度」と「 比例尺度」です。「この2つの尺度を見分けるコツは、「0 の値に意味があるかどうか」を考えることです。温度や西暦は「0」だったとしても、その温度や西暦が「無い」わけではありません。一方で、身長や速度が「0」であるときは、本当に「無い」ときです。」(統計WEB「変数の尺度」より引用)比例尺度における「0」は絶対的な意味を持ち、間隔尺度における「0」は相対的な意味となります。
扱うデータ(変数)が質的データか量的データかという区別と目的変数の有無を掛け合わせて多変量解析の手法を分類した表が図1-4-4 です。

【参照URL】統計WEB 「変数の尺度」(https://bellcurve.jp/statistics/course/1562.html)

機械学習は主に「教師あり学習」「教師なし学習」「強化学習」の3つに分類されます。「教師あり」と「教師なし」は多変量解析の目的変数の有無と対応しています。「教師あり学習」は、入力に対してあらかじめ正解がわかっている場合に、正解を導くパターンやルールを学習する手法です。ここでいう「教師」というのは、正解データのことです。顧客の購買ログなどのデータセットを樹木上のモデルを使って分類することで、「教師なし学習」は、正解のないデータから類似グループをまとめたり、重要な特徴を重要な特徴を抽出したりする学習方法です。「強化学習」は、コンピューターが自ら試行錯誤しながら最適な戦略を学習する手法です。」(韮原,2018)
【参照文献】韮原祐介(著)『いちばんやさしい機械学習プロジェクトの教本』インプレス社、2018年
「教師あり学習」は特定の商品の購買など、なんらかの結果に与えた要因を把握または分類する「決定木」分析や、予測に必要な一部のデータのみを用いて回帰や分類を行う「サポートベクトルマシン」などがあります。「教師なし学習」はクラスタリングや、A商品を購入している人はB商品も買う定木」分析や、予測に必要な一部のデータのみを用いて回帰や分類を行う「サポートベクトルマシン」などがあります。「教師なし学習」はクラスタリングや、商品を購入している人はB商品も買う傾向があるといった関連(英語でassociation)を分析するアソシエーション分析などがあります。「強化学習」はMMMにも応用されるエージェントベースシミュレーションなどがあります。

時間を一時点に固定して止め、その時点で区切ってデータを記録したものを 横断面データ(cross section data) といいます。これに対し「一つの項目について」時間に従って取ったデータを時系列データ( time series data) といいます。それを一定の間隔で取得して時系列データ的な側面もあるデータをパネル・データ( panel data) といいます(図1-4-5)。

生まれた年ごとに記録し、経過時間に沿って集計したデータをコーホートデータ(cohortdata) といいます(図1-4-6)。主に、同じ時期に生まれた人の生活様式や、行動、意識などからくる消費動向を分析する際に用いられるものです(その分析を「 コーホート分析」と言います)


以上が、「データセットの種類」です。マーケティングの現場ではリサーチの対象者のことを「パネル」と言うため、モニターの回答データのことを示す用語として「パネル・データ」という言葉が使われる場合がありますが、本来の「パネル・データ」の意味はここで紹介したものです。MMMの分析で用いるデータは、複数項目の時系列データなので「データセットの種類」の本来の意味からはパネル・データとなりますが、統計解析ソフトウェアなどでは時系列データとして扱うことが多くなります。統計解析において重要なのは分析の際に「 データの順番に意味があるかないか」です。統計解析ソフトなどでデータを扱う場合は、順番に意味があれば「time series
data」として扱い、そうでない場合は「cross section data」として扱われます。time series data(時系列データ)として扱う場合は、分析時に特殊な作法が必要になる場合があることを覚えておいてください。


第1章の最後に、本書の演習内容と構成をまとめておきます。

第2章では、かつて筆者が所属していたカーツメディアワークスのように企業のマーケティングを支援する会社のホームページに来る問い合わせをイメージした架空のデータをcross section data として扱います。どういった属性の顧客が契約に至りやすいか?クロス集計と数量化2類による分析を体験していきます(数量化2類の分析実行時にクロス集計が行われるのでその内容も参照)。そこで見出した傾向がただのバラつきや誤差で生じたものではないか?を確認するための独立性の検定も体験します。クラスター分析の演習では探索的に顧客の傾向を把握していきます。


第3章〜第4章では、(架空の)アルコール飲料の売上数や広告出稿量などのマーケティング施策の量的データを主に用いて、それをtime series data として扱うMMM 分析の準備を行います。分析に用いるデータの分布などの状態を把握していく手順を理解します。第3章では、Excel の「分析ツール」を使ってデータの確認を行うための折れ線グラフやヒストグラムの量的データを主に用いて、それをtime series data として扱うMMM 分析の準備を行います。分析に用いるデータの分布などの状態を把握していく手順を理解します。第3章では、Excelの分析ツール」を使ってデータの確認を行うための折れ線グラフやヒストグラムの作り方や基本統計量の見方を知る演習と相関係数を把握する演習を行います。複数の変数の影響を考慮する偏相関係数と季節性を月別の指数として把握する期別平均法をエクセル統計で体験します。


回帰分析はどのようにして行っていくのか?Excelの分析ツールを用いた演習で基本的な操作方法と、推定結果で出力される決定係数やP値などの指標の内容を把握します。月次の季節性を考慮するための「ダミー変数」の作り方についても演習します。Excel 単体の機能で行う方法とエクセル統計のユーティリティ機能の体験の双方を行います。


【MMM_modeling】Book を使用し、マクロを用いて回帰分析の実行作業を効率化し、ソルバーを用いて、残存効果やマーケティング施策の投下量に応じて効果の増分が逓減する非線形な影響を考慮することで、予測精度の高いモデルを探索する手順を演習します。さらにモデル探索の効率を上げる「エクセル統計」の重回帰分析の「説明変数選択機能」も体験します。その後で残存効果や非線形な影響を加味する計算とはどのようなものか? (Excel 標準の)ソルバーとはどんなものか?追加の演習で理解していきます。
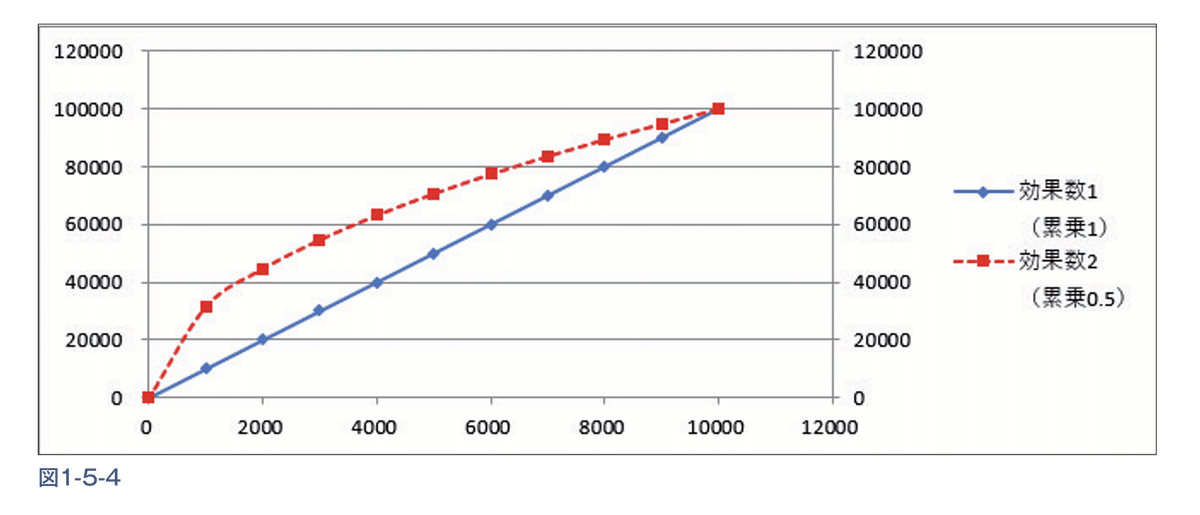

第5章の演習で作った予測モデルによって得た値を【MMM_modeling】Book で集計し、それを試算用に使用する【MMM_simulation】Book に転記します。各週の投下予算をX軸に、目的変数への影響数をY軸にプロットするグラフで、各マーケティング施策の効果予測をプロットして横並びで把握し、ソルバーを使って売上数を最大化するための予算配分のシミュレーションを行う演習を行います。Webプロモーションについては各週の投下量を増やすと、単価が上がる傾向といった前提を試算時に加味して補正する方法を演習します。第3章で簡易的に行っていたデータ分布の確認から踏み込んで「外れ値」をエクセル統計の「箱ひげ図」によって作成する体験をして、
外れ値が分析結果にもたらすバイアスとはどういったものか?演習で体験します。ある施策の過去実施投下量を大きく上回る変更をした際に、(過去データを元にした)分析結果の効果予測通りになるか?といった留意事項に対しても共有します。


(架空の)通販企業の例を用いた演習です。ダイレクトレスポンス型広告の既存の方法(オンライン、オフラインそれぞれの媒体の獲得単価による最適化)を紹介した上で、クロスチャネルの効果把握を行う視点について解説します。オフライン(コールセンター)とオンライン(EC)の双方への申込数を予測するモデルを作り、2つのモデルから効果数または利益を最大化するためのマーケティング施策予算配分のシミュレーションの演習を行います。


この章では演習によってデータ分析手段を理解した上で、MMMで必要なモデル選択視点を確認します。「まずはやってみる」方針をとったため、第3章~第7章までの演習で省略した解説のうち、主にMMMの説明変数選択やモデル選択視点のために必要な考察を行うための統計的因果推論の知識について簡単に解説します。分析の軸足をマーケティング施策の介入効果の推定(説明)に置くか?あるいは売上などのマーケティング目的となる変数の未来予測(予測)に置くか?によって変わる説明変数選択の選定と候補変数を洗い出す視点を共有した上で、最後に、本書で紹介してきた推定結果にバイアスをかけてしまう、または信頼できなくなる落とし穴となる事項について一覧でおさらいします。

2つの演習を行います。1つ目は、Excel2016に加わった時系列データの「予測ツール」を用いて「コート」の検索数を予測する方法です。2つ目は回帰分析を時系列データに適用する際に起こり得る「見せかけの回帰」という症状を避けるための方法の1つとなる「単位根検定」という検定です。

注意事項

コラム

2025年2月13日公開(日経クロストレンド)
スーパードライ66億円、黒ラベル22億円 テレビCMの売上貢献をMMMで検証:日経クロストレンド(この記事は2025年2月15日 6:34まで無料登録せずに読めます)
その他告知(※適宜更新)
消費者調査MMM(R)で確認する「購買重複の法則」noteを集めたマガジンです。現在は5つのnoteを紹介しています。
刀社と弊社の特許技術の明細書を要約したnoteです。
2月20日(木)16時からエバンジェリストをしているFreeasyのセミナーで、消費者調査MMM(R)の事例をいくつか紹介します。
3月25日にはCEPs(カテゴリーエントリーポイント)の見出し方というセミナーに登壇します。